- 入门教程
- Series教程
- DataFrame教程
- Operation教程
- Data Operations教程
- 索引教程
- Time Series教程
 《Pandas入门教程》
《Pandas入门教程》 关注我们

DataFrame.sample函数

Pandas sample()用于从DataFrame中随机选择行和列。如果要从大量数据集构建模型,则必须随机选择通过函数 sample 完成的较小数据样本。
语法
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
参数
- n - 这是一个可选参数,由整数值组成,用于定义所生成的随机行的数量。
- frac - 这也是一个可选参数,由浮点值组成,并返回浮点值*数据帧值的长度。不能与参数n一起使用。
- replace - 它由布尔值组成。如果为true,则返回带有替换的样本。替换的默认值为false。
- weights - 它也是一个可选参数,由类似于str或ndarray的参数组成。默认值" None"。
- random_state - 它也是一个可选参数,由整数或numpy.random.RandomState组成。
- axis - 这也是一个可选参数,由整数或字符串值组成。 0或" 行"和1或"列"。
返回值
它返回与调用者相同类型的新对象,其中包含从调用者对象中随机采样的n个项目。
例1
import pandas as pd info = pd.DataFrame({'data1': [2, 4, 8, 0], 'data2': [2, 0, 0, 0], 'data3': [10, 2, 1, 8]}, index=['John', 'Parker', 'Learnfk', 'William']) info info['data1'].sample(n=3, random_state=1) info.sample(frac=0.5, replace=True, random_state=1) info.sample(n=2, weights='data3', random_state=1)
输出
data1 data2 data3 John 2 2 10 William 0 0 8
例2
在此示例中,获取一个csv文件,并使用示例从DataFrame中提取随机行。
名为 aa 的csv文件,其中包含以下数据集:
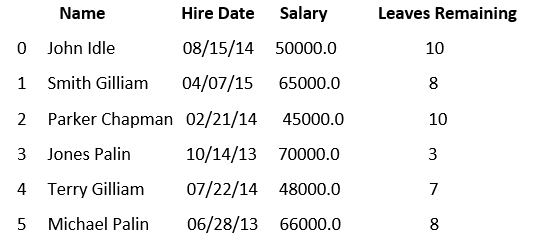
让无涯教程编写一个代码,从上述数据集中提取随机行:
# importing pandas package import pandas as pd # 从 csv 文件定义数据框 data = pd.read_csv("aa.csv") # 随机选择一行 row1 = data.sample(n = 1) # 显示行 row1 # 随机选择另一行 row2 = data.sample(n = 2) # 显示行 row2
输出
Name Hire Date Salary Leaves Remaining 2 Parker Chapman 02/21/14 45000.0 10 5 Michael Palin 06/28/13 66000.0 8
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)
好记忆不如烂笔头。留下您的足迹吧 :)