- JavaScript 代码整洁指南
 PDF电子书集合
PDF电子书集合
JavaScript 基本类型和内置类型详解
到目前为止,我们已经从几个不同的角度探讨了干净代码的含义。 我们已经探索了我们编写的代码如何通过利用抽象来让用户使用显著的复杂性。 我们继续讨论了干净代码的原则,比如可靠性和可用性,以及追求这些目标时要注意的各种陷阱和挑战。
在本章中,我们将详细探讨 JavaScript 语言本身,包括更常见的语言结构和更模糊和令人困惑的方面。 我们将把我们积累的关于干净代码的知识应用到该语言的所有这些部分,并构建对 JavaScript 的理解,这完全是为了创建干净代码而定制的。
我们将从 JavaScript 最具原子性的部分开始:用作任何程序构建块的原始值。 然后,我们将继续讨论非基本值,即对象。 在我们对这些类型的探索中,我们将通过示例揭示使每种类型独一无二的语义以及在使用它们时要避免的陷阱。 我们在这一章学到的关键知识将在以后的章节中应用,因为我们将真正全面地了解如何用 JavaScript 编写干净的代码。
在本章结束时,你应该会对以下主题领域感到舒服:
JavaScript 中的基元类型是任何非对象的值,因此没有任何方法或属性。 JavaScript 中有七种基本类型:
- 数量
- 字符串
- 布尔
- 未定义的
- 零
- 长整型数字
- 象征
在本节中,我们将探讨这些原语之间的共同特征,并深入研究每一种类型,以了解它是如何工作的,以及在使用中存在哪些潜在的危险。 我们将了解 JavaScript 语言本身如何只是一组独特的抽象,当熟练使用时,可以轻松处理任何问题领域。
所有原始值都是不可变的,这意味着您不能改变它们的值。 这是它们原始本性的核心部分。 例如,不能将3.14的数字值更改为42,或将字符串的值更改为其大写变体。
But I can change the value of a string to its uppercased variation! You may be confused right now if you recall being able to do this. But there is a crucial distinction to be made here between the reassignment of variables to new primitive values, which is fully possible (and likely what you're remembering), and the mutation of primitive values, which is not possible.
当我们重新赋值一个变量时,给它一个新值,我们并没有改变这个值本身; 我们只改变变量所指的值,如下所示:
let name = 'simon';
let copy = name;
// Assign a new value to `name`:
name = name.toUpperCase();
// New value referred to by name:
name; // => "SIMON"
// Old value remains un-mutated:
copy; // => "simon"注意copy是如何保持小写的。 原始值simon未发生突变; 相反,通过toUpperCase方法从它派生出一个新的原始值,然后将其赋给先前持有小写变量的变量。
你会记得我们提到过,原始值没有方法,因为它们不是对象。 那么,我们如何才能在前面的字符串上调用toUpperCase呢? 这难道不是一种方法吗? 是的,它是。 为了允许我们访问这个方法,JavaScript 在属性访问时将原始值包装在各自的包装器对象中。 除null和undefined外,所有原始值都发生这种情况。
在这些被包装的时刻,原始值保持不变,但是通过它们被包装的实例,提供对属性和方法的访问。 字符串值将封装在String实例中,而数字值将封装在Number实例中。 同样的情况也会发生在所有其他非空和非未定义的原语上。 您可以自行实例化这些包装器对象:您将观察到它们的行为不再像原语; 它们是对象,因此,你可以添加和改变它们的属性:
const name = new String('James');
// We can add arbitrary properties, since it is an object:
// (Warning: this is an anti-pattern)
name.surname = 'Padolsey';
name.surname; // => "Padolsey"If you require an object to add custom properties to, it is best to use a plain object. Using wrapper objects for anything other than wrapping their primitive values is an anti-pattern as it would not be expected by other programmers. Nonetheless, it is useful to observe and remember the differences between primitives and their respective wrapper objects.
将包装器构造函数(例如,Number、String等)作为常规函数调用具有独特的行为。 它不会返回新的包装器实例,而是将值转换为特定类型并返回常规原语。 当你将一种类型转换为另一种类型时,这是非常有用的:
// Cast a number to a string:
String(123); // => "123"
// Cast a string to a number
Number("2"); // => 2
// Cast a number to a boolean
Boolean(0); // => false
Boolean(1); // => true正如我们在这里所做的那样,将包装器构造函数作为函数调用是一种有用的转换技术,尽管它不是唯一的一种。 我们将在第 7 章、动态类型中详细介绍类型转换和强制转换。
在 JavaScript 中,布尔上下文中的所有值都将被计算为true或false。 为了描述这种行为,我们通常将价值定义为真或假。 要确定一个值的真实性,我们可以简单地将它传递给Boolean函数:
Boolean('hi'); // => true
Boolean(0); // => false
Boolean(42); // => true
Boolean(0.1); // => true
Boolean(''); // => false
Boolean(true); // => true
Boolean(null); // => falseJavaScript 中只有 8 个伪值,而且都是原始类型:
nullundefined-
+0or-0(零,一个数) -
false(Boolean) -
""(空字符串) -
0n(0,aBigInt) -
NaN(不是数字)
因此,所有不假的价值观都是真实的。 在本章和下一章中,我们将探讨这些真伪价值的含义。 现在,重要的是要知道,前面的假值在条件或逻辑上下文中使用时,会表现得像假值一样。 例如,当在if语句中使用一个假值时,它的行为就像它是假的一样:
if (0) {
// This will not run. 0 is falsy.
}
if (1) {
// This will run. 1 is truthy.
}这些错误值的存在意味着我们必须警惕如何检查某些条件。 仅用某一值态的真实性来判断其存在性,很容易陷入检验某一值态是否存在的陷阱。 例如,假设我们需要能够检查一个人的年龄:
if (person.age) {
processIdentity(person);
}这是一个人为的例子,但我们可以想象一个系统,在这个系统中,个人的身份需要以某种方式进行处理,可能是通过医疗应用。 如果年龄恰好为 0,那么检查age属性的存在不会起到预期的作用。 也许系统需要迎合新生儿进入系统的可能性,但突然它崩溃了,因为age是0。 在这种情况下,最好先明确说明,即使你不期望奇怪的错误值。 在这种情况下,我们可能想要检查null或undefined,所以我们应该显式地这样做:
if (person.age === null || person.age === undefined) {
processIdentity(person);
}该代码对age属性的可能变异具有更强的弹性。 也许,我们还可以更符合我们的要求,只检查我们感兴趣的特定特征,例如年龄属性是特定范围内的一个数字。 要点是,在布尔上下文(如if语句)中最好是显式的,这样您就不会遇到意想不到的错误值。
数字基元类型用于表示数字数据。 它以双精度 64 位浮点格式(IEEE 754)存储该数据。 这里的 64 位指的是有 64 个二进制位来存储信息。 IEEE 754 标准中使用的 64 位格式可以分为三个部分:
- :数字是正的还是负的
- 11 位是数字的指数:这告诉我们基数或小数点在哪里
- 52 位表示分数或有效。:表示整数值
A side effect of this floating-point formation means that there are technically two zeros: positive zero (+0) and negative zero (-0). Thankfully, in JavaScript, you don't have to be explicit when checking for these values. Both will return true when compared with the strict equality operator ( +0 === -0) and both are considered falsy.
从技术上讲,整数值的表达式有 53 位可用(不是 52 位),因为 significant 和字段的前导位驻留在指数字段中。 这是一个很重要的澄清,因为它直接影响到我们能从 JavaScript 数字获得多少精度。 有 53 位可用来表示一个整数,这意味着任何大于253-1的数字都被认为是不安全的。 这些安全限制可以作为常量在Number对象上使用:
- 大于
2<sup>53</sup>或9007199254740991(Number.MAX_SAFE_INTEGER)的整数 - 小于
-2<sup>53</sup>或-9007199254740991(Number.MIN_SAFE_INTEGER)的整数
如果我们尝试在上限上执行加法,就可以观察到超出这些界限的精度损失:
const max = Number.MAX_SAFE_INTEGER;
max + 1; // => 9007199254740992 (correct)
max + 2; // => 9007199254740992 (incorrect)
max + 3; // => 9007199254740994 (correct)
max + 4; // => 9007199254740996 (incorrect)
// ... etc.在这里,我们可以看到,计算的加法是不正确的。 在MAX_SAFE_INTEGER之外,所有的数学运算将同样不精确。
It is still possible to express values larger than MAX_SAFE_INTEGER within JavaScript. Many values up to 2<sup>1024</sup> (Number.MAX_VALUE) can be expressed, but many cannot. Therefore, it is considered very unwise to attempt to express numbers beyond Number.MAX_SAFE_INTEGER.
