- Python 渗透测试基础知识
- Python 渗透测试实用指南
 PDF电子书集合
PDF电子书集合
Python 概念处理详解
本章将让我们熟悉 Python 中的各种面向对象概念。我们将看到 Python 不仅可以用作脚本语言,而且还支持广泛的面向对象原则,因此可以用于设计可重用和可伸缩的软件组件。除此之外,我们还将探讨正则表达式、文件和其他基于 I/O 的访问,包括 JSON、CSV 和 XML。最后,我们将讨论异常处理。本章将介绍以下主题:
任何编程语言的面向对象特性都教会我们如何处理类和对象。Python 也是如此。我们将介绍的面向对象的一般特性如下:
- 类和对象
- 类关系:继承、组合、关联和聚合
- 抽象类
- 多态性
- 静态、实例和类方法和变量
一个类可以被认为是一个模板或蓝图,其中包含方法的定义以及与该类对象一起使用的变量。对象只是类的一个实例,它包含实际值而不是变量。类也可以定义为对象的集合。
简单来说,类是变量和方法的集合。这些方法实际上定义了类执行的行为或操作,变量是执行操作的实体。在 Python 中,类是用 class 关键字声明的,后跟类名。下面的示例演示如何声明基本 employee 类,以及一些方法和操作。让我们创建一个名为Classes.py的 Python 脚本:
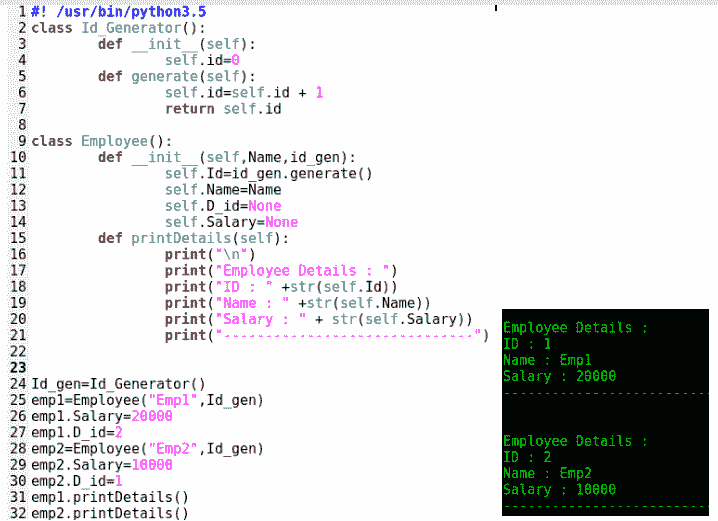
以下要点解释了上述代码及其结构:
-
class Id_Generator():为了用 Python 声明一个类,我们需要将它与 class 关键字相关联,这是我们在代码第 2 行中所做的。任何以相等缩进进行的操作都构成Id_Generator类的一部分。此类的目的是为创建的每个新员工生成一个员工 ID。它通过generate()方法来实现这一点。 -
def __init__(self):Python 或任何其他编程语言中的每个类都有一个构造函数。这可以是显式声明的,也可以是未声明的,默认构造函数是隐式的。如果你来自 java 或 C++的背景,你可能会使用构造函数的名字和类名相同,但情况并非总是如此。在 Python 中,类构造函数方法是使用__init__字定义的,它总是以self为参数。 -
self:self类似于关键字。Python 中的self表示类的当前实例,在 Python 中,作为实例方法的每个类方法都必须将 self 作为其第一个参数。这也适用于构造函数。应该注意的是,在调用 instance 方法时,我们不需要显式地将类的实例作为参数传递;Python 隐式地为我们解决了这一问题。任何实例级变量都必须使用self关键字声明。这可以在构造函数中看到,我们已将实例变量 ID 声明为self.id,并将其初始化为0。 -
def generate(self):generate是一个实例方法,增加 ID 并返回增加的 ID。 -
class Employee():employee类是一个使用构造函数创建员工的类。它使用printDetails方法打印员工的详细信息。 -
def __init__(self,Name,id_gen):构造函数可以有参数化和非参数化两种。任何接受参数的构造函数都是参数化构造函数。在这里,employee类的构造函数是参数化的,因为它需要两个参数:要创建的员工的名称和Id_Generator类的实例。在这个方法中,我们只调用Id_Generator类的 generate 方法,该方法返回员工 ID。构造函数还初始化传递给self类实例变量name的员工名称。它还将其他变量D_id和Salary初始化为None -
def printDetails(self):打印员工详细信息的方式。 - 第 24-32 行:在代码的这一部分中,我们首先创建
Id_Generator类的实例,并将其命名为Id_gen。然后,我们创建一个Employee类的实例。请记住,类的构造函数是在创建类实例时调用的。由于在本例中构造函数是参数化的,因此我们必须创建一个实例,该实例包含两个参数,第一个参数是员工姓名,第二个参数是Id_Generator类的实例。这是我们在第 25 行中所做的:emp1=Employee('Emp1',Id_gen)。如前所述,我们不需要明确通过self;Python 隐式地处理了这个问题。之后,我们为Emp1实例的 employee 类的Salary和D_id实例变量赋值。我们还创建了另一个名为Emp2的员工,如第 28 行所示。最后,我们通过调用emp1.printDetails()和emp2.printDetails()打印两名员工的详细信息。
