- JavaScript 代码整洁指南
 PDF电子书集合
PDF电子书集合
JavaScript 编写干净的测试详解
在最后一章中,我们介绍了软件测试的理论和原则。 我们深入探讨了单元测试、集成测试和端到端测试所固有的优点和挑战。 在本章中,我们将利用这些知识并将其应用到一些真实的例子中。
仅仅理解测试是什么并从业务的角度看它的优点是不够的。 我们编写的测试构成了我们代码库的重要组成部分,因此应该以与我们编写的所有其他代码相同的谨慎方式进行编写。 我们想要精心设计测试,不仅让我们相信我们的代码可以按照预期工作,而且它们本身是可靠的、有效的、可维护的和可用的。 我们还必须警惕编写过于复杂的测试。 这样做会使我们陷入这样一种情况,即我们的测试增加了理解的负担,并导致代码库的整体复杂性和脆弱性增加,降低了整体的生产力和满意度。
如果小心谨慎地使用,测试可以使代码更加清晰和整洁,使用户和同事能够以更快的速度和质量执行他们的工作。 在接下来的部分中,我们将探讨编写测试时应采用的最佳实践和要避免的潜在陷阱。
在本章中,我们将涵盖以下主题:
编写任何测试(无论是细粒度的单元测试还是影响深远的E2E 测试)时,最重要的考虑之一就是要测试什么。 测试错误的东西是完全有可能的; 这样做会给我们的代码带来错误的信心。 我们可能编写了一个巨大的测试套件,然后笑着离开,认为我们的代码现在满足了所有的期望,并且完全可以容错。 但是我们的测试套件可能不会测试我们认为它能做的事情。 也许它只测试几个狭窄的用例,使我们暴露在许多可能的破坏中。 或者,它可能以一种从未在现实中模拟的方式进行测试,导致我们的测试无法保护我们免受生产中的失败。 为了保护我们不受这些可能性的影响,我们必须了解我们真正希望测试的是什么。
考虑我们编写的一个函数,它从任意字符串中提取指定格式的电话号码。 电话号码可以有多种形式,但都是 9 到 12 位数字:
0800-144-1440779231687701263 109388111-222-3330822 888 111
以下是我们目前的实施方案:
function extractPhoneNumbers(string) {
return string.match(/(?:[0-9][- ]?)+/g);
}我们决定写一个测试来断言代码的正确性:
expect(
extractPhoneNumbers('my number is 0899192032')
).toEqual([
'0899192032'
]);我们使用的断言是至关重要的。 重要的是我们要测试正确的东西。 在我们的示例中,这应该包括包含各种输入的示例字符串:包含电话号码的字符串、不包含数字的字符串以及混合包含电话号码和非电话号码的字符串。 只检测阳性病例太容易了,但实际上检查阴性病例也同样重要。 在我们的场景中,消极情况包括没有电话号码要提取的情况,因此可能由以下字符串组成:
"this string is just text...""this string has some numbers (012), but no phone numbers!""1 2 3 4 5 6 7 8 9""01-239-34-32-1""0800 144 323 492 348""123"