总而言之,在Number.MIN_SAFE_INTEGER和Number.MAX_SAFE_INTEGER之间的任何值都是安全的,可以提供整数精度,而超过这些界限的值则被认为是不安全的。 如果我们觉得我们需要一个超出这些界限的整数,那么我们可以使用 JavaScript 的BigInt原语:
const max = BigInt(Number.MAX_SAFE_INTEGER)
max + 1n; // => 9007199254740992n (correct)
max + 2n; // => 9007199254740993n (correct)
max + 3n; // => 9007199254740994n (correct)
max + 4n; // => 9007199254740995n (correct)
// ... etc.我们将在本节的后面部分进一步探讨BigInt原语。 现在,只要记住要始终考虑你的数字的大小,以及它们是否能被 JavaScript 的Number类型完全容纳。 考虑十进制值(比如分数)的精度也很重要。 在 JavaScript 中表示小数时,你可能会遇到这样的问题:
0.1 + 0.2; // => 0.30000000000000004这是由于在浮点标准中表示分数的固有机制造成的。 你可以想象,如果我们想查询一个小数是否等于、大于或小于另一个值,它会像使用以下代码一样简单:
const someValue = 0.1 + 0.2;
if (someValue === 0.3) {
yay();
}但yay()永远不会跑。 要解决这个问题,有两个选择。 第一个包含一个叫做的东西。 是浮点数学固有的误差范围,JavaScript 将其用作Number.EPSILON:
Number.EPSILON; // => 0.0000000000000002220446049250313这是一个非常小的数,但如果我们希望对小数进行基本的数学运算,就必须考虑到它。 如果我们想比较两个数字,我们可以简单地将它们相减,并检查 margin 是否小于EPSILON:
const someValue = 0.1 + 0.2;
if (Math.abs(someValue - 0.3) < Number.EPSILON) {
// someValue is (effectively) equal to 0.3
}我们可以采用的另一种方法是将所处理的任何小数转换为用Number或BigInt类型表示的整数。 因此,如果我们需要用精确到 8 位的小数点来表示0到1的值,那么我们可以简单地将这些值乘以100,000,000(或10<sup>8</sup>):
const unwieldyDecimalValue = 0.12345678;
// We can use 1e8 to express Math.pow(10, 8)
unwieldyDecimalValue * 1e8; // => 12345678现在,我们可以自由地对这些值进行整数计算,并将它们分解成分数。 需要注意的是,任何大于 15 位的十进制值都不能用 JavaScript 的Number类型表示,所以您需要探索其他选项。 JavaScript 目前没有原生的BigDecimal类型,但有许多第三方库可以实现类似的目的(你可以很容易地在网上找到这些库)。
If you ever find yourself needing to operate on large or very precise numbers in JavaScript, or if your code concerns sensitive matters such as finance, medicine, or science, it's absolutely crucial to take the time to fully understand what levels of precision you require and whether JavaScript can natively support those needs.
在Number类型下还有一个话题要讨论,那就是NaN。 NaN是技术上属于Number类型的原语。 它表示无法将某些内容解析为数字; 例如,Number('wow')计算为NaN。 由于typeof NaN是一个number,我们应该用以下方法检查一个有效的数字:
if (typeof myNumber === 'number' && !isNaN(myNumber)) {
// Do something with your number
}当价值NaN的存在不可预见时,它会令人头痛。 它通常会在您试图将字符串转换为数字或隐式发生(强制)的地方出现。
We'll be covering the topic of coercion, casting, and detection more in the next chapter. This will include a section where we get into the complexity of NaN and compare isNaN(), the global function, to the slightly different Number.isNaN(). For now, it's only important to appreciate that NaN is its own distinct value and is itself, oddly, considered a number within JavaScript.
Number类型封装了另一个非正常数字:Infinity。 当你尝试做数学运算(如除以0)时,你会得到Infinity:
100/0; // => InfinityInfinity,像NaN一样,是一个全局可用的原始值,你可以引用和检查:
100/0 === Infinity; // => true还有-Infinity,这是一个技术上不同的值:
100/-0; // => -Infinity
-Infinity === Infinity; // => falseInfinity和NaN一样,是Number类型的,所以当传递给typeof操作符时,它将计算为"number":
typeof Infinity; // => "number"除Infinity、-Infinity、NaN外,所有Number类型的值均可视为日常规则数。 总的来说,对于大多数用例来说,Number类型的使用和操作非常简单。 然而,了解它的局限性是至关重要的,我们已经在这里介绍了其中的许多局限性,这样您就可以在不适合使用它的情况下做出明智的决定。
JavaScript 中的String类型允许我们表达字符序列。 它通常用于封装单词、句子、列表、HTML 和许多其他形式的文本内容。
字符串是用单引号、双引号或反引号分隔字符序列来表示的:
// Single quotes:
const name = 'Titanic';
// Double quotes:
const type = "Ship";
// Template literals (back-ticks):
const report = `
RMS Titanic was a British passenger liner that sank
in the North Atlantic Ocean in 1912 after the ship
struck an iceberg during her maiden voyage.
`;只有反标记分隔的字符串,称为模板字面量(或模板字符串),可以占用多行。 从技术上讲,单引号或双引号分隔的字符串也可以沿多行展开,但这只能通过转义它们的不可见换行符(使用\字符)来实现,这有效地删除了换行符:
const a = "example of a \
string with escaped newline \
characters";
const b = "example of a string with escaped newline characters";
a === b; // => true如今,模板字面量是首选,因为它们保留了换行符,并允许我们插入任意表达式,像这样:
const nBreadLoaves = 4;
const breadLoafCost = 2.40;
`
I went to the market and bought ${nBreadLoaves} loaves of
bread and it cost me ${nBreadLoaves * breadLoafCost} euros.
`一旦您的使用超过了最简单的用例,字符串就会带来许多奇怪的挑战。 在表面之下,这个不起眼的字符串以 Unicode 的形式掩盖了不可思议的复杂性。
Unicode is an industry standard for the encoding, representation, and handling of text that's used in writing systems around the world. The Unicode standard contains over 130,000 characters, including all of your favorite emojis.
稍微深入一下 String 抽象的表层,我们可以说 JavaScript 中的 String 实际上只是一个 16 位无符号整数的有序序列。 这些整数中的每一个都被解释为 UTF-16 编码单元。 UTF-16 是 Unicode 字符集的一种编码类型。 使用它,我们能够表达数十万个有效的 Unicode 代码点。 这意味着我们可以通过字符串来表达表情符号、多种语言和无数的 Unicode 奇怪现象:

一个 Unicode 编码点是一个字符(例如字母B,一个问号,或者一个微笑的表情)。 我们可以使用一个或多个 UTF-16 代码单元来表示代码点。 我们每天使用的大多数代码点只需要一个代码单元。 这些被称为标量。 但是,有相当多的 Unicode 代码点需要一对代码单元(称为代理对)。 熊猫表情就是这种替身组合的一个例子:

因为 UTF-16 只有 16 位可以处理,所以它必须使用 16 位整数对来表示某些字符。 当然,如果我们使用 UTF-32 编码(有 32 位来玩),那么我们就可以用一个 32 位整数来表达熊猫表情。
在这里,我们使用charCodeAt()确定个人熊猫 emoji utf - 16 编码单元,我们发现这些55357 年和【显示】56380 年小数在 Unicode 代码单元。 因为有很多代码单元,它更简单,更方便使用十六进制数字来表达它们,所以我们可以说熊猫 emoji 表示代码单元U+D83D和U+DC3C(Unicode 十六进制值传统前缀U+)。
除了代理对之外,还有另一种类型的组合值得了解。 结合码点使某些传统的非结合码点扩展为新的字符。 这方面的例子包括传统的拉丁字符,可以用重音或其他增强,如合并波浪线:

我们选择通过 Unicode 转义序列(\u0303)来表示这个特殊的组合字符。 \uXXXX的格式允许我们在 JavaScript 字符串中表达U+0000和U+FFFF之间的 Unicode 代码单位。
The range of Unicode between U+0000 and U+FFFF is known as the Basic Multilingual Plane (BMP) and includes the most commonly used everyday characters.
我们的熊猫表情,正如我们已经看到的,是一个相当晦涩的符号。 它不存在于 BMP 上,因此由两个 UTF-16 代码单元的代理对表示。 我们可以通过两个 Unicode 转义序列在 JavaScript 字符串中分别表示它们:
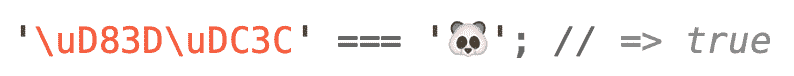
在U+010000和U+10FFFF之间的辅助(或星光)面中发现了更多模糊和古老的符号。 \uXXXX的转义格式没有足够的槽位来表达。 星体层中的符号至少需要 5 个十六进制数字来表示,所以我们必须使用最近引入的\u{X}转义序列格式。 这提供了最多 6 个十六进制槽(\u{XXXXXX}),因此可以表示超过 100 万个不同的代码点。 使用这种转义序列,我们可以通过 32 位符号直接表达熊猫表情(U+1F43C):
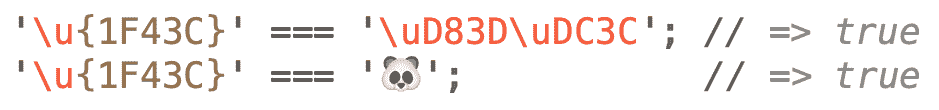
新的\u{X}转义序列确实很方便,在某种程度上使 Unicode 比 JavaScript 使用起来更轻松。 但还有一些更复杂的东西需要探索。 代理对和组合字符是将 UTF-16 代码单元组合起来生成单个符号的例子。 除此之外,还有更长的序列,称为字素簇。 这些符号用于表示可以组合起来创建聚合符号的代码点的组合:

哇! Unicode 是一个相当令人难以置信的工程壮举,但它会让我们的事情变得复杂。 以所有这些方式组合 Unicode(组合字符、代理对和字母组)的能力给我们带来了挑战。 JavaScript 字符串,你可能知道,有一个length属性。 该属性返回给定字符串中的代码单元数(即整个序列中的 16 位整数数)。 对于大多数字符串,这很简单:
'fox'.length; // => 3
'12345'.length; // => 5然而,正如我们所知,我们能够组合代码单元来创建代码点,我们也能够组合代码点来创建字素集群。 这意味着只与 16 位代码单元有关的length属性会给我们带来意想不到的结果:

这个笑脸表情由两个代码单元组成,所以 JavaScript 正确地告诉我们这个字符串的长度为2。 但这可能不是我们所期望或渴望的。 当我们处理可能使用十几个不同的代码单元来表示一个符号的字素集群时,这就更有挑战性了。
Watch out when attempting to truncate or establish the width of a piece of text within a UI using only its length property. Due to the fact that many Unicode symbols may be expressed by multiple code units, using length alone is not reliable.