面向对象编程语言的最大优点之一是代码重用。这种可重用性是由类之间存在的关系提供支持的。面向对象编程通常支持四种类型的关系:继承、关联、组合和聚合。所有这些关系都基于is-a、has-a和中的部分关系。
类继承是一个特性,我们可以通过重用另一个类的功能来扩展一个类的功能。继承极大地促进了代码重用。举一个简单的继承示例,假设我们有一个Car类。车辆类别的一般属性为category(如 SUV、运动型、轿车或掀背车)、mileage、capacity和brand。现在让我们假设我们有另一个名为Ferrari的类,它除了正常的汽车特性外,还具有特定于跑车的其他特性,例如Horsepower、Topspeed、Acceleration和PowerOutput。在这种情况下,我们必须在两个类之间使用继承关系。这种类型的关系是子类和基类之间的is-a关系。我们知道法拉利是一辆汽车。在本例中,汽车是基类,法拉利是从父类继承通用汽车属性并具有自身扩展特性的子类。让我们扩展前面讨论的示例,在这里我们创建了一个Employee类。现在我们将创建另一个名为Programmer的类,看看如何在这两个类之间建立继承关系:
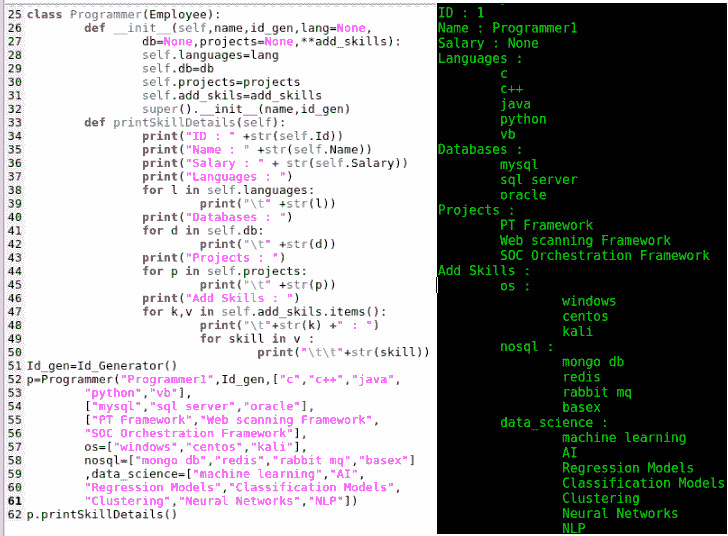
以下要点解释了上述代码及其结构:
-
Class Programmer(Employee):在前面的例子中,我们创建了另一个名为Programmer的类,该类继承自Employee基类。Programmer和Employee之间存在和关系。除了Employee类的所有变量和方法外,Programmer类还定义了一些自己的变量和方法,如语言、数据库、项目和其他技能。 -
`def init(self,name,id_gen,lang,db,projects,add_skills)
**:Programmer类的init方法采用了一些自解释的参数。注意对(Employee类)super().init()`超类构造函数的调用,它位于第 32 行。在其他高级语言如 java 和 C++中,我们知道基类或超类构造函数是从子类构造函数自动调用的,并且这是第一个语句,当未指定时,它将隐式地从子类构造函数执行。Python 并非如此。基类构造函数不会从子类构造函数隐式调用,我们必须使用 super 关键字显式调用它,如第 32 行所示。 -
def printSkillDetails(self):这是帮助我们探索传承力量的方法。我们在这个方法中使用基类变量(iD、name和salary,以及一些特定于Programmer类的变量。这说明了如何使用继承来重用代码,并派生出一个是关系。 - 第 52-62 行:最后,我们创建一个
Programmer类的实例并调用printSkillDetails方法。
在 Python 中,我们没有与爪哇和 C++相同的访问修饰符。但是,有一个部分解决方法,可用于指示哪些变量是public、protected和private。一词表示在这里很重要;Python 不阻止使用受保护的或私有的成员,它只是指示哪些成员是哪些成员。让我们来看一个例子。创建一个名为AccessSpecifiers.py的类:
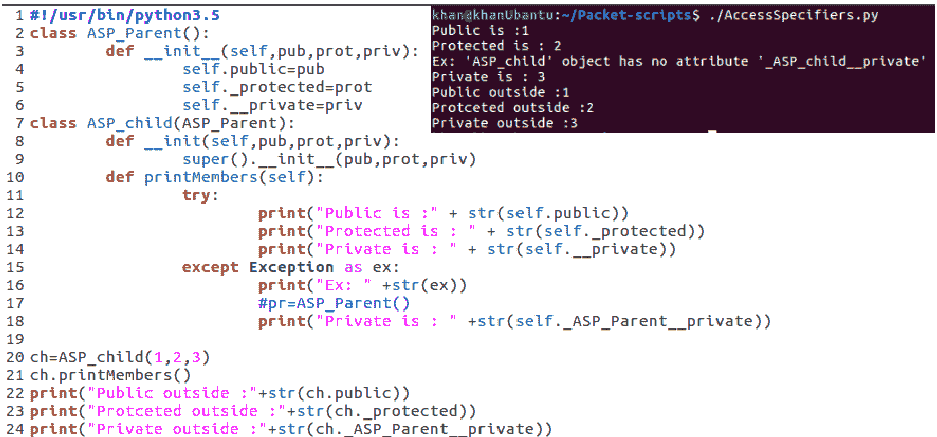
前面的示例向我们展示了如何在 Python 中使用访问说明符。任何在类中简单声明的变量在默认情况下都是公共的,正如我们声明的self.public。Python 中的受保护变量是通过在它们前面加下划线(_)来声明的,如第 5 行self._protected所示。但必须注意的是,这并不妨碍任何人使用它们,如第 23 行所示,在该行中,我们使用的是类外的受保护成员。Python 中的私有成员是通过在它们前面加上双下划线(__)来声明的,如第 6 行self.__private所示。然而,同样,没有什么可以阻止这个成员在类之外使用。然而,访问它们的方式有点不同;对于私有成员,如果要在类之外访问它们,则遵循特定约定:instance._<className><memberName>。这就是所谓的名称混乱。
关于 Python 中的访问修饰符,我们在这里学到的是,Python 确实有表示类的公共、私有和受保护成员的符号,但它没有任何方法让成员在其作用域之外使用,因此它仅用于标识目的。
OOP 中的组合表示类之间关系的部分。在这种关系中,一个类是另一个类的一部分。让我们来看看下面的例子,如 To.T0},了解类之间的组成关系:
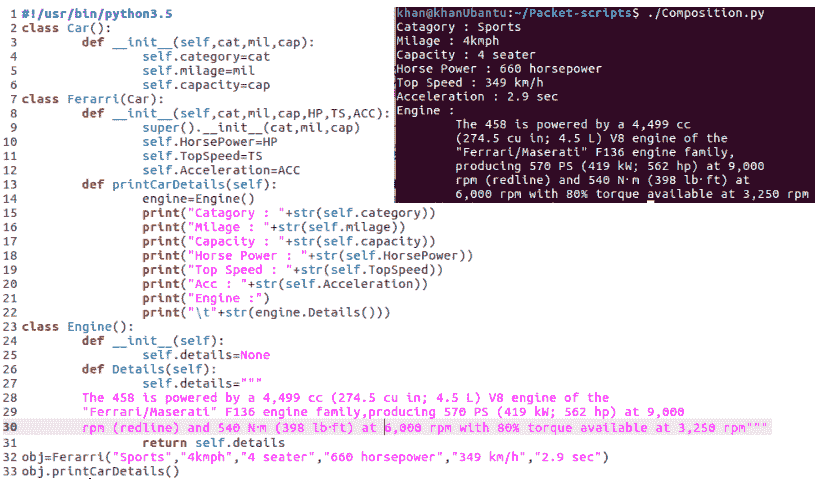
在前面的例子中,法拉利汽车和发动机之间的关系是复合式的。这是因为发动机是法拉利车型的部分。