很快地,在编写这样的示例案例时,我们看到了我们的实现必须满足的复杂性的真实范围。 顺便说一句,这突出了使用测试驱动开发**(TDD*)来确定预期的巨大优势。 现在我们有一些字符串,其中包含我们不希望*提取的数字,我们可以将它们表示为断言,如下所示:
expect(
extractPhoneNumbers('123')
).toEqual([/* empty */]);目前这个失败。 extractPhoneNumbers('123')呼叫返回["123"]错误。 这是因为我们的正则表达式还没有对长度做出任何规定。 我们可以很容易地解决这个问题:
function extractPhoneNumbers(string) {
return string.match(/([0-9][- ]?){9,12}/g);
}添加的{9,12}部分将确保前面的组(([0-9][- ]?))只匹配9和12两次,这意味着对extractPhoneNumbers('123')的测试现在将正确返回[](一个空数组)。 如果我们对每个示例字符串重复这个测试和迭代过程,我们最终将得到正确的实现。
从这个场景中得到的关键结论是,我们应该寻求测试我们可能期望的输入的全部范围。 根据我们所测试的内容,我们通常可以说,我们所编写的任何代码都会满足有限的可能场景集。 我们希望确保有一组测试来分析这一范围的场景。 这一系列场景通常被称为给定功能或模块的输入空间或输入域。 我们可以考虑一些经过良好测试的如果我们让它代表各种各样的输入从输入空间,,在这种情况下,包括字符串与有效电话号码和无【显示】有效电话号码:
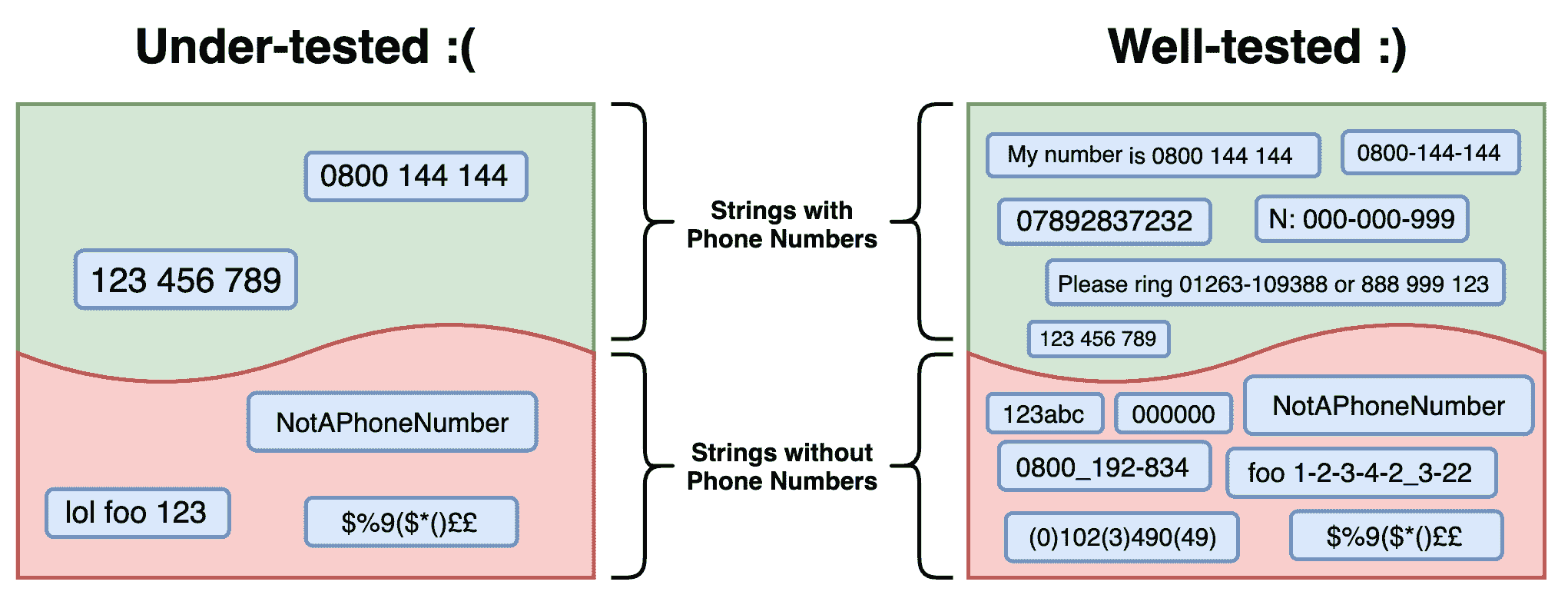
没有必要测试每一种可能性。 更重要的是测试其中一个有代表性的样本。 要做到这一点,首先必须识别我们的输入空间,然后将其划分为具有代表性的奇异输入,然后我们可以单独测试。 例如,我们需要测试电话号码"012 345 678"是否被正确地识别和提取,但对我们来说,详尽地测试相同格式的变体("111 222 333"、"098 876 543"等等)是没有意义的。 这样做不太可能在我们的代码中暴露任何额外的错误或 bug。 但我们肯定应该测试使用不同标点或空格的其他格式(如"111-222-333"或"111222333")。 另外重要的是,要建立可能在预期的输入空间之外的输入,例如无效类型和不支持的值。
对软件需求的全面理解将使您能够生成经过良好测试的正确实现。 所以,在我们开始编写代码之前,我们应该始终确保我们确切地知道我们要创建的是什么。 如果我们发现自己不确定完整的输入空间可能是什么,这是一个强有力的指示,我们应该后退一步,与涉众和用户对话,并建立一套详尽的需求集。 再一次,这是测试引导的实现(TDD)的强大优势,在这种实现中,需求中的这些缺陷可以及早发现,因此可以在成本陷入无意义的实现之前得到解决。