在本节中,我们探索了复杂的 Unicode 领域。 通过我们对它的新理解,我们现在更有能力在 JavaScript 中干净地处理字符串。 除去 Unicode 的复杂性,JavaScript 中的字符串的行为是相当直观的,只要我们以一种清楚地传达我们意图的方式使用它们,就不会引起很多麻烦。
JavaScript 中的Boolean基元类型用来表示true或false。 这两个极端的对立是它唯一的价值:
const isTrue = true;
const isFalse = false;从语义上讲,布尔值用于表示现实生活或问题域的值,这些值可以被考虑为开启或关闭(0或1),例如,是否启用了某个特性,或者用户是否超过了某个年龄。 这些都是布尔特征,因此可以通过布尔值来表达。 我们可以使用这些值来指示程序中的控制流:
const age = 100;
const hasLivedTo100 = age >= 100;
if (hasLivedTo100) {
console.log('Congratulations on living to 100!');
}Boolean原语,就像String和Number一样,可以手动包装在包装器实例中,如下所示:
const isTrueObj = new Boolean(true);注意,一旦你这样做了,Boolean的行为将与条件语句中的任何其他对象一样。 因此,下面的条件语句将成功执行,即使包装的原语值是false:
const isFalseObj = new Boolean(false);
if (isFalseObj) {
// This will run
}这里的Boolean实例不等于它的原始值; 它只包含它的原始值。 isFalseObj的行为将与Boolean上下文中的任何其他对象一样,解析为true。 像这样手工包装Boolean并不是特别有用,应该避免在大多数程序中作为反模式使用,因为它的行为不符合布尔语义,可能会产生意想不到的结果。
Boolean primitives are returned by JavaScript's logical operators such as greater than or equal to (>=) or strict equality (===). We'll cover these in more detail in Chapter 8,Operators.
JavaScript 中的BigInt基元类型用来表示任意精度的整数。 这意味着它可以用来表示不能被 JavaScript 的Number类型精确表示的整数(任何大于~253的整数)。 字面值的 bigint 类型是通过在任何数字序列后面加上n字符来声明的,如下所示:
100007199254740991nBigInt能够表示任意精度的整数,这意味着您可以存储无限长度的整数。 这在金融应用或任何需要表达和操作高精度整数的情况下特别有用。
ABigInt只能操作自己,因此与 JavaScript 的许多本机Math方法不兼容:
Math.abs(1n); // !! TypeError: Cannot convert a BigInt value to a number只要两个操作数的类型相同,所有的原生数学运算符都可以使用BigInt:
(1n + (2n * 3n)) + 4n; // => 11n然而,如果一个操作数是BigInt,另一个是Number,那么您将收到TypeError:
1n + 1; // !! TypeError: Cannot mix BigInt and other types, use explicit conversionsBigInt的语义类似于Number:任何直观的数字值,可以表示为整数,都可以存储在BigInt或Number中,这取决于所需的精度。
一个Symbol原语用来表示一个完全唯一的值。 通过调用Symbol函数创建符号,如下所示:
const totallyUniqueKey = Symbol();您可以选择传递一个初始参数给这个函数,以注释您的符号,以满足您自己的调试目的,但这不是必需的:
const totallyUniqueKey = Symbol('My Special Key');在需要唯一性或希望在对象上存储元数据的地方,符号被用作属性键。 当您使用Symbol键向对象添加属性时,一般的对象迭代方法(如for...in)不会对其进行迭代。 对象的Symbol键只能通过Object.getOwnPropertySymbols获取:
const thing = {};
thing.name = 'James';
thing.hobby = 'Kayaking';
thing[Symbol(999)] = 'Something else entirely';
for (let key in thing) console.log(key);
// => "name"
// => "hobby"
const symbols =
Object.getOwnPropertySymbols(thing); // => [Symbol(999)]
thing[symbols[0]]; // => "Something else entirely"由于Symbol键以显式但隐藏的方式存在,它们在语义上存储与对象的核心数据无关的编程信息时很有用,但在满足某些编程需求时很有用。 例如,您可能有一个日志库,并且希望使用以特定方式进行日志记录的自定义呈现函数来注释特定对象。 这种需要可以很容易地用符号来满足:
const log = thing => {
console.log(
thing[log.CUSTOM_RENDER] ?
thing[log.CUSTOM_RENDER](thing) :
thing
);
};
log.CUSTOM_RENDER = Symbol();
class Person {
constructor(name) {
this.name = name;
this[log.CUSTOM_RENDER] = () => {
return `Person (name = ${this.name})`;
};
}
}
log(123); // => Logs "123"
log(new Person('Sarah')); // => Logs: "Person (name = Sarah)"
log(new Person('Wally')); // => Logs: "Person (name = Wally)"
log(new Person('Julie')); // => Logs: "Person (name = Julie)"需要创造和使用新符号的日常情况并不多,但用这些符号规定本土行为的例子却很多。 例如,可以使用Symbol.iterator属性为对象定义自定义迭代器。 我们将在本章后面的数组和可迭代对象一节中更详细地讨论这一点。
null原语类型用于表示有意没有值。 这种类型只有一个值:唯一的空值是null。
null与undefined的语义有很大的不同。 undefined值用于表示未声明或定义的内容,而null是显式声明的缺席值。 我们通常使用null值来表示某个值要么显式地尚未设置,要么由于某种原因不可用。
例如,让我们考虑一个 API,其中我们指定了与餐厅评论相关的各种属性:
setRestaurantFeatures({
hasWifi: false,
hasDisabledAccess: true,
hasParking: null
});在本例中,null值表示我们还不知道hasParking的值。 当我们有必要的信息时,我们可以将hasParking指定为true或false(Boolean),但为了表达我们对其真实值的无知,我们将其设置为null。 我们也可以完全忽略这个值,这意味着它实际上是undefined。 关键的区别是,使用null总是主动完成的,而undefined是未完成的结果。
正如我们前面提到的,null值总是假的,这意味着它在Boolean环境中总是被计算为false。 因此,如果我们试图在条件语句中使用null,则不会成功:
function setRestaurantFeatures(features) {
if (features.hasParking) {
// This will not run as hasParking is null
}
} 检查我们想要的准确值是很重要的,这样我们就可以避免错误并有效地与阅读我们代码的人交流。 在这种情况下,我们可能希望显式地检查undefined和null,因为我们希望针对该情况执行与false不同的代码。 我们可以这样做:
if (features.hasParking !== null && features.hasParking !== undefined) {
// hasParking is available...
} else {
// hasParking is not set (undefined) or unavailable (null)
}我们还可以使用抽象相等运算符(==)来比较null,如果操作数是null或undefined,那么null的值将有助于求出true:
if (features.hasParking != null) {
// hasParking is available...
} else {
// hasParking is not set (undefined) or unavailable (null)
}实际上,这与更明确的比较是相同的,但要简洁得多。 不幸的是,它的目的不是很清楚,它是检查null和undefined。 我们通常更喜欢明确的表达,因为这可以让我们以更有效的方式与其他程序员交流我们的意图。
使用 null 要避免的最后一个陷阱是typeof运算符。 由于 JavaScript 语言的一些遗留问题,typeof null会返回"object",因此是完全不可靠的。
More information about typeof and detection of the null type can be found in Chapter 7, Dynamic Typing, in the Detection section.
所以,这就是答案。 Null 是一个足够简单的值,就干净的代码而言,如果您记住两个关键点,就不会出错:它只应该用于表示有意没有值的情况,并且在理想情况下,应该显式地检查它(最好是value === null)。
undefined基元类型表示某事物尚未定义或仍未定义。 像null一样,它是一个只有一个值(undefined)的类型。 与null不同的是,不应该显式设置undefined值,但当某些内容没有值时,可以由语言返回:
const coffee = {
type: 'Flat White',
shots: 2
};
coffee.name; // => undefined
coffee.type; // => "Flat White"未定义最好被认为是缺少某物。 如果您发现自己希望显式地将某项设置为undefined,那么您可能应该使用null。
区分未定义和未声明的概念是很重要的。 在 JavaScript 中,如果你试图计算一个不在你的范围内的标识符,你会得到一个ReferenceError:
thisDoesNotExist; // !! ReferenceError: thisDoesNotExist is not defined但是,正如您已经看到的,如果您试图计算一个对象的属性,而该属性不存在,则不会得到这样的错误。 相反,它将计算为undefined:
const obj = {};
obj.foo; // => undefined然而,如果你试图访问一个不存在的foo属性下的属性,你会收到一个TypeError报错,它不能读取一个具有undefined值的属性:
obj.foo.baz; // !! TypeError: Cannot read property 'baz' of undefined这种行为是对以下事实的扩展:试图访问undefined或null值上的任何属性总是会抛出这样的TypeError:
(undefined).foo; // !! TypeError: Cannot read property 'foo' of undefined奇怪的是,undefined值与null不同,它不是文字,而是语言提供的全局可用值。 在 ECMAScript 2015 之后,覆盖这个全局值是不可能的,但仍然可以在本地(非全局)作用域为未定义的标识符定义自己的值:
undefined; // => undefined
function weird() {
let undefined = 1;
undefined; // => 1
}这是一个反模式,因为它可能会产生非常尴尬和意想不到的结果。 在大于您的范围的范围中偶然设置undefined可能意味着,如果您要直接依赖该值,则可能最终引用的是undefined以外的值。 从历史上看,对undefined价值缺乏信任意味着人们已经找到了其他方法,在他们的范围内强制使用undefined。 例如,声明一个变量但不赋值总是会导致其值为undefined:
function scopeWithReliableUndefined() {
let undefined;
undefined; // => undefined
}你也可以使用 JavaScript 的void操作符来处理任何总是返回real未定义值的值:
void 0; // => undefined
void null; // => undefined
void undefined; // => undefined在您的范围内显式设置 undefined 意味着您可以安全地参考您的undefined值,而不必担心它已被破坏。 然而,幸运的是,您可以通过使用typeof操作符来避免不得不担心这种风险的痛苦:
if (typeof myValue === 'undefined') { ... }即使myValue不存在,也不会抛出ReferenceError。 正如我们在null中发现的那样,typeof操作符有点像不能共患难的朋友,因为我们不能总是依赖它,但当显式地检查undefined时,它还是非常有用的。
Another way to avoid the risk of undefined is to enforce its correct usage within your code base by using a linting tool. We'll cover linting tools in Chapter 15, Tools for Cleaner Code.