关联关系在类的对象之间保持一种和类型的关系。具有关系,可以是一对一或一对多。在下面的示例中,我们可以看到Employee和Manager类之间存在一对一的关联关系,因为Employee只有一个Manager类。我们在Employee和Department之间也有一对一的关联关系。这些关系的反面是一对多关系,因为一个Department类可能有许多员工,一个经理可能有许多员工向他们报告。以下代码段描述了关联关系:
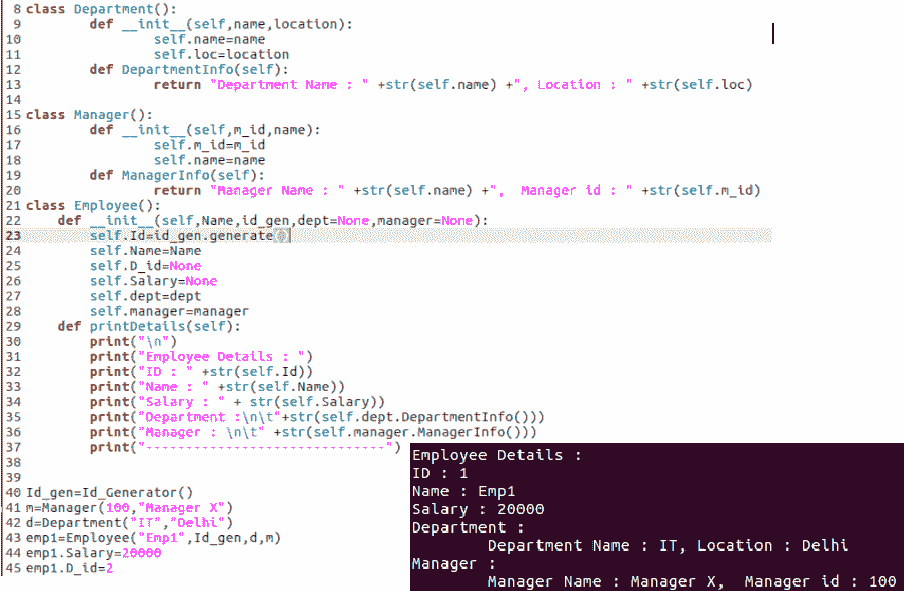
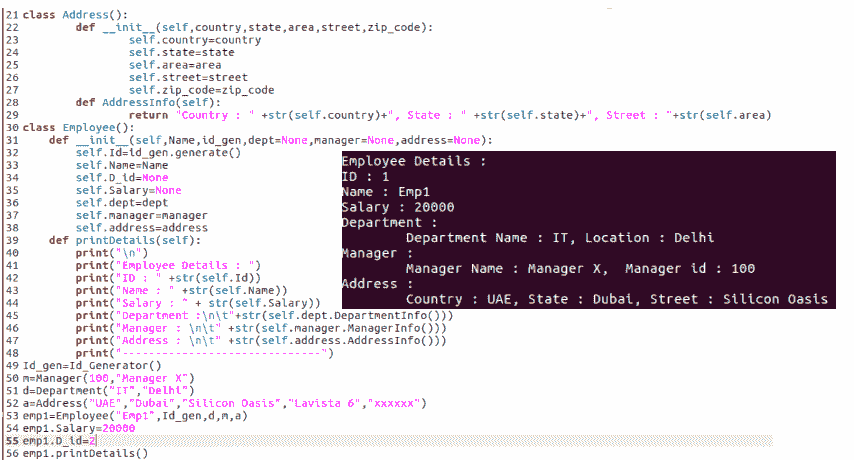
聚合关系是一种特殊的关系,其关系始终是单向的。它也被称为单向关联关系。例如,Employee和Address之间的关系是单向关联,因为员工总是有地址,但情况并非总是相反。以下示例描述了Employee和Address之间的聚合关系:
在许多情况下,我们可能希望部分实现一个类,这样该类就可以用模板定义其目标,并且还可以定义它必须如何借助一些实现的方法获得其目标的一部分。类目标的剩余部分可以由子类实现,这是必需的。为了实现这样的用例,我们使用抽象类。抽象基类,通常称为abc类,是包含抽象方法的类。抽象方法是没有实现的方法。它只包含减速,并且要在将实现或继承抽象类的类中实现。
关于抽象类的一些重要提示包括:
- Python 中的一个抽象方法是用
@abstractmethod修饰符声明的。 - 虽然抽象类可以包含抽象方法,但没有任何东西可以阻止抽象类也包含普通或非抽象方法。
- 无法实例化抽象类。
- 抽象类的子类必须实现基类的所有抽象方法。如果失败,则无法实例化它。
- 如果抽象类的子类没有实现抽象方法,它会自动成为一个抽象类,然后可以由另一个类进一步扩展。
- Python 中的抽象类是使用
abc模块实现的。
让我们创建一个名为Abstract.py的类,看看如何在 Python 中使用抽象类:
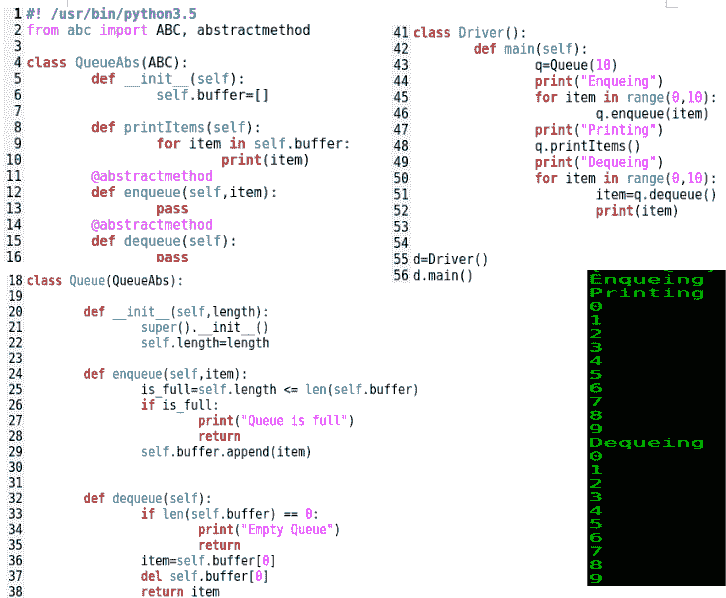
在前面的示例中,我们创建了一个名为QueueAbs的抽象类,它继承了名为ABC的Abstract基类。这个类有两个抽象方法,enqueue和dequeue,还有一个具体方法叫printItems()。然后,我们创建了一个名为Queue的类,它是QueueAbs抽象基类的一个子类,实现了enqueue和dequeue方法。最后,我们创建Queue类的实例并调用方法,如前所示。
这里值得记住的一点是,在 Java 和 C 中,抽象类不能实现抽象方法。Python 并非如此。在 Python 中,抽象方法可能有默认实现,也可能没有默认实现,但这并不阻止子类重写它。无论抽象类方法是否有实现,子类都必须重写它
多态性是指一个实体可以以多种形式存在的属性。在编程方面,它指的是创建一个结构或方法,然后可以与多个对象或实体一起使用。在 Python 中,多态性可以通过以下方式实现:
- 函数多态性
- 类的多态性(抽象类)
让我们考虑两个类,Ferrari和McLaren。让我们假设两者都有一个返回汽车最高速度的Speed()方法。让我们考虑一下在这个场景中如何使用函数多态性。让我们创建一个名为Poly_functions.py的文件:
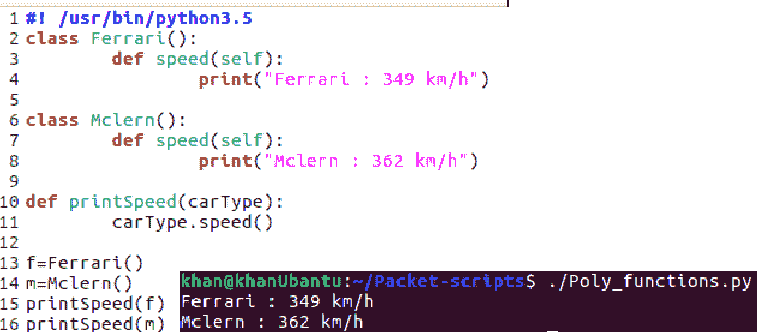
我们可以看到我们有两个类,Ferrari和McLaren。两者都有一个共同的速度方法,打印两辆车的速度。一种方法是创建这两个类的实例,并对每个实例调用 print-speed 方法。另一种方法可以是创建一个公共方法,该方法获取类的实例,并对其接收的实例调用 speed 方法。这是我们在第 10 行定义的多态性printSpeed(carType)函数。
在某些情况下,我们可能希望根据类必须做什么来定义类的模板,而不是根据它应该如何做来定义模板——我们希望将其留给类的实现。这是我们可以使用抽象类的地方。让我们创建一个名为Poly_class.py的脚本,并添加以下代码:
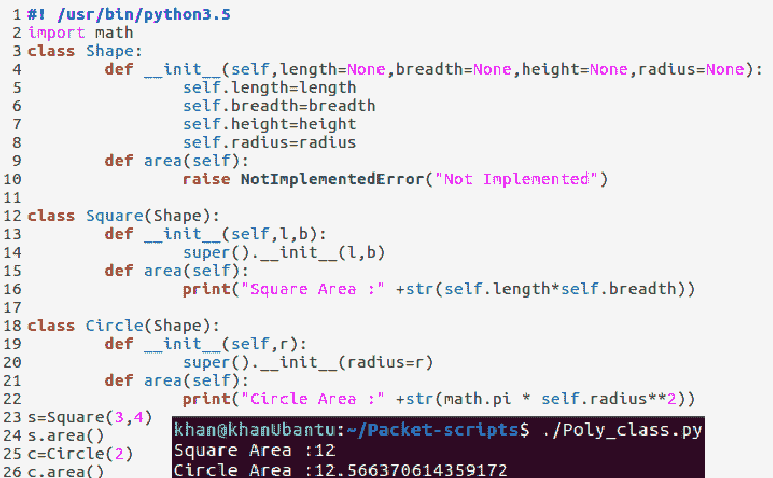
可以看出,我们有一个名为Shape的抽象类,它有一个area方法。area方法没有在这个类中实现,但它将在子类中实现。Square和Circle子类重写area方法。area方法是多态的,这意味着如果一个正方形覆盖它,它将实现一个正方形的面积,而当Circle类覆盖它时,它将实现一个圆的面积。
Python 类中可以定义三种方法。到目前为止,我们主要处理的是实例方法,我们使用 Python 类实例调用了这些方法:
-
实例方法和变量:Python 类中定义的任何方法,如果与该类的实例一起调用,并将 self 作为其第一个位置参数,则称为实例方法。实例方法能够访问该类的实例变量和其他实例方法。通过