当我们在脑海中有了我们的需求,并对整个输入空间有了很好的理解时,就到了编写测试的时候了。 测试中最具原子性的部分是它的断言,因此我们希望确保能够有效地制作直观的断言,很好地传达我们的期望。 这是我们接下来要讨论的内容。
任何测试的核心都是它的断言。 断言准确地规定了我们期望发生的事情,所以我们不仅要准确地制定它,而且要以一种使我们的期望完全明确的方式来制定它,这是至关重要的。
一个测试通常会涉及几个断言。 一个测试通常遵循以下形式:给定一个 X 的输入,我是否收到一个 Y的输出? 有时,建立Y是复杂的,可能不局限于一个单一的断言。 我们可能想要内省Y以确认它确实是所需的输出。
考虑一个名为getActiveUsers(users)的函数,它将只返回一组所有用户中的活动用户。 我们可能希望对其输出做出以下几个断言:
const activeUsers = getActiveUsers([
{ name: 'Bob', active: false },
{ name: 'Sue', active: true },
{ name: 'Yin', active: true }
]);
assert(activeUsers.length === 2);
assert(activeUsers[0].name === 'Sue');
assert(activeUsers[1].name === 'Yin');在这里,我们清楚地表达了我们对getActiveUsers(...)输出的期望,即一系列断言。 对于功能更全的断言库或更复杂的代码,我们可以很容易地将其限制为单个断言,但将它们分开可能更清楚。
许多测试库和实用程序提供了抽象来帮助我们进行断言。 流行的测试库,茉莉花和笑话,例如,提供一个功能叫做expect,提供一个接口与许多匹配器,每个单独允许我们申报价值应该有什么样的特征,比如下面的例子:
-
expect(x).toBe(y)断言x与y相同 -
expect(x).toEqual(y)断言x等于y(类似于抽象等式) -
expect(x).toBeTruthy()断言x是真实的(或Boolean(x) === true) -
expect(x).toThrow()断言x,当作为函数调用时,将抛出一个错误
这些匹配器的确切实现可能因库而异,提供的抽象和命名也可能不同。 例如,Chai.js 同时提供了expect抽象和一个简化的assert抽象,允许你以以下方式断言事物:
assert('foo' !== 'bar', 'foo is not bar');
assert(Array.isArray([]), 'empty arrays are arrays');在起草一份声明时,最重要的事情是要完全清楚。 不幸的是,与其他代码一样,很容易编写难以理解或难以解析的断言。 考虑下面的断言:
chai.expect( someValue ).to.not.be.an('array').that.is.not.empty;由于 Chai.js 提供了抽象,该声明看起来很容易理解。 但实际上很难理解到底发生了什么。 让我们考虑一下下面哪个语句可能是检查的:
- 项目不是一个数组?
- 项目不是一个空数组?
- 项目的长度大于 0,不是一个数组?