综上所述,如果你记住以下两点,undefined就可以干净的使用:
- 避免将
undefined直接赋给变量; 你应该用null代替 - 总是显式地检查
undefined,选择typeof操作符
这就是我们对 JavaScript 中基本类型的探索。 现在,我们将继续讨论非原语,即对象。
在 JavaScript 中,所有不是原始值的东西都可以被视为对象。 事实上,即使函数也是专门的对象; 它们唯一的区别是它们可以被调用。 然而,通常当我们使用术语Object时,我们指的是一个普通对象,它通常声明为一个由花括号分隔的对象字面量,其中包含一组键值对:
const animal = {
name: 'Duck',
hobby: 'Paddling'
};你也可以通过Object构造函数实例化一个对象,然后直接添加属性:
const animal = new Object();
animal.name = 'Duck';
animal.hobby = 'Paddling';尽管它们是等价的,但在大多数情况下最好使用对象字面量,因为它更容易声明和读取,特别是在有许多属性的情况下。 它还有一个额外的好处,即允许您创建一个对象并将其作为表达式传递,而无需事先准备它。
用于向对象添加属性(属性名)的键在内部存储为字符串。 然而,当使用对象字面量语法时,你可以将键声明为常规标识符(也就是说,任何你可以用作变量名的东西)、数字字面量或字符串字面量:
const object = {
foo: 123, // Using an identifier as the key
"baz": 123, // Using a String literal as the key
123: 123 // Using a Number literal as the key
};最好在可能的情况下使用标识符,因为这有助于限制您使用容易作为属性访问的键名。 如果你使用的字符串字面值不是一个有效的标识符,那么你将不得不使用方括号符号来访问它,这可能会很麻烦:
const data = {
hobbies: ['tennis', 'kayaking'],
'my hobbies': ['tennis', 'kayaking']
};
data.hobbies; // Easy
data['my hobbies']; // Burdensome还可以使用计算属性名(由方括号分隔)向对象字面量添加动态命名的项:
const data = {
['item' + (1 + 2)]: 'foo'
};
data; // => { item3: "foo" }
data.item3; // => "foo"正如我们前面提到的,JavaScript 中的所有非原语在技术上都是对象。 还有什么能让一个物体成为物体呢? 对象允许我们将任意值作为属性赋给它们,这是原语无法做到的。 除了这个特征之外,JavaScript 中对象的定义是非常泛型的。 我们可以用许多不同的方式来使用对象,以适应我们正在编写的代码。 许多语言将提供字典或散列映射的语言构造。 在 JavaScript 中,我们可以使用对象来满足大部分需求。 当我们需要使用存储键值对(其中键不是字符串)时,通常会通过对象的toString方法提供该值的字符串表示:
const me = {
name: 'James',
location: 'England',
toString() {
return [this.name, this.location].join(', ')
}
};
me.toString(); // => "James, England"
String(me); // => "James, England"当对象被放到一个强制转换为字符串的上下文中时,例如通过方括号符号访问或赋值时,将在内部调用 This:
const peopleInEurope = {};
peopleInEurope[me] = true;
Object.keys(peopleInEurope); // => ["James, England"]
peopleInEurope[me]; // => true这在历史上被用于实现键是非原语的数据结构(即使从技术上讲对象将属性名存储为字符串)。 然而,现在使用Map或WeakMap更受欢迎。
当以常规方式向对象添加属性时,无论是通过属性访问还是通过对象字面量,属性将被赋予以下隐式特征:
-
configurable:这意味着属性可以从对象中删除(如果它的属性描述符可以更改) -
enumerable:这意味着该属性对for...in和Object.keys()等枚举是可见的。 -
writable:这意味着属性的值可以通过赋值操作符(如obj.prop = ...)来更改。
JavaScript 提供了单独关闭这些特征的功能,但要小心,这些特征的更改可能会模糊代码的行为。 例如,如果一个属性被描述为不可写,但是通过赋值尝试写(例如,obj.prop = 123),那么程序员将不会收到写没有发生的警告。 这可能会产生意想不到的、难以发现的 bug。 与以往一样,记住将使用您的接口的程序员的期望是至关重要的。 所以你要小心谨慎地使用属性描述符。
你可以通过本地提供的Object.defineProperty()定义你自己的属性。 设置一个新的属性描述符时,默认的特质将false,所以如果你想给房地产的特征configurable,enumerable,writable,那么你将需要显式地指定这些true:
const myObject = {};
Object.defineProperty(myObject, 'name', {
writeable: false,
configurable: false,
enumerable: true,
value: 'The Unchangeable Name'
});
myObject.name; // => "The Unchangeable Name"
myObject.name = 'something else'; // => (Ineffective)
myObject.name; // => "The Unchangeable Name"
delete myObject.name; // => false (Ineffective)
myObject.name; // => "The Unchangeable Name"你也可以用Object.defineProperties()同时描述多个属性:
const chocolate = Object.defineProperties({
// Empty object where our described properties
// will be placed
}, {
name: { value: 'Chocolate', enumerable: false },
tastes: { value: ['Bitter', 'Sweet'], enumerable: true }
});
chocolate.name; // => "Chocolate"
chocolate.tastes; // => ["Bitter", "Sweet"]
Object.keys(chocolate); // => ["tastes"]如果你试图改变一个属性的configurable设置为false,那么你会收到TypeError:
const obj = {};
Object.defineProperty(
obj,
'timestamp',
{ configurable: false, value: Date.now() }
);
Object.defineProperty(
obj,
'timestamp',
{ configurable: true }
);
// ! TypeError: Cannot redefine property: timestamp也可以设置自定义的 setter 和 getter。 getter 定义访问属性时返回的值,而 setter 定义对该属性进行赋值(即通过赋值操作符)时会发生什么。 当你希望有一个内部实现以独特的方式保存值,或以某种方式在赋值时过滤或处理值时,使用这些可以很有用,例如:
const data = Object.defineProperties({}, {
name: {
set(name) { this.normalizedName = name.toLowerCase(); },
get() { return this.normalizedName; }
}
});
data.name = 'MoLLy BroWn';
data.name; // => "molly brown"由于这里的name属性已经通过defineProperties进行了描述,它将禁用所有默认特征,这意味着它是不可枚举的,可写的,或可配置的。 如果我们试图枚举它,我们会发现我们内部使用的normalizedName被找到了:
Object.keys(data); // => ["normalizedName"]在使用属性描述符时要记住这一点。 确保你知道每个属性都有什么特征,并注意你的内部实现的泄漏!
值得注意的是,在对象字面量或类定义中直接定义属性的 getter 和 setter 也是可能的(通常是更好的)。 例如,我们可以通过添加last属性来创建Array的子类,该属性作为数组中最后一个元素的 getter:
class SpecialArray extends Array {
get last() { return this[this.length - 1]; }
}
const myArray = new SpecialArray('a', 'b', 'c', 'd');
myArray.last; // => "d"
myArray.push('e');
myArray.last; // => "e"有许多 getter 和 setter 的创造性用法。 但是,与configurable、enumerable和writable的特性一样,必须谨慎地注意您的自定义行为将如何影响其他程序员的期望。 如果您创建的抽象或数据结构的行为不熟悉或不可预测,那么您就为误解和错误铺平了道路。 最好的方法是与语言本身的自然语义保持一致。 因此,每当您准备创建一个自定义 setter 或将一个属性描述为不可写时,请问问自己,程序员期望它以这种方式工作是否合理。 遵循一个有用的规则,被称为Principle of Least surprise(POLA)!
The POLA (or least surprise) applies to software design and UX design. It broadly means that a given function or component of a system should act as most users would expect it to and should seek not to surprise or astonish too much.