self.__class__构造,它还可以访问类级变量和方法。另一方面,实例变量是 Python 类中使用self关键字声明的任何变量。 -
类方法和变量:任何用类名称调用的
@classmethodPython decorator 声明的方法都被称为类方法。类方法也可以在没有@classmethod修饰符的情况下声明。如果是这种情况,则必须使用类名调用它。类方法只能访问在类级别标记或声明的变量,而不能访问对象或实例级别的类变量。另一方面,类变量可以在任何方法之外声明。在类中,我们必须在不使用 self 关键字的情况下声明变量。由于这个原因,类变量和方法在某种程度上类似于我们在 Java 中研究的静态方法和变量,但有一个缺点,如下所述:
在 Java 和 C#中,我们知道静态变量不能通过类的实例访问。在 Python 中,静态变量是类级别的变量,它们实际上可以被类的实例访问。但是访问是只读的,因此,每当使用类的实例访问类级别的变量并且该实例尝试修改或更新它时,Python 就会自动创建同名变量的新副本,并将其分配给该类的实例。这意味着下次使用同一实例访问变量时,它将隐藏类级变量,并提供对新创建的实例级副本的访问。
-
静态方法:Python 类中使用
@staticmethod修饰符声明的任何方法都被称为静态方法。Python 中的静态方法与我们在 Java 和 C 中看到的不同。静态级方法无权访问实例或对象级变量,也无权访问类的类级变量。
让我们举一个名为Class_methods.py的例子来进一步解释这一点:
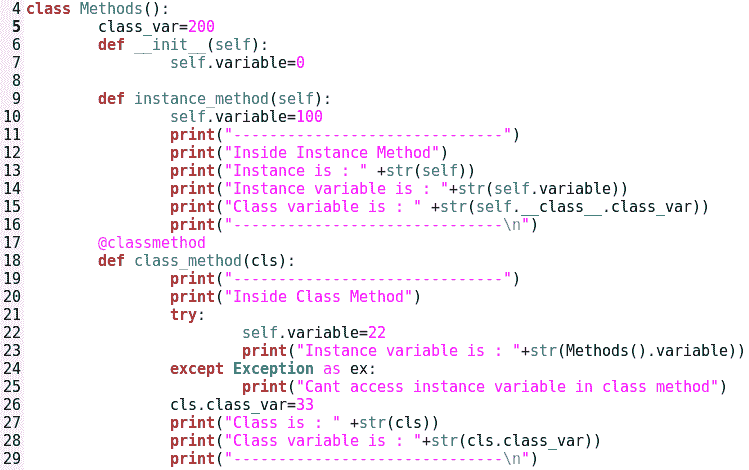
上述代码的延续如下所示:

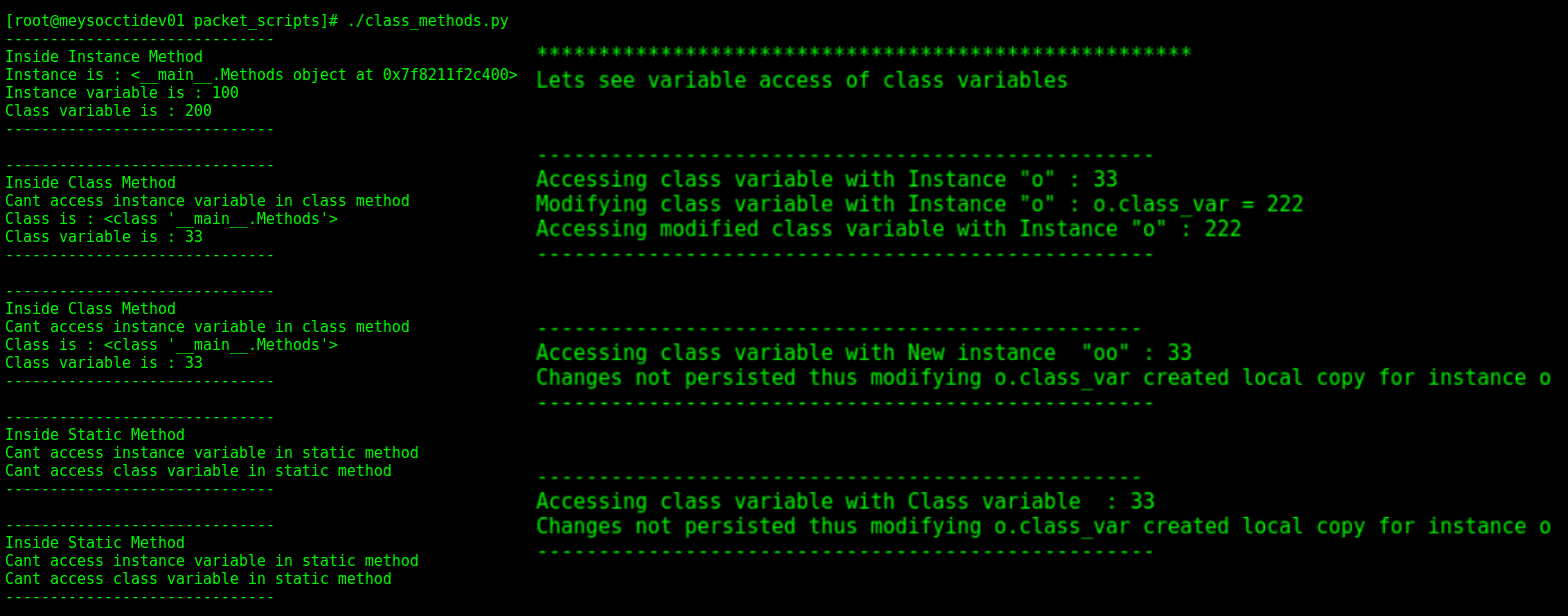
前面的代码片段解释了静态、实例和类方法的使用。每当类的实例调用类方法时,Python 会在内部自动将实例类型转换为类类型,如第 42 行所示
输出如以下屏幕截图所示:
与任何其他编程语言一样,Python 提供了一个强大而简单的界面来处理 I/O、文件和目录。我们将在以下章节中更详细地探讨这些问题。
我们可以用 Python 读取、写入和更新文件。Python 有一个开放的结构,可以用来提供文件操作。当我们打开一个文件时,有多种模式可以打开该文件,如下所示:
-
r:读取模式,以文本模式读取文件(默认)。 -
rb:以二进制模式读取文件。 -
r+:以读写模式读取文件。 -
rb:打开文件,以二进制方式读写。 -
w:仅在写入模式下打开文件。它将覆盖现有文件。 -
wb:打开文件,以二进制方式写入。它将覆盖现有文件。 -
w+:这将以写入和读取模式打开文件。它将覆盖现有文件。 -
wb+:以二进制模式打开文件进行读写。它将覆盖现有文件。 -
a:以追加模式打开文件,如果文件不存在,则创建文件。 -
ab:以追加二进制模式打开文件,如果文件不存在,则创建一个文件。 -
a+:这将以追加和读取模式打开文件,如果文件不存在,则创建一个文件。 -
ab+:以追加读取二进制模式打开文件,如果文件不存在,则创建一个文件。
在下面的代码块中,open方法调用的第一个参数是要打开的文件的路径。第二个是必须打开文件的mode,第三个是可选的缓冲参数,指定文件所需的buffer大小:0表示未缓冲,1表示行缓冲,任何其他正值表示使用(大约)该大小(字节)的缓冲区。负缓冲意味着应该使用系统默认值。对于 tty 设备,这通常是行缓冲的,而对于其他文件,则是完全缓冲的。如果省略,则使用系统默认值。
open("filepath","mode",buffer)使用缓冲,而不是直接从原始文件的操作系统表示中读取(这会有很高的延迟),而是将文件读入操作系统缓冲区,然后从那里读取。这样做的好处是,如果共享网络上存在一个文件,并且我们的目标是每 10 毫秒读取一次文件。我们可以在缓冲区中加载一次文件,然后从缓冲区中读取,而不是每次从网络中读取,这将非常昂贵。
请查看File_access.py文件中的以下片段以了解更多信息:
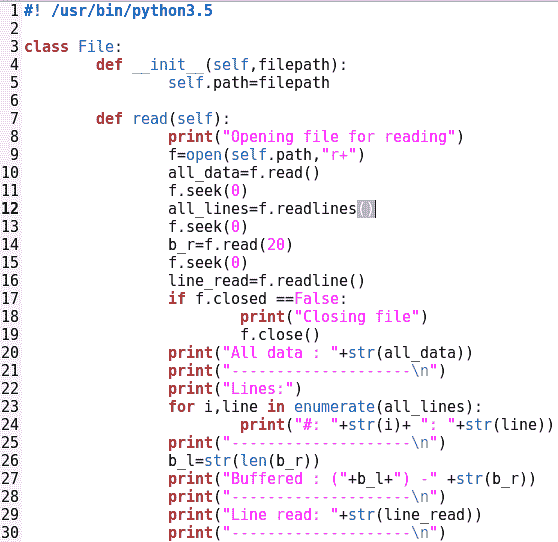
File_access.py文件前面截图中的代码片段解释了如何在 Python 中使用文件。File类的read()方法取文件路径,如果没有给出整个路径,则假定当前工作目录为起始路径。在文件实例上调用的read()方法将整个文件读取到程序变量中。read(20)将从当前文件指针位置的文件中加载 20 个字节。这在处理大文件时非常方便。
readlines()方法返回一个列表,每个条目都指向文件的每一行。readline()方法返回文件中的当前行。seek()方法将把文件指针带到参数中指定的位置。因此,无论何时执行seek(0),文件指针都指向文件的开头:

在 Python 中,os模块提供对文件目录和各种其他操作系统命令的系统级访问。os模块是一个非常强大的实用程序。在本节中,我们将看到它在重命名、删除、创建和访问目录方面的一些用途,借助于os_directories.py文件中的以下片段:
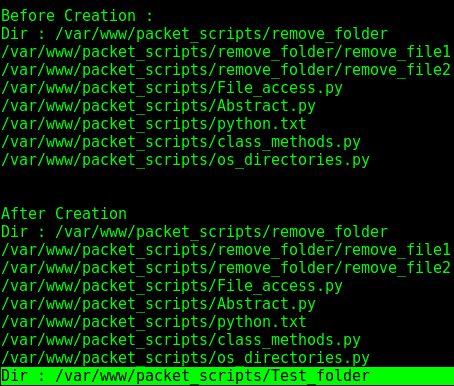
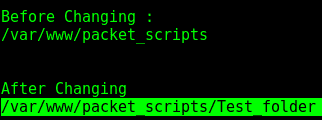
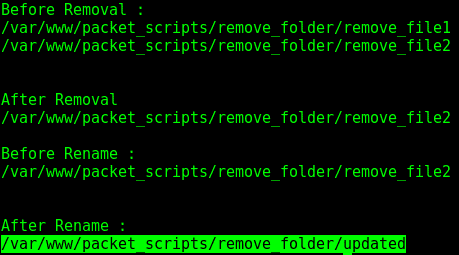
前面屏幕截图中的代码片段显示了os模块与 Python 中的文件和目录一起使用的各种方式,以便重命名和删除文件以及创建和更改目录。它还向我们展示了如何重命名和遍历子文件夹中的所有文件(包括嵌套文件)。需要注意的是,如果我们想要删除一个文件夹,我们可以使用os.rmdir()方法,但为了使其工作,应该明确删除该文件夹的所有文件:
- 以下输出显示了文件创建前后的情况:
- 以下输出显示了文件名的更改:
- 以下输出显示删除文件后的更改:
到目前为止,我们处理的 Python 程序大多以硬编码数据作为输入。让我们看看如何在 Python 中获取用户的输入,并在代码中使用它。我们将创建一个名为user_input.py的文件:
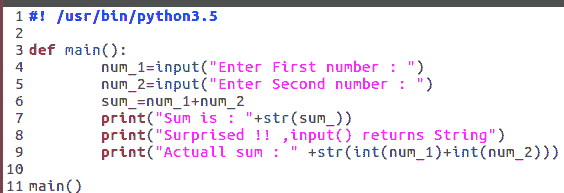
这是不言自明的。为了获取用户输入,我们使用input()方法,在用户提供输入之前暂停屏幕。它总是返回一个字符串:
正则表达式功能强大,广泛用于网络安全领域的模式匹配,无论是解析日志文件、Qualys 或 Nessus 报告,还是 Metasploit、NSE 或任何其他服务扫描或利用脚本生成的输出。为 Python 中的正则表达式提供支持的模块是re。我们将在 Python 正则表达式中使用一些重要的方法(re模块),如下所述:
| match() | 这确定正则表达式是否在字符串re.match(pattern,string,Flag=0)的开头找到匹配项。这些标志可以通过|或运算符指定。最常用的标志是re.Ignore-Case、re.Multiline和re.DOTALL。这些标志可以用 or 运算符指定为(re.M| re.I。 |
| search() | 与 match 不同,search 不只是在字符串的开头查找匹配项,而是在整个字符串中搜索或遍历,以查找可以指定为re.search(pattern,string,Flag=0)的给定搜索字符串/正则表达式。 |
| findall() | 这将在字符串中搜索正则表达式匹配项,并在找到匹配项的位置以列表形式返回所有子字符串。 |
| group() | 如果找到匹配项,则group()返回与 RE 匹配的字符串。 |
| start() | 如果找到匹配,则start()返回匹配的起始位置。 |
| end() | 如果找到匹配,则end()返回匹配的结束位置。 |
| span() | 如果找到匹配,则span()返回一个元组,其中包含匹配的开始和结束位置。 |
| split() | 这将根据正则表达式匹配对字符串进行拆分,并返回一个列表。 |
| sub() | 这用于替换字符串。它将替换所有找到匹配项的子字符串。如果未找到匹配项,则返回一个新字符串。 |
| subn() | 这用于替换字符串。它将替换所有找到匹配项的子字符串。返回类型是一个元组,新字符串位于索引 0,替换数位于索引 1。 |
现在,我们将借助regular_expressions.py脚本中的以下片段来理解正则表达式:
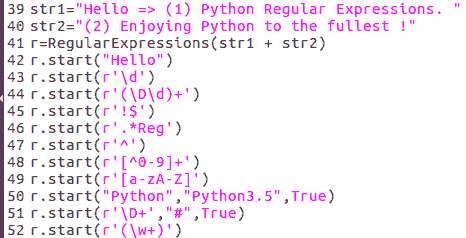
match和search之间的区别在于match只搜索字符串开头的模式,而search搜索整个输入字符串。代码行 42 和 50 产生的输出将说明这一点:

在前面的屏幕中,可以看到当Hello输入被传递时,match和search都能够定位字符串。然而,当传递的输入是\d(表示任何小数点)时,match无法找到它,但search已找到。这是因为search方法搜索整个字符串,而不仅仅是开始。
再次,从下面的截图可以看出,match没有返回数字和非数字的分组,但是search返回了:
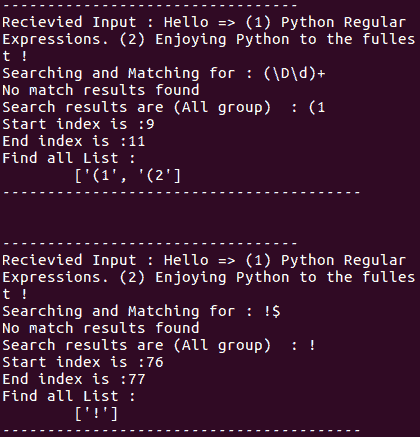
在下面的输出中,搜索了Reg关键字,所以match和search都返回结果:

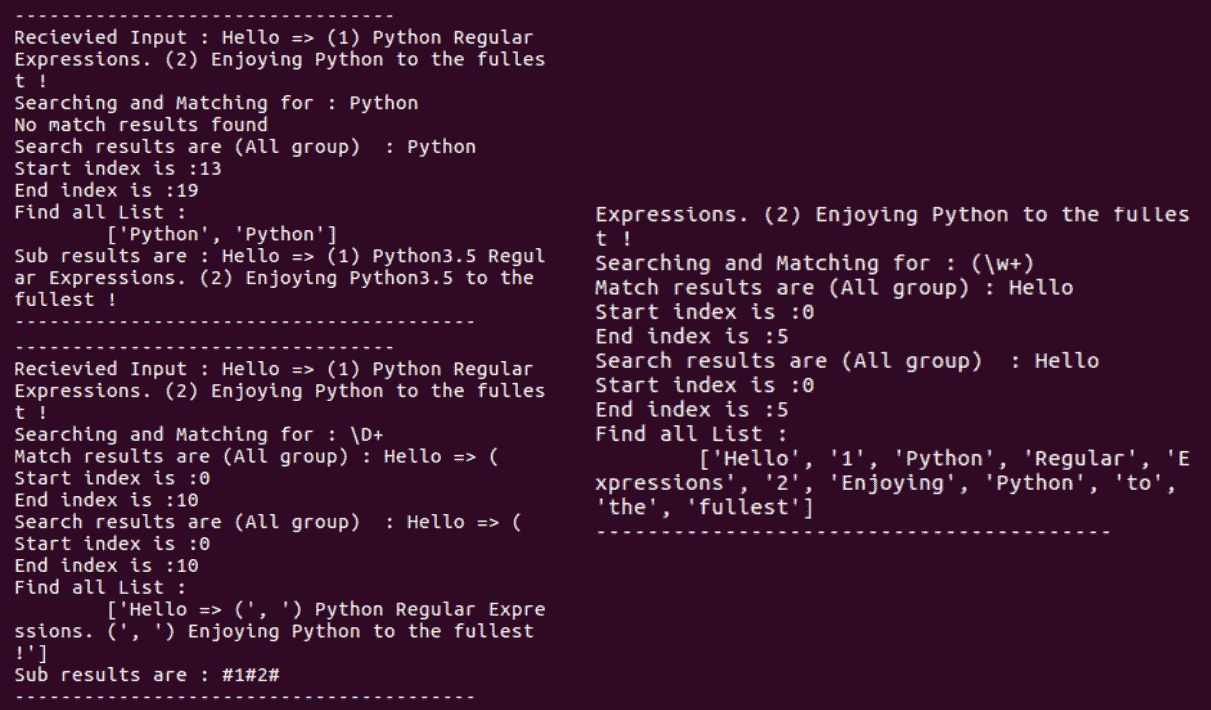
请注意以下截图中的findall()与match和search有何不同:
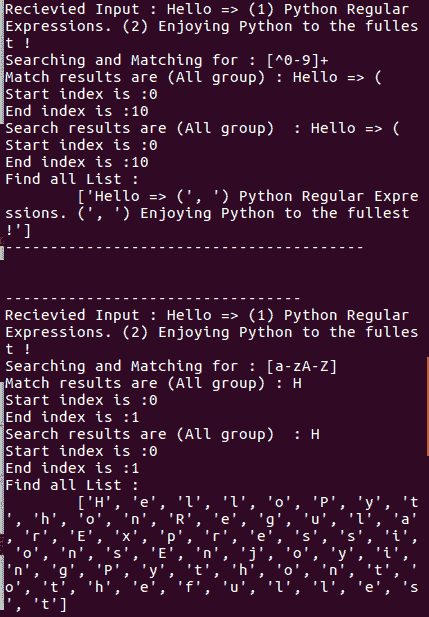
这些示例说明了match()和search()的操作方式不同,以及search()在执行搜索操作时如何更强大:
让我们看一下 Python 中的一些重要正则表达式:
| 正则表达式 | 说明 |
| \d | 这将 0 到 9 之间的数字与字符串匹配。 |
| (\D\d) | 这与组合在一起的\D非数字和\d数字相匹配。括号(()用于分组。 |
| .*string.* | 如果在字符串中找到一个单词,则无论其前后是什么,都会返回一个匹配项。.*符号意味着一切。 |
| ^ | cap 符号表示它与字符串开头的图案匹配。 |
| [a-zA-Z0-9] | [...]用于匹配支架内放置的任何东西。例如,[12345]意味着应该为 1 到 5 之间的任何数字找到匹配项。[a-zA-Z0-9]表示所有字母数字字符应视为匹配。 |
| \w | \w与[a-zA-Z0-9_]相同,并匹配所有字母数字字符。 |
| \W | \W是\w的否定,与所有非字母数字字符匹配。 |
| \D | \D是\d的否定,匹配所有非数字字符。 |
| [^a-z] | ^放在[]内,表示否定。在本例中,它意味着匹配除从a到z的字母以外的任何内容 |
| re{n} | 这意味着精确匹配前面表达式的n出现次数。 |
| re{n ,} | 这意味着匹配前面表达式的n或更多次出现。 |
| re {n,m} | 这意味着匹配前面表达式的最小值n和最大值m。 |
| \s | 这意味着匹配空格字符。 |
| [T|t]est | 这意味着同时匹配Test和test。 |
| re* | 这意味着匹配*之后出现的任何表达式。 |
| re? | 这意味着匹配?之后出现的任何表达式。 |
| re+ | 这意味着匹配+之后出现的任何表达式。 |
在本节中,我们将首先介绍如何在 Python 中操作 XML 数据,然后介绍如何操作 JSON 数据。之后,我们将重点关注 CSV,来看看 pandas Python 实用程序。
在本节中,我们将了解如何在 Python 中操作 XML 数据。虽然 Python 中有许多解析 XML 文档的方法,但最简单、使用最广泛的方法是使用XML.etree模块。让我们看看下面的示例,它将说明用 Python 解析 XML 文档和字符串是多么容易和简单。创建一个名为xml_parser.py的脚本。我们将使用一个名为exmployees.xml的 XML 文档:
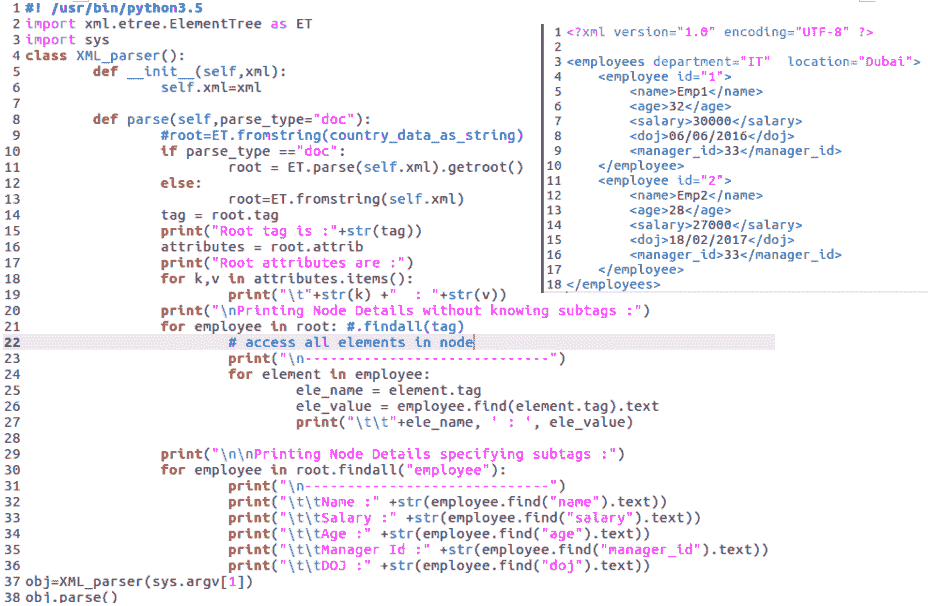
从前面的示例中可以看出,我们只需使用xml.etree.ElementTree模块并将其别名为 ET。在类的 parse 方法中,我们通过调用parse方法(在前一种情况下)和fromstring方法(在后一种情况下)来提取 XML 文档或 XML 字符串的根。这将返回一个<class 'xml.etree.ElementTree.Element'>ET 元素类的实例。我们可以迭代它以获得所有子节点,如第 21 行到第 26 行所示。如果我们不知道节点属性的名称,类的attrib属性将返回一个字典,该字典具有属性名称及其值的键值映射。如果我们确实知道子节点的名称,我们可以遵循第二种方法,如第 29 行到第 36 行所示,在这里我们指定节点的名称。
如果我们传递一个 XML 字符串而不是一个文件,唯一的变化是初始化根元素的方式;其余的都一样。关于这个脚本,需要注意的另一点是,我们使用的是命令行参数。sys.argv[]用于访问这些命令行参数,文件的第 0个索引具有脚本本身的名称以及从索引 1 开始的参数。在我们的示例中,XML 文件的名称作为命令行参数传递给脚本,并使用sys.argv[1]属性进行访问。这显示在以下输出中:

现在让我们看看如何使用 Python 来操作 JSON 数据。JSON(Java 脚本对象表示法)是一种非常广泛使用的数据存储和交换格式。随着互联网的成熟,它越来越流行,并成为基于 REST 的 API 或服务中信息交换的标准。
Python 为我们提供了一个用于 JSON 数据操作的 JSON 模块。让我们创建一个名为employees.json的 JSON 文件,看看如何使用 JSON 模块访问 JSON 内容。假设我们的目标是读取员工的数据,然后找到工资超过 30000 的员工,并用 slabA标记。然后,我们将在工资低于 30000 的员工身上标记 slabB:

获得的输出如以下屏幕截图所示:
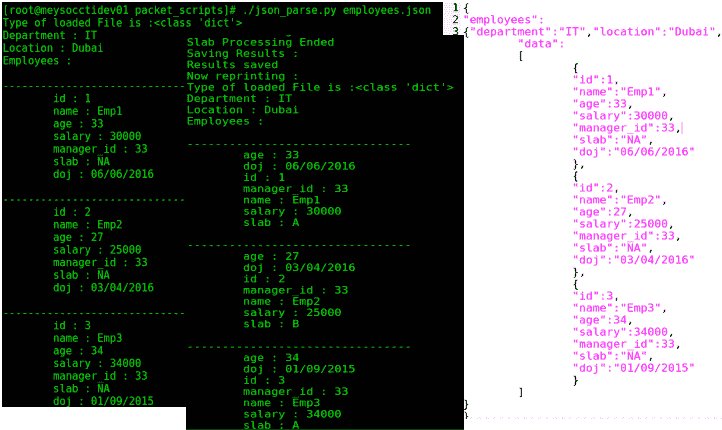