事实上,检查项目既不是一个数组,non-empty-meaning,如果项目是一个对象,它会检查至少有一个自己的财产,如果它是一个字符串,它将检查它的长度大于零。 这些断言的真正基础力学模糊所以,当暴露于这些事情,程序员可能留在要么幸福的无知状态(思考断言是他们希望它)或痛苦的混乱(想知道地球上的作品)。
可能是这样的情况,我们希望一直简单地断言,someValue不是一个数组,而是类数组,因此,它的长度大于零。 因此,我们可以在一个新的断言中使用 Chai.js 的lengthOf方法来增加清晰度:
chai.expect( someValue ).to.not.be.an('array');
chai.expect( someValue ).to.have.a.lengthOf.above(0);为了避免任何疑问和混淆,我们可以更直接地断言,而不依赖于 Chai.js 的句子式抽象:
assert(!Array.isArray(someValue), "someValue is not an array");
assert(someValue.length > 0, "someValue has a length greater than zero");这可以证明更加清晰,因为它向程序员解释了正在进行的确切检查,消除了使用更抽象的断言风格可能产生的疑虑。
一个好的断言的关键在于它的清晰性。 许多库提供了奇特而抽象的断言机制(例如,通过expect()接口)。 这些可以增加清晰度,但如果使用过度,最终会变得不那么清晰。 有时候,我们只需要Keep it Simple, Stupid(KISS)。 测试代码可能是最糟糕的地方,在那里你可能会对自私自利或错误抽象的代码产生幻想。 简单明了的代码每次都能获胜。
既然我们已经探索了制作直觉断言的挑战,我们可以稍微缩小,看看我们应该如何制作和组织包含它们的测试。 下一节将揭示层次结构作为通过测试套件传递意义的有用机制。
要测试任何代码库,我们可能需要编写大量断言。 理论上,我们可以有一长串的断言,除此之外什么都没有。 然而,这样做可能会使阅读、编写和分析测试报告变得相当困难。 为了防止这种混淆,测试库通常会围绕断言提供一些脚手架抽象。 例如,Jasmine 和 Jest 等 bdd 风格的库提供了两部分脚手架:it块和describe块。 这些只是我们传递描述和回调的函数,但它们结合在一起,使测试的层次树更容易理解正在发生的事情。 使用这个模式测试一个sum函数可以这样做:
// A singular test or "spec":
describe('sum()', () => {
it('adds two numbers together', () => {
expect( sum(8, 9) ).toEqual( 17 );
});
});Behaviour-Driven Development (BDD) is a style and methodology of testing that, similar to TDD, enforces a regime where we write tests first and implementation second. More than this, however, it focuses on the importance of behaviors over implementation, since behaviors are easier to communicate and are more important from the perspective of the user (or stakeholder). BDD-style tests will hence usually use language such as Describe X » It does Y when Z occurs...