Map和WeakMap抽象能够存储键-值对,与常规对象不同,键可以是任何东西,包括非原始值:
const populationBySpecies = new Map();
const reindeer = { name: 'Reindeer', formalName: 'Rangifer tarandus' };
populationBySpecies.set(reindeer, 2000000);
populationBySpecies.get(reindeer); // => 2,000,000WeakMap``Map类似,但它只持有一个弱引用的对象作为密钥,这意味着,如果被垃圾收集的对象变得不可用,因为在程序的其他地方,然后WeakMap将不再继续持有。
大多数时候,您只需要一个普通对象。 只有在需要非原始键或希望弱保存值时,才应该使用Map或WeakMap。
JavaScript 是一种通过原型实现继承的原型语言。 这可能是一个令人生畏的概念,但事实上,它非常简单。 JavaScript 的原型行为可以这样描述:每次访问一个对象的属性时,如果它在对象本身不可用,JavaScript 将尝试通过一个内部可用的属性[[Prototype]]访问它。 然后它将重复这个过程,直到找到属性或到达原型链的顶部并返回undefined。
Understanding what this [[Prototype]] property is capable of will give you great power over the language and will immediately make JavaScript less daunting. It can be difficult to grasp but is worth it in the end.
一个可以附加到任何其他对象上的对象本身只是一个普通对象。 我们可以创建一个名为engineerPrototype的函数,并让它包含与工程师角色相关的数据和方法,例如:
const engineerPrototype = {
type: 'Engineer',
sayHello() {
return `Hello, I'm ${this.name} and I'm an ${this.type}`;
}
};然后,我们可以将这个原型附加到另一个对象上,从而使其属性也可用。 为此,我们使用Object.create(),它用硬编码的[[Prototype]]创建一个新对象:
const pandaTheEngineer = Object.create(engineerPrototype);The internal [[Prototype]] property cannot be directly set, so we must use mechanisms such as Object.create and Object.setPrototypeOf. Note that you may have seen code that uses the non-standard __proto__ property to set [[Prototype]], but this is a legacy feature and should not be relied on.
使用这个新创建的pandaTheEngineer对象,我们可以访问它的[[Prototype]]上可用的任何属性,例如engineerPrototype:
pandaTheEngineer.name = 'Panda';
pandaTheEngineer.sayHello(); // => "Hello, I'm Panda and I'm an Engineer"我们可以通过添加一个新的属性到engineerPrototype来说明对象现在是链接的,并观察它是如何在pandaTheEngineer上可用的:
pandaTheEngineer.sayGoodbye; // => TypeError: sayGoodbye is not a function
engineerPrototype.sayGoodbye = () => 'Goodbye!';
pandaTheEngineer.sayGoodbye(); // => 'Goodbye!'正如我们前面提到的,对象的[[Prototype]]只用于解析对象本身不可用的属性。 下面的代码演示了如何在pandaTheEngineer对象上设置自己的sayHello方法,这样我们就不能再访问[[Prototype]]上定义的sayHello方法了:
pandaTheEngineer.sayHello = () => 'Yo!';
pandaTheEngineer.sayHello(); // => "Yo!"然而,删除这个新添加的sayHello方法将意味着我们再次访问[[Prototype]]``sayHello方法:
delete pandaTheEngineer.sayHello;
pandaTheEngineer.sayHello(); // => // => "Hello, I'm Panda and I'm an Engineer"为了理解发生了什么,哪些属性来自于哪个对象,我们总是能够使用Object.getPrototypeOf来检查对象的[[Prototype]]:
// We can inspect its prototype:
Object.getPrototypeOf(pandaTheEngineer) === engineerPrototype; // => true现在,我们可以通过Object.getOwnPropertyNames检查它的属性:
Object.getOwnPropertyNames(
Object.getPrototypeOf(pandaTheEngineer)
); // => ["type", "sayHello", "sayGoodbye"]在这里,我们可以看到,[[Prototype]]对象(即engineerPrototype)提供了type、sayHello,、sayGoodbye属性。 如果我们检查pandaTheEngineer对象本身,我们可以看到它只有一个name属性:
Object.getOwnPropertyNames(pandaTheEngineer); // => ["name"]正如我们之前添加的sayGoodbye方法所观察到的,我们可以在任何时候修改原型,并让使用该原型的任何对象都可以访问我们的更改。 下面是另一个例子:
// Modify the prototype object:
engineerPrototype.type = "Awesome Engineer";
// Call a method on our object (that uses the prototype):
pandaTheEngineer.sayHello(); // => "Hello, I'm Panda and I'm an Awesome Engineer"在这里,您可以看到我们继承的sayHello方法如何产生一个包含我们的突变类型属性(即"Awesome Engineer")的字符串。
Hopefully, you are beginning to see how we could construct a hierarchy of inheritance using prototypes. The very simple mechanism of [[Prototype]] allows us to express complex hierarchical relations between problem domains expressed as objects. This is how OOP is achieved in JavaScript.
我们可以创建另一个原型,它本身使用engineerPrototype,也可能是fullStackEngineerPrototype,并且它将按照预期工作,每个原型定义另一层属性解析。
在表面之下,JavaScript 较新的类定义语法(您可能已经习惯了)也依赖于这种底层的原型机制。 这可以在这里看到:
class Engineer {
type = 'Engineer'
constructor(name) {
this.name = name;
}
sayHello() {
return `Hello, I'm ${this.name} and I'm an ${this.type}`;
}
}
const pandaTheEngineer = new Engineer();
Object.getOwnPropertyNames(pandaTheEngineer); // => ["type", "name"]
Object.getOwnPropertyNames(
Object.getPrototypeOf(pandaTheEngineer)
); // => ["constructor", "sayHello"]您会注意到这里有一些细微的差别。 最关键的一点是,在声明类时,目前还没有办法在原型对象上定义非方法属性。 当我们声明type属性时,我们是在填充实例本身,因此当我们检查实例的属性时,我们得到"type"和"name"。 但是,在[[Prototype]]上存在方法(如sayHello)。 当然,另一个区别是,当使用类时,我们可以声明一个constructor,它本身是[[Prototype]]上的一个方法/属性。
Fundamentally, the Class Definition Syntax (introduced in ECMAScript 2015), does not make anything possible that was not already possible in the language. It's just utilizing the existing prototypical mechanism. However, the newer syntax does make some things simpler, such as referring to a superclass with the super keyword.
在类定义存在之前,我们通常通过将预期的[[Prototype]]对象赋值给函数的prototype属性来编写类抽象,如下所示:
function Engineer(name) {
this.name = name;
}
Engineer.prototype = {
type: 'Engineer',
sayHello() {
return `Hello, I'm ${this.name} and I'm an ${this.type}`;
}
};当一个函数通过new操作符实例化时,JavaScript 会隐式地创建一个新对象,对象的[[Prototype]]设置为函数的prototype属性(如果有的话)。 让我们试着实例化Engineer函数:
const pandaTheEngineer = new Engineer();我们在原始的Object.create方法中看到了同样的特征:
Object.getOwnPropertyNames(pandaTheEngineer); // => ["name"]
Object.getOwnPropertyNames(
Object.getPrototypeOf(pandaTheEngineer)
); // => ["type", "sayHello"]总的来说,所有这些方法都是相同的,但在某些属性驻留的位置上有一些细微的差别(即,它的属性是在实例本身上还是在它的[[Prototype]]上)。 更新的类定义语法很有用,也很简洁,所以在今天更受欢迎,但是当原型驱动整个语言(包括它的所有本机类型)时,了解它是如何工作的还是很有用的。 我们可以用与前面代码相同的方式检查这些本机类型:
const array = ['wow', 'an', 'array'];
Object.getOwnPropertyNames(array); // => ["0", "1", "2", "length"]
Object.getOwnPropertyNames(
Object.getPrototypeOf(array)
); // => ["constructor", "concat", "find", "findIndex", "lastIndexOf", "pop", "push", ...]Mutating native prototypes is an anti-pattern and should be avoided at all costs as it can create unexpected conflicts with other code in your code base. Since a runtime will only have a single set of native types available, when you modify them, you are modifying the capabilities of every single instance of that type that currently exists. Therefore, it is best to abide by a simple rule: only modify your own prototypes.
如果你发现自己试图修改一个本地原型,最好是创建自己的子类,并在那里添加你的功能:
class HeartArray extends Array {
join() {
return super.join(' ❤ ');
}
}
const yay = new HeartArray('this', 'is', 'lovely');
yay.join(); // => "this ❤ is ❤ lovely"在这里,我们创建自己的Array子类,称为HeartArray,这样我们就可以添加自己专门的join方法。
任何类型的对象,就像我们的原始值一样,应该只与它所代表的语义概念内联使用。 前面将Array子类化为HeartArray是有意义的,因为我们希望通过它表示的数据确实是类似数组的,也就是说,它是一组连续的单词。
当我们着手将对象建模成符合我们需求的抽象时,我们应该始终考虑其他程序员对对象的期望以及这些期望的结果。 我们将在第 11 章,设计模式,中深入探讨设计好的抽象的微妙之处,我们将利用对象以多种方式来制作抽象。
本节向您介绍了 javascript 中对象的概念——它们如何无处不在——以及它们如何通过原型在表面之下进行操作。 这些基本知识将使使用 JavaScript 更容易,并帮助您编写更清晰的代码。
JavaScript 中的函数与其他类型一样; 它们可以像对象和基本类型一样被传递。 然而,当我们讨论大多数其他值时,我们看到通常只有一种方法字面上声明它们。 对象字面值使用大括号声明。 数组字面值用方括号分隔。 然而,函数有多种字面形式。
在对象字面量或类定义之外,可以用三种不同的方式声明函数:作为函数声明,作为函数表达式,或作为胖箭头函数表达式:
// Function Declaration
function myFunction() {}
// Function Expression
const myFunction = function () {};
// Named Function Expression
const myFunction = function myFunction() {};
// "Fat"-Arrow Function Expression
const myFunction = () => {};然而,在对象字面量中声明函数时,有一种更简洁的语法,称为方法定义:
const things = {
myMethod() {},
anotherMethod() {}
};我们需要用逗号分隔这些方法定义(就像在对象字面量中定义的任何其他属性一样)。 类定义也允许我们使用方法定义,尽管它们不需要分隔逗号:
class Thing {
myMethod() {}
anotherMethod() {}
}Methods are just functions that are bound to an object when invoked. This includes functions defined within class definitions and functions that are in any way assigned to a property of an object. When discussing code with other programmers, it's useful to know what people mean when they say method versus function. Fundamentally, however, the language of JavaScript does not distinguish between these—they are all technically just functions.