从前面的代码可以推断,JSON 文件作为 Python 字典加载,这可以通过json.load()命令实现。load ()方法希望 JSON 文件路径作为参数提供。如果 JSON 数据不是作为外部文件而是作为 Python 字符串出现,我们可以使用json.loads()方法并将 JSON 字符串作为参数传递。这将再次将字符串转换为 Python 本机类型,即列表或字典。这可以看出如下几点:
>>> a='{"k1":"v1"}'
>>> d=json.loads(a)
>>> type(d)
<class 'dict'在json_parse.py文件中,第 10 行到第 20 行简单地迭代 Python 字典和内部列表,并显示员工详细信息。这是我们以前见过的。脚本的目标实际上是更新 employee slab,这是通过process()方法实现的。我们以 Python 本机类型(第 23 行)再次打开并加载 JSON 文件。然后,我们迭代 Python 字典。在第 27 行,我们检查员工的工资是否大于或等于 30000。如果是,我们通过修改加载所有详细信息的原始json_data对象来修改员工的楼板。json_data["employees"]["data"][index]["slab"]语句将指向当前员工的平板,决定他们的工资是否高于或低于 30000,并根据需要将其设置为A或B。最后,我们将在json_data对象中修改员工的详细信息,并使用json.dump() method.json.dump()文件对象覆盖原始 JSON 文件的内容。这将获取 Python 本机对象(列表、字典或元组),并将其转换为 JSON 等价物。它将file_object作为第二个参数,以指示 JSON 数据必须去哪里。它还需要格式化选项,如indent、sort_keys等。同样,我们还有一个json.dumps()方法,它将 Python 本机类型转换为其 JSON 字符串等价物。具体情况如下:
>>> json.dumps({"k1":"v1"})
'{"k1": "v1"}'应该记住,外部 JSON 文件不能就地修改。换句话说,我们不能修改外部 JSON 文件的一部分,而保持其余部分不变。在这种情况下,我们需要用新内容覆盖整个文件。
CSV 数据广泛应用于网络安全和数据科学领域,无论是以日志文件的形式,还是作为 Nessus 或 Qualys 报告(Excel 格式)的输出,还是用于机器学习的大型数据集。Python 通过内置的 CSV 模块为 CSV 文件提供了极好的支持。在本节中,我们将探索这个模块,并重点关注 CSV,查看 pandas Python 实用程序。
让我们首先看看 Python 提供的内置 CSV 模块。以下名为csv_parser.py的代码片段演示了此模块:

前面的代码帮助我们理解如何使用 CSV 模块读取 Python 中的 CSV 文件。始终建议使用 CSV 模块,因为它会在内部处理分隔符、新行和字符。有两种读取 CSV 文件的方法,第一种是使用csv.reader()方法(第 10-25 行),该方法返回 CSV 字符串列表。列表中的每一行或每一项都是一个字符串列表,表示 CSV 文件的一行,其中的每一项都可以通过索引进行访问。另一种读取 CSV 文件的方法是借助csv.DictReader()(第 29-38 行),它返回字典列表。每个字典都有一个键值对,其中一个键值表示 CSV 列,另一个键值表示实际的行值。
产生的输出如下所示:
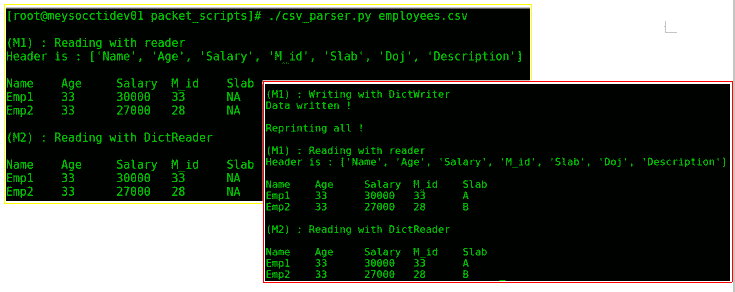
为了写入 CSV 文件,还有两种不同的方法。一种方法是使用csv.DictWriter()指令,该指令返回一个 writer 对象,并具有将 Python 列表或字典直接推送到 CSV 文件的功能。当我们调用列表或字典上的writerows()方法时,这将在内部将 Python 列表或字典转换为 CSV 格式。从第(40-53)行可以看出:我们检查员工的工资,将适当的 slab 与之关联,最后使用writerows()方法覆盖修改后的 CSV 文件。csv.DictWriter()同时支持writerows()和write row()方法。writerows()方法只需获取一个字典并将其写入 CSV 文件。
第二种写入 CSV 文件的方法是使用csv.Writer()方法。这将返回一个 writer 对象,该对象将列表(字符串)列表作为writerows()方法的参数,并将结构写入外部 CSV 文件。以下屏幕截图显示了这两种方法的示例:

虽然前面的访问和处理 CSV 文件的方法很好,但是如果 CSV 文件非常大,这些方法也不会有帮助。如果 CSV 文件是 10GB,而系统的 RAM 只有 4GB,那么csv.reader()和csv.DictReader()都不能正常工作。这是因为reader()和DictReader()都在可变程序内存(即 RAM)中完全读取外部 CSV 文件。对于大型文件,不建议直接使用 CSV 模块。
另一种方法是在迭代器的帮助下读取文件,或以字节块的形式读取文件,如以下屏幕截图所示:
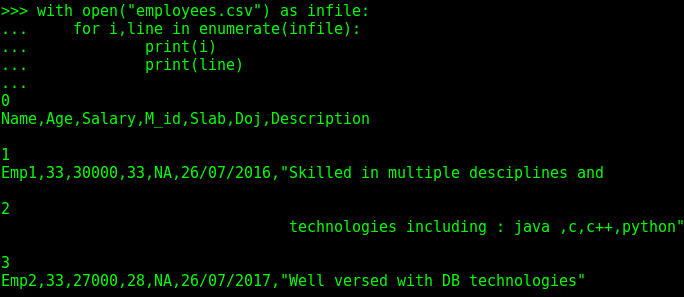
前面的代码段不会将整个文件加载到内存中,而是一次读取一行。通过这种方式,我们可以在数据库中处理和存储该行,或者执行任何相关操作。因为文件是逐行读取的,如果我们有多行 CSV 数据,这将导致问题。如前例所示,Emp1的第一条记录没有被完全读取;它被分成两行,第二行只包含Description字段的一部分。这意味着前面的方法不适用于大型或多行 CSV 文件。
如前所述,如果我们试图以块或字节的形式进行读取,我们将不知道一行对应多少块或字节,因此这也会产生不一致的结果。为了解决这个问题,我们将使用 Pandas,一个强大的 Python 数据分析工具包。
有关大熊猫的详细信息,请浏览以下内容:http://pandas.pydata.org/pandas-docs/stable/ 。
首先,我们需要安装熊猫,具体操作如下:
pip3.5 install pandas下面的代码片段解释了如何使用 pandas 以小块的形式读取一个巨大的 CSV 文件,从而减少内存使用:

如前面的代码片段所示,我们将区块大小声明为 100000 条记录,假设我们要处理一个非常大的 CSV 文件。块大小是上限;如果实际记录小于块大小,程序将只获取两个记录中最小的一个。然后,我们加载带有pd.read_csv()的 CSV 文件,将块大小指定为参数之一。chunk.rename()方法实际上会从列名(如果有)中删除换行符,chunk.fillna('')将使用 CSV 文件返回的空值。而不是 NA,它将用空字符串填充它们。最后,我们使用返回元组的iterrows()方法对行进行迭代,然后打印值,如图所示。需要注意的是,pd.read_csv()返回一个数据帧,可以将其视为内存中的关系表。
我们都知道,例外情况是无法预见的情况。它们可能在运行时出现并导致程序崩溃。因此,建议将可疑代码(可能导致异常)放入异常处理代码块中。然后,即使发生异常,我们的代码也会适当地处理它并采取所需的操作。与 Java 和 C#一样,Python 也支持传统的 try-and-catch 块来处理异常。然而,有一个细微的变化,那就是 Python 中的 catch 块被调用为 except。
以下代码片段显示了如何在 Python 中执行基本异常处理:
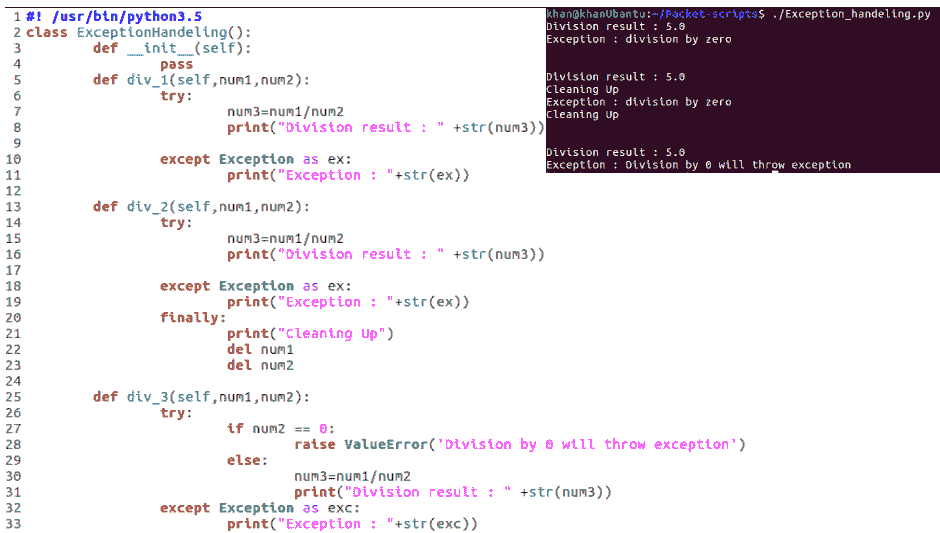
前面的代码是自解释的。Python 使用了try和except,而不是try和catch。我们使用raise命令手动抛出异常。最终块的工作方式与其他所有语言一样,其核心条件是,无论是否发生异常,都应执行最终块。
应该注意的是,在前面的示例中,我们在处理 except 块中的异常时使用了一个通用异常类。如果我们确定代码可能引发什么样的异常,我们可以使用特定的异常处理程序,例如IOError、ImportError、ValueError、KeyboardINterupt和EOFError。最后,还应该记住,在 Python 中,我们可以在try块旁边使用 else 块。
在本章中,我们讨论了面向对象编程、文件、目录、IO、XML、JSON、CSV 以及与 Python 相关的异常处理。这些是 Python 的核心结构,使用非常广泛。当我们继续使用 Python 实现渗透测试和网络安全部分时,我们将经常使用所有这些结构和概念,因此我们必须充分了解它们。在下一章中,我们将讨论更高级的概念,如多线程、多处理、Python 中的子进程和套接字编程。在这一章中,我们将完成对 Python 先决条件的探索,这将反过来引导我们学习 Python 的渗透测试和网络安全生态系统。
- 我们经常听说 Python 是一种脚本语言。将它用作面向对象语言的典型优势是什么?你能想到任何特定的产品或用例吗?
- 列举一些我们可以解析 XML 和 CSV 文件的方法。
- 我们能在不查看类结构的情况下检测类的所有属性吗?
- 什么是方法装饰器?
- 熊猫:https://pandas.pydata.org/
- NumPy:http://www.numpy.org/
- Python GUI 编程:https://www.python-course.eu/python_tkinter.php