非 bdd 库倾向于用更简单的无限嵌套test块来包围断言组,如:
test('sum()', () => {
test('addition works correctly', () => {
assert(sum(8, 9) == 17, '8 + 9 is equal to 17');
});
});正如你所看到的,命名的 BDD-flavoredit和describe条款可以帮助我们为我们的测试套件,工艺描述读起来像完整的英语句子(例如描述苹果»它是圆的,甜的)。 这不是强制的,但给了我们一个有用的提示,以便更好地描述。 我们还可以无限嵌套describe块,这样我们的描述就可以反映出我们正在测试的东西的层次性质。 例如,如果我们正在测试一个名为myMathLib的数学实用程序,我们可以想象下面的测试套件及其各种子套件和规范:
-
myMathLib:-
add():- 它可以使两个整数相加
- 它能使两个分数相加
- 对于非数字输入,它返回
NaN
-
subtract()l:- 它可以减去两个整数
- 它能把两个分数相减
- 对于非数字输入,它返回
NaN
-
PI:- 在小数点后 15 位等于
PI
- 在小数点后 15 位等于
-
这个层次结构自然地反映了我们正在测试的抽象的概念层次结构。 测试库提供的报告将有效地反映这个层次结构。 下面是来自Mocha测试库的示例输出,其中myMathLib的每个测试都成功通过:
myMathLib
add()
✓ can add two integers
✓ can add two fractions
✓ returns NaN for non-numeric inputs
subtract()
✓ can subtract two integers
✓ can subtract two fractions
✓ returns NaN for non-numeric inputs
PI
✓ is equal to PI at fifteen decimal places单个断言聚集在一起形成测试。 单个测试聚集在一起形成测试套件。 每个测试套件都为我们提供了关于特定单元、集成或流程(在端到端测试中)的清晰和信心。 这些测试套件的组合对于确保我们的测试简单易懂至关重要。 我们必须花时间思考如何表达我们所测试的概念层次。 我们创建的测试套件还需要直观地放在代码库的目录结构中。 这就是我们接下来要探讨的。
可以说,测试的目标只是描述您所做的事情。 通过描述,你被迫断言你假设的事实是如何运作的。 当这些断言被执行时,我们就能辨别我们的描述,我们假定的真理,是否正确地反映了现实。
在描述的过程中,我们必须小心地选择我们的词语,以便它们能清楚而容易地表达我们的意思。 测试是我们对抗模糊和复杂性的最后的防御手段之一。 一些代码是不可避免地复杂,我们最好工艺,降低其模糊的性质,但如果我们不能完全做到这一点,那么它的角色是测试清理剩余的困惑,并提供最后的清晰度。**
*在测试时,清晰的关键是纯粹关注必须阅读测试(或其日志输出)的人的观点。 以下是一些需要注意的明确要点:
-
使用测试的名称来准确描述测试的功能,必要时可以过度描述。 例如,而不是测试
Navigation组件呈现,考虑说【显示】测试Navigation正确组件呈现所有导航项目。 我们的名称还可以传达问题域的概念层次结构。 回想一下我们在第五章的一致性和层级章节中提到的。 * 使用变量*作为表达意义的容器。 在编写测试时,最好使用过于明确的变量名,甚至在不必要的地方使用变量,以充分表达您的意图。 例如,考虑一下为什么expect(value).toEqual(eulersNumber)比expect(value).toEqual(2.7182818)更容易理解。 用来解释奇怪的行为。 如果您正在测试的代码以一种意想不到的或不直观的方式执行某些操作,那么您的测试本身可能显得不直观。 作为最后的手段,提供附加的上下文和注释解释是很重要的。 但是,要小心那些不随代码一起更新的陈旧注释。
**考虑以下对AnalogClockComponent的测试:
describe('AnalogClockComponent', () => {
it('works', () => {
const r = render(AnalogClockComponent, { time: "02:50:30" });
expect(rendered.querySelector('.mm-h').style.transform)
.toBe('rotate(210deg)');
expect(rendered.querySelector('.hh-h').style.transform)
.toBe('rotate(-30deg)');
expect(rendered.querySelector('.ss-h').style.transform)
.toBe('rotate(90deg)');
expect(/\btheme-default\b/).test(rendered.className)).toBe(true);
});
});如您所见,这个测试对特定元素的transformCSS 属性做了几个断言。 对于这些是什么,我们有可能做出明智的猜测,但清晰度肯定可以提高。 为了使它更清晰,我们可以使用更好的名称来反映我们正在测试的内容,将测试分开来表示正在测试的不同概念,使用变量名来明确我们所断言的值,并使用注释来解释任何可能不直观的东西:
describe('AnalogClockComponent', () => {
const analogClockDOM = render(AnalogClockComponent, {
time: "02:50:30"
});
const [
hourHandTransform,
minuteHandTransform,
secondHandTransform
] = [
analogClockDOM.querySelector('.hh-h').style.transform,
analogClockDOM.querySelector('.mm-h').style.transform,
analogClockDOM.querySelector('.ss-h').style.transform
];
describe('Hands', () => {
// Note: the nature of rotate/deg in CSS means that a
// time of 03:00:00 would render its hour-hand at 0deg.