所有定义函数的不同方法都有细微的差别,值得了解,因为典型的 JavaScript 代码库将使用这些样式中的大部分(如果不是全部的话)。 在如何声明函数方面,你将遇到的不同类型包括:
- 定义样式是否提升至其范围的顶部; 例如,函数声明
- 定义样式是否创建有自己绑定的函数(例如,
this); 例如,函数表达式 - 定义样式是否使用自己的
name属性创建函数; 例如,函数声明 - 定义样式是否与代码的特定区域相关联; 例如,方法定义
现在,我们可以更详细地了解各种定义样式的语法。
函数可以存在于三种语法上下文中:
- 作为一个声明
- 作为一个表达式
- 作为方法定义
Statements can be thought of as the scaffolding. For example, const X = 123 is a Statement that contains a const declaration and assignment. Expressions can be thought of as the values that you place into the scaffolding; for example, 123 in the latter statement is an expression. In Chapter 9, *Parts of Syntax and Scope*, we'll talk about this topic in more detail.
函数作为语句和函数作为表达式之间的区别可以通过函数表达式和函数声明来说明。 函数声明是非常独特的,因为它是声明一个从技术上讲是语句的函数的唯一方法。 要被认为是一个函数声明,function name() {}的语法必须独立存在,而不能在表达式上下文中使用。 这可能令人难以置信地困惑,因为你不能总是根据一个函数本身的语法来判断它是一个函数声明还是函数表达式; 相反,你必须查看它存在的上下文:
// This is a statement, and a function declaration:
// And will therefore be hoisted:
function wow() {}
// This is a statement containing a function expression:
const wow = function wow() {};正如我们前面提到的,函数表达式允许有一个名称,就像函数声明一样,但是这个名称可能与函数赋值的变量的名称不匹配。
最简单的方法是将表达式看作是在赋值操作符右边合法存在的任何东西。 右手边均为合法表达式:
foo = 123;
foo = [1,2,3];
foo = {1:2,3:4};
foo = 1 | 2 | 3;
foo = function() {};
foo = (function(){})();
foo = [function(){}, ()=>{}, function baz(){}];就语法位置而言,函数表达式和 JavaScript 中的其他值一样灵活。 我们将会发现,函数声明是有限的。 方法定义也仅限于存在于对象字面量或类定义的范围内。
*# 函数绑定
函数的绑定引用了一组额外的隐式值,JavaScript 让这些值可以在函数体中引用。 这些绑定包括以下内容:
-
this:关键字this是指函数调用的执行上下文 -
super:方法或构造函数中的super关键字指向它的超类 -
new.target:这个绑定告诉你函数是否作为构造函数被调用(通过new操作符) -
arguments:该绑定提供了对函数调用时传递给函数的参数的访问
除了那些用箭头语法(fn = () => {})定义的函数外,所有函数都可以使用这些绑定。 以这种方式定义的函数将有效地吸收来自父作用域的绑定(如果有的话)。 每个绑定都有独特的行为和约束。 我们将在以下小节中探讨这些问题。
this关键字通常在函数调用时确定,通常解析为调用函数的对象。 它有时被称为一个函数或其thisArg的执行上下文。 这可能不太直观,因为这意味着this值在调用之间可以进行技术上的更改。 例如,我们可以将一个方法从一个对象分配给另一个对象,在第二个对象上调用它,观察它的this始终是调用它的对象:
const london = { name: 'London' };
const tokyo = { name: 'Tokyo' };
function sayMyName() {
console.log(`My name is ${this.name}`);
}
sayMyName(); // => Logs: "My name is undefined"
london.sayMyName = sayMyName;
london.sayMyName(); // => Logs "My name is London"
tokyo.sayMyName = sayMyName;
tokyo.sayMyName(); // => Logs "My name is Tokyo"当在没有调用对象的情况下调用时,就像我们直接调用sayMyName一样,它的假定执行上下文是代码所在的全局环境。 在浏览器上,这个全局环境等于 window 对象(它提供了对浏览器和文档对象模型的访问),而在 Node.js 中,它指的是每个特定模块/文件唯一的环境,其中包括该模块的导出。
除了全局调用函数的情况外,还有两种情况,关键字this将不是调用的明显对象:
- 如果被调用的函数被定义为一个箭头函数,那么它将从它所在的范围中吸收
this值 - 如果被调用的函数是一个构造函数,它的
this值将是一个新对象,该对象预设了函数的[[Prototype]]属性
当调用或声明一个函数时,也有强制使用this值的方法。 您可以使用bind(X)创建一个新函数,将其this值设置为X:
const sayHelloToTokyo = sayMyName.bind(tokyo);
sayHelloToTokyo(); // => Logs "My name is Tokyo"您还可以使用一个函数的call和apply方法迫使this的值对于任何给定的调用,但请注意,这将不是工作如果函数被称为构造函数(与一个新的关键字),或者如果它被定义 arrow-function 语法:
// Forcing the value of `this` via `.call()`:
tokyo.sayMyName.call(london); // => Logs "My name is London"在日常的函数调用中,最好避免使用这种尴尬的调用技术。 这样的技术会使代码的读者很难辨别发生了什么。 有许多通过call、apply或bind调用的有效应用,但这些应用通常仅限于较低级别的库或实用程序代码。 高级逻辑应该避免它们。 如果您发现自己必须在更高级别的抽象中依赖这些方法,那么您可能会使一些事情变得比实际需要的更复杂。
超级关键字有三种不同的风格:
-
super()作为直接函数调用将调用超类的构造函数(即其对象的[[Prototype]]构造函数),并且只能在构造函数内部调用。 在尝试访问this之前也必须调用它,因为启动执行上下文的是super()本身。 -
super.property将访问超类上的属性(即[[Prototype]]),并且仅在使用方法定义语法定义的构造函数或方法中有效引用。 -
super.method()将调用超类上的方法(即[[Prototype]]),并且仅在使用方法定义语法定义的构造函数或方法中有效调用。
关键字super与类定义和方法定义语法同时被引入到语言中,因此它与这些结构紧密相连。 你可以在类构造函数、方法以及对象字面量中的方法定义中自由使用super:
const Utils {
constructor() {
super(); // <= I can use super here
}
method() {
super.method(); // <= And here...
}
}
const utils = {
method() {
return super.property; // <= And even here...
}
};
关键字super,顾名思义,在语义上适合于引用超类,所以 99%的有效用例都在类定义中,在类定义中,你寻求引用被扩展的类,像这样:
const Banana extends Fruit {
constructor() {
super(); // Call the Fruit constructor
}
}以这种方式使用super是完全直观的,特别是对于习惯了其他 OOP 语言的程序员来说。 然而,对于熟悉 JavaScript 原型机制的人来说,super的实现似乎令人困惑。 与this值不同,super是在定义时间而不是调用时间绑定的。 我们已经看到了如何以特定的方式(例如,使用fn.call())调用方法来操作这个值。 你不能同样地操纵super。 希望这不会对你产生任何影响,但是记住它还是很有用的。
如果函数是通过new操作符调用的,那么new.target绑定将等于当前被调用的函数。 我们通常使用new操作符来实例化类,在这种情况下,我们将正确地期望new.target就是那个类:
class Foo {
constructor() {
console.log(new.target === Foo);
}
}
new Foo(); // => Logs: true当我们希望通过直接调用构造函数而不是通过new调用来执行某种行为时,这是非常有用的。 一种常见的防御策略是让构造函数以相同的方式运行,不管调用它时是否使用了new。 这可以通过检查new.target来实现:
function Foo() {
if (new.target !== Foo) {
return new Foo();
}
}
new Foo() instanceof Foo; // => true
Foo() instanceof Foo; // => true或者,您可能希望抛出一个错误来检查构造函数是否被错误调用:
function Foo() {
if (new.target !== Foo) {
throw new Error('Foo is a constructor: please instantiate via new Foo()');
}
}
Foo() instanceof Foo; // !! Error: Foo is a constructor: please instantiate via new Foo()这两个例子都可以被认为是new.target的直观用例。 当然,可以根据调用模式使用它来交付完全不同的功能,但是为了满足程序员的合理期望,最好避免这种行为。 记住普拉。
绑定可以作为一个类似数组的对象使用,它将包含调用给定函数时使用的参数。
When we say that arguments is array-like, we are referring to the fact that it has a length property and properties indexed from zero (just like a regular Array), but it still just a regular Object and therefore does not have any of array's built-in methods available, such as forEach, reduce, and map.