describe('Hour', () => {
it('Renders at -30 deg reflecting 2/12 hours', () => {
expect(hourHandTransform).toBe('rotate(-30deg)');
});
});
describe('Minute', () => {
it('Renders at 210 deg reflecting 50/60 minutes', () => {
expect(minuteHandTransform).toBe('rotate(210deg)');
});
});
describe('Second', () => {
it('Renders at 90deg reflecting 30/60 seconds', () => {
expect(secondHandTransform).toBe('rotate(90deg)');
});
});
});
describe('Theme', () => {
it('Has the default theme set', () => {
expect(
/\btheme-default\b/).test(analogClockDOM.className)
).toBe(true);
});
});
});你可能会注意到,更简洁的方法要长得多,但当涉及到测试时,最好偏向于这种冗长的描述。 过度描述比描述不足要好,因为在后一种情况下,你的同事会缺乏信息,他们会挠头,对功能做出可能不正确的猜测。 当我们提供大量的清晰和解释时,我们是在帮助更广泛的同事和用户。 但是,如果我们的代码晦涩而简洁,那么我们就会限制能够理解代码的人员,从而限制了代码的可维护性和可用性。
现在我们已经探讨了工艺暴露最终清晰通过一个结构良好的测试套件,我们可以缩小,讨论我们如何沟通的目的和类型测试我们写作通过目录结构和文件命名约定。
*# 创建干净的目录结构
我们的测试套件通常应该局限于单个文件,以描述程序员同事关注的领域。 然而,将这些测试文件组织成更大的代码库的一致部分可能是一个挑战。
想象一个小的 JavaScript 代码库,目录结构如下:
app/
components/
ClockComponent.js
GalleryComponent.js
utilities/
timer.js
urlParser.js将与特定代码相关的测试放在靠近该代码所在位置的子目录中是非常典型的做法。 在我们的示例代码库中,我们可以创建以下tests子目录来包含components和utilities的单元测试:
app/
components/
ClockComponent.js
GalleryComponent.js
tests/
ClockComponent.test.js
GalleryComponent.test.js
utilities/
timer.js
urlParser.js
tests/
timer.test.js
urlParser.test.js下面是一些关于约定的额外注意事项,正如我们现在应该知道的,这些约定对于提高代码库的熟悉性和直观性以及整体整洁性至关重要:
- 测试有时被称为规格(规格)。 规范通常与测试没有什么不同,尽管作为名称,它在 BDD 范例中更受欢迎。 用你觉得舒服的。
- 通常会看到带有
.test.js或.spec.js后缀的测试文件。 这样,您的测试运行器就可以轻松地识别要执行哪些文件,这对我们的同事也是一个很有帮助的提醒。 - 测试目录的命名模式涉及下划线或其他非典型字符,例如
__tests__,这种情况并不少见。 这些命名模式通常用于确保这些测试不会被编译或打包为主要源代码的一部分,并且很容易被我们的同事识别。 - 端到端或集成测试通常放在较高的级别,这暗示它们依赖于多个部分。 看到一个高级的
e2e目录(或一些修改)是很常见的。 有时,集成测试被单独命名并存储在较高的级别; 其他时候,它们在整个代码库中穿插单元测试。
再次强调,层次结构是关键。 我们必须确保目录的层次结构有助于反映代码及其问题域的概念层次结构。 作为代码库中同等重要的一部分,测试应该小心而适当地放在代码库中,而不是事后才想到的。
在本章中,我们将测试的理论知识应用到构建真实的、可工作的、干净的测试套件的实践中。 我们研究了这样做存在的一些缺陷,并强调了需要努力争取的重要品质,如清晰、直观的命名和遵循约定。
在下一章中,我们将研究各种各样的工具,从检查器到编译器,我们可以用来帮助我们编写更干净的代码!****