在这里,我们可以看到参数是在给定函数的范围内提供的:
function sum() {
arguments; // => [1, 2, 3, 4, 5] (Array-like object)
let total = 0;
for (let n of arguments) total += n;
return total;
}
sum(1, 2, 3, 4, 5);arguments绑定通常用于访问任意(即非固定)数量的参数,但在语言引入了rest 参数语法(...arg)后,它的用处很快就消失了。 当定义一个函数来指示 JavaScript 将剩余的参数放入一个单一数组时,可以使用这种较新的语法。 这意味着您可以实现旧的arguments绑定的所有实用功能,而且您将得到一个不仅是类似数组的值,而且实际上是一个真正的数组。 这里有一个例子:
function sum(...numbers) {
// We can call reduce() on our array:
return numbers.reduce((total, n) => total + n, 0);
}
sum(1, 2, 3, 4, 5);尽管arguments对象已经不再受欢迎,但它仍然在语言规范中,并且可以在较旧的环境中工作,所以您仍然可以看到它的应用。 大多数情况下,这种用法是可以避免的。
令人困惑的是,函数有名称,而这些名称与我们分配给函数的变量或属性不同。 函数名在其语法中,在圆括号之前:
function nameOfTheFunction() {}你可以通过函数的name属性来访问函数名:
nameOfTheFunction.name; // => "nameOfTheFunction"当你通过函数声明语法定义一个函数时,它会将该函数赋给同名的局部变量,这意味着我们可以像预期的那样引用该函数:
function nameOfTheFunction() {}
nameOfTheFunction; // => the function
nameOfTheFunction.name; // => "nameOfTheFunction"方法定义也会将方法赋给一个与函数名相等的属性名:
function nameOfTheFunction() {}
nameOfTheFunction; // => the function
nameOfTheFunction.name; // => "nameOfTheFunction"你可能会觉得这一切都很直观。 它是。 我们给函数和方法取的名字本身就用来指示这些东西将被赋值给什么变量或属性,这是非常有意义的。 但奇怪的是,也可能有命名函数表达式,而这些名称不会导致这样的赋值。 下面是一个例子:
const myFunction = function hullaballoo() {}这里的const名称,myFunction,指示了我们将在随后的行中使用什么来引用该函数。 然而,该函数在技术上有一个名称"hullaballoo":
myFunction; // => the function
myFunction.name; // => "hullaballoo"如果试图通过函数的正式名称引用函数,将会得到一个错误:
hullaballoo; // !! ReferenceError: hullaballoo is not defined这似乎有些奇怪。 如果函数名本身不用于引用该函数,为什么可以给该函数一个名称呢? 这是传统和便利的结合。 命名函数表达式的一个隐藏特性是,名称实际上可以用于引用函数,但只能在函数本身的作用域内使用:
const myFunction = function hullaballoo() {
hullaballoo; // => the function
};这可能是有用的情况下,你想提供一个匿名回调其他函数,但仍然能够引用自己的回调任何重复或递归调用,像这样:
[
['chris', 'smith'],
['sarah', ['talob', 'peters']],
['pam', 'taylor']
].map(function capitalizeNames(item) {
return Array.isArray(item) ?
item.map(capitalizeNames) :
item.slice(0, 1).toUpperCase() + item.slice(1);
});
// => [["Chris","Smith"],["Sarah",["Talob", "Peters"]],["Pam","Taylor"]]因此,即使命名函数表达式是一个奇怪的东西,它也有它的优点。 然而,在使用过程中,最好考虑代码的清晰度,以免人们不知道这些特殊行为。 这并不意味着完全避免它,只是在使用它时更加注意代码的可读性。
函数声明是一种悬挂声明。 一个被提升的声明,在运行时,将被有效地提升到其执行上下文的顶部,这意味着它将立即被前面的代码行访问(似乎是在声明之前的声明):
hoistedDeclaration(); // => Does not throw an error...
function hoistedDeclaration() {}当然,对于被赋值给变量的函数表达式来说,这是不可能的:
regularFunctionExpression();
// => Uncaught ReferenceError:
// => Cannot access 'regularFunctionExpression' before initialization
const regularFunctionExpression = function() {};函数声明的提升行为可能会产生意想不到的结果,因此通常认为依赖提升是一种反模式。 一般来说,使用函数声明是可以的,只要它们的使用方式符合程序员直观的假设。 吊装作为一种实践,对大多数人来说不是很直观,所以通常最好避免它。
For more information on scopes and how hoisting occurs in the case of function declarations, please take a look at Chapter 9, Parts of Syntax and Scope, and go to the Scopes and Declarations section.
函数表达式是最容易使用和最可预测的,因为它们在语法上与 JavaScript 中的所有其他值相似。 你可以用它们来字面上定义函数,在任何地方,你可以定义任何其他值,因为它们是一种表达式类型。 注意这里,例如,我们是如何定义一个函数数组的:
const arrayOfFunctions = [
function(){},
function(){}
];函数表达式的一个常见应用是将回调函数传递给其他函数,以便稍后调用它们。 许多原生的Array方法,如forEach,以这种方式接受函数:
[1, 2, 3].forEach(function(value) {
// do something with each value
});这里,我们将一个函数表达式传递给forEach方法。 我们没有通过给变量赋值来命名这个函数,因此它被认为是一个匿名函数。 匿名函数是有用的,因为它们意味着我们不需要预先将函数赋值给变量来使用它; 我们可以简单地将函数写到代码中使用的确切位置。
函数表达式在表达方式上最类似于箭头函数。 我们将会发现,关键的区别在于箭头函数不能访问它自己的绑定(例如,到this或arguments)。 然而,函数表达式可以访问这些值,因此在某些上下文中对您更有用。 为了成功地操作 DOM API,通常需要绑定到this,例如,许多本地 DOM 方法将调用回调和事件处理程序,并将相关元素作为执行上下文。 此外,当在需要访问当前实例的对象或原型上定义方法时,您将希望使用函数表达式。 如这里所示,使用箭头函数是不合适的:
class FooBear {
name = 'Foo Bear';
}
FooBear.prototype.sayHello = () => `Hello I am ${this.name}`;
new FooBear().sayHello(); // => "Hello I am ";
FooBear.prototype.sayHello = function() {
return `Hello I am ${this.name}`;
};
new FooBear().sayHello(); // => "Hello I am Foo Bear";如您所见,使用箭头函数语法阻止我们通过this访问实例,而函数表达式语法允许我们这样做。 因此,函数表达式虽然在某种程度上被更简洁的箭头函数所取代,但仍然是一个非常有用的工具。
在许多方面,箭头函数只是函数表达式的一个稍微简洁的版本,尽管它确实有一些实际的区别。 它有两种类型:
// Regular Arrow Function
const arrow = (arg1, arg2) => { return 123; };
// Concise Arrow Function
const arrow = (arg1, arg2) => 123;正如你所看到的,简洁变体包括隐式返回,而变体,就像其他函数定义样式,需要定义一个普通函数体由花括号分隔开的,您必须显式地用return语句返回一个值。**
*此外,当声明只有一个参数的函数时,箭头函数允许您避免使用括号。 在这些情况下,你可以把参数的标识符单独放在箭头之前,像这样:
const addOne = n => n + 1;在需要大量传递函数的情况下,箭头函数的简洁性非常有用。 例如,当通过map之类的本地方法操作数组时,这是很常见的:
[1, 2, 3]
.map(n => n*2)
.map(n => `Number ${n}`);
// => ["Number 2", "Number 4", "Number 6"]尽管 arrow 函数的超级英雄地位是冗长函数定义的简洁变体,但它也有自己的挑战。 事实上,该语言必须适应语法的简洁和常规变体,这意味着当试图从简洁的箭头函数返回一个对象字面量时,会有一些歧义:
const giveMeAnObjectPlease = () => { name: 'Gandalf', age: 2019 };
// !! Uncaught SyntaxError: Unexpected token `:`这个语法会让 JavaScript 解析器感到困惑,因为左花括号意味着一个常规函数体驻留在其中。 因此,解析器会给我们一个关于意外标记的错误,因为它不期望对象文字的主体。 如果我们想从箭头函数的简洁形式返回一个对象字面量,那么我们必须笨拙地将它包装在括号中,以消除语法上的歧义:
const giveMeAnObjectPlease = () => ({ name: 'Gandalf', age: 2019 });在功能上,箭头函数与函数表达式有两种不同:
- 它不提供对
this或arguments等绑定的访问。 - 它没有
prototype属性,所以不能用作构造函数
这些差异意味着,总的来说,箭头函数通常不适合用作方法或构造函数。 它们最适合用于您希望传递回调或处理程序给另一个函数的上下文中,特别是在您希望保留您的this绑定的情况下。 例如,如果我们要在UIComponent抽象的上下文中绑定事件处理程序,我们可能希望保留this值,以便执行特定实例的功能:
class MyUIComponent extends UIComponent {
constructor() {
this.bindEvents({
onClick: () => {
this; // <= usefully refers to the MyUIComponent instance
}
});
}
}在这样的场景中,箭头函数感觉最自在。 然而,它的简洁性意味着,当阅读过于密集的代码行时,可能会有混淆的风险,例如以下代码:
process(
n=>n.filter((nCallback, compute)=>compute(()=>nCallback())
)出于这个原因,最好使用箭头功能相同的考虑和实用性,采用其他构造:确保你总是先把代码的可用性和可读性,上面非常诱人的好用的降温或简洁的语法。
*# 立即调用的函数表达式
从技术上讲,函数表达式和箭头函数是唯一的函数定义样式,它们是表达式。 正如我们所看到的,当我们需要将它们作为值传递给其他函数时,这种特性使它们非常有用,而不需要经过赋值过程。
正如我们前面提到的,一个没有赋值的函数,也就是没有对其值的引用的函数,通常被称为匿名函数,它看起来像这样:
(function() {
// I am an anonymous function
})匿名函数的概念被立即调用函数表达式(IIFE)的概念进一步扩展。 ife 只是一个普通的匿名函数,它被立即调用,像这样:
(function() {
// I am immediately invoked
}());注意右花括号后面的调用括号(即:...())。 这将调用该函数,从而使前面的语法构造成为一个 IIEE。
生命在语言本身中并不是一个独特的概念。 它只是社区提出的一个有用的术语,用来描述立即调用函数的常见模式。 它是一种有用的模式,因为它允许我们创建一个特别的作用域,这意味着在该作用域内定义的任何变量都被限制在该作用域内,不会泄漏到外部,就像我们期望从任何函数中得到的一样。 这个即时作用域有助于在不影响父作用域的情况下快速完成自包含的工作。
IIFEs were popularized in the browser era when it was preferable to avoid polluting the global namespace. Nowadays, with pre-compilation being so popular, the IIFE is less useful.
IIFE 的确切语法可以是不同的。 例如,如果使用箭头函数,则调用括号必须放在包装的函数表达式之后:
(() => {
// I am immediately invoked
})(); // <- () actually calls the function不管我们是使用函数表达式还是箭头函数,其机制基本上是相同的。
如果 IIFE 的概念令人困惑,那么如果我们用一个标识符fn代替实际的函数,并假设我们先前为这个标识符分配了一个函数,就会更容易理解发生了什么。 这里,我们可以这样调用fn:
fn();现在,我们可以选择将fn引用括在括号中。 这对调用没有影响,尽管看起来很奇怪:
(fn)();记住括号只是语法容器,有时需要避免语法歧义。 所以,这些在技术上都是等价的:
fn();
(fn)();
((fn))();如果我们用内联匿名函数替换这里的fn引用,不会有什么突破性的变化。 我们不是引用一个现有的函数,而是直接表达一个内联函数,然后调用它:
(function() {
// Called immediately...
})();We call the pattern of an inline function expression an IIFE, but it really isn't anything special. Consider that the invocation parentheses, that is, ...(), don't really care what they're attached to, as long as it's a function. The expression prior to the invocation could be literally anything as long as it evaluates to a function.
IIFEs 很有用,因为它们提供了作用域隔离,而不必像我们在这里所做的那样,定义一个带有名称的函数,然后再引用和调用它:
const initializeApp = () => {
// Initializing...
};
initializeApp();在浏览器中,在涉及编译和绑定的复杂构建之前,iife 非常有用,因为它们提供了范围隔离,同时不会将任何名称泄漏到全局范围。 然而,如今,生活已不再必要。
有趣的是,前面代码中的initializeApp函数具有明确的名称,可以证明它更易于阅读和理解。 这就是为什么即使有必要,生活有时也会被认为是不必要的困惑和幻想。 命名函数可以有效地提供关于其目的和作者意图的线索。 如果没有名称,我们代码的读者将不得不通读函数本身以发现它的广泛用途,这是一种认知负担。 由于这个原因,通常最好避免 iife 和类似的匿名构造,除非您有非常具体的需求。
方法定义与类定义同时添加到语言中,以允许您轻松声明绑定到特定对象的方法。 但是,它们并不局限于类定义。 你也可以在对象字面量中自由使用它们:
const things = {
myFunction() {
// ...
}
};在类中,你也可以这样声明方法:
class Things {
myFunction() {
// ...
}
}你也可以使用传统风格的函数定义来声明你的方法,例如分配给一个标识符的函数表达式:
class Things {
myFunction = function() {
// ...
};
}然而,方法定义和其他类型的函数定义之间有一个关键的区别。 方法定义将始终绑定到第一次定义它的对象。 这在内部被称为[[HomeObject]]。 这个 home 对象将决定当方法被调用时,哪些super绑定是可用的。 只有方法定义被允许引用super,并且它们引用的super始终是其[[HomeObject]]的[[Prototype]]。 这意味着如果你试图从其他对象借用方法,你可能会惊讶地发现super不是你想要的:
class Dog {
greet() { return 'Bark!'; }
}
class Cat {
greet() { return 'Meow!'; }
}
class JessieTheDog extends Dog {
greet() { return `${super.greet()} I am Jessie!`; }
}
class JessieTheCat extends Cat {
greet() { return `${super.greet()} I am Jessie!`; }
}在这里,我们可以观察到JessieTheCat和JessieTheDog都有greet方法:
new JessieTheDog().greet(); // => "Bark! I am Jessie!"
new JessieTheCat().greet(); // => "Meow! I am Jessie!"我们还可以观察到它们的 greet 方法是以相同的方式实现的。 它们都返回插入的字符串${super.greet()} I am Jessie!。 因此,让JessieTheCat借用JessieTheDog方法似乎是合乎逻辑的。 毕竟,它们是完全一样的:
class JessieTheCat extends Cat {
greet = JessieTheDog.prototype.greet
}我们可能会直观地期望 greet 方法中的super引用当前实例的超类,在JessieTheCat的情况下,它将是Cat。 但奇怪的是,当我们调用这个借来的方法时,我们会经历一些不同的事情:
new JessieTheCat().greet(); // => "Bark! I am Jessie!"它叫! 令人烦恼的是,借来的方法保留了它与原来的[[HomeObject]]的绑定。
总之,方法定义比它们冗长的表亲——函数声明和函数表达式——更简单、更简洁。 然而,它们带有一种隐式机制,将它们区分开来,并可能造成混淆。 99%的情况下,方法定义不会伤害你; 他们会像预期的那样行事。 在剩下的 1%的时间里,了解代码为什么会出现错误是很有用的,这样您就可以探索其他选项。 一如既往,了解 JavaScript 的特性只会帮助我们追求更干净、更可靠的代码库。
Asynchronous(async)函数在 function 关键字之前指定一个async关键字。 所有函数定义样式都可以用它作为前缀:
// Async Function Declaration:
async function foo() {}
// Async Function Expression:
const foo = async function() {};
// Async Arrow-Function:
const foo = async () => {};
// Async Method Definition:
const obj = {
async foo() {}
};通过提供两个关键特性,异步函数允许你轻松地执行异步操作:
- 你可以在 async 函数中使用
await来等待 promise 的完成 - 你的函数总是返回一个 Promise,它本身可以被等待
Promise 是用于处理异步操作的原生抽象。 它可能看起来很复杂,但最好将 Promise 看作是一个将在之后的(即异步)之后解决或拒绝的对象。
传统上,在 JavaScript 中,我们必须传递回调来确保我们能够响应这样的异步活动:
getUserDetails('user1', function(userDetails) {
// This callback is called asynchronously
});然而,使用 async 函数和await,我们可以更简洁地实现:
const userDetails = await getUserDetails('user1');这里的await子句将暂停当前执行,直到getUserDetails完成并解析为一个值。 注意,我们只能在本身是异步的函数中使用 await。
Asynchronous execution is a complex topic, so there is a whole chapter dedicated to it, that is, Chapter 10, Control Flow. For now, it's useful to know that async functions are a distinct type of a function that will always return a Promise.
除了允许await子句和返回 promise 之外,异步函数具有与所使用的各自函数定义风格相同的特性和特征。 与普通箭头函数一样,异步箭头函数没有自己的 this 或参数绑定。 异步函数声明会像它的非异步表亲一样被挂起。 从本质上讲,async 应该被认为是在您已经掌握的关于不同函数定义风格的所有知识之上的一层。
我们将要介绍的最后一种函数定义风格是非常强大的生成器函数。 一般来说,生成器用于提供和控制一个或多个,甚至无限项序列的迭代行为。
在 JavaScript 中生成函数,函数关键字后面有星号:
function* myGenerator() {...}当调用它们时,它们将返回一个生成器对象,该对象唯一地符合可迭代协议和迭代器协议、,这意味着它们可以在自身上迭代,也可以作为对象的迭代逻辑。
Feel free to skip ahead to the section on the iterable protocol. The generator function makes far more sense when you think of it as a convenient way to create an iterator or iterable.
生成器函数将在yield语句处停止并返回一个值,这种情况可能会发生多次。 yield之后,在等待消费者需要它的下一个值时,该功能有效地停止了。 举个例子可以很好地说明这一点:
function* threeLittlePiggies() {
yield 'This little piggy went to market.';
yield 'This little piggy stayed home.';
yield 'This little piggy had roast beef.';
}
const piggies = threeLittlePiggies();
piggies.next().value; // => 'This little piggy went to market.'
piggies.next().value; // => 'This little piggy stayed home.'
piggies.next().value; // => 'This little piggy had roast beef.'
piggies.next(); // => {value: undefined, done: true}正如你所看到的,发电机对象从函数返回一个next方法,调用时,将返回一个对象value(显示的当前值迭代),done属性(指示迭代/代是否完成)。 这是迭代器协议,也是您可以期望所有生成器实现的契约。
生成器不仅满足迭代器协议,还满足可迭代对象协议,这意味着它可以由接受可迭代对象的语言构造进行迭代(如for...of或...spread操作符):
for (let piggy of threeLittlePiggies()) console.log(piggy);
// => Logs: "This little piggy went to market."
// => Logs: This little piggy stayed home."
// => Logs: This little piggy had roast beef."
[...threeLittlePiggies()];
// => ["This little piggy went to market", "This little piggy stayed...", "..."]异步生成器函数也可以指定。 它们有效地将异步和生成器格式组合成一个混合格式,允许自定义异步生成逻辑,如下所示:
async function* pages(n) {
for (let i = 1; i <= n; i++) {
yield fetch(`/page/${i}`);
}
};
// Fetch five pages (/page/1, /page/2, /page/3)
for await (let page of pages(3)) {
page; // => Each of the 3 pages
};您会注意到我们是如何使用for await迭代构造来遍历我们的异步生成器的。 这将确保每次迭代在继续之前都将等待其结果。
生成器函数非常强大,但我们必须清楚其中的潜在机制。 它们不是常规函数,不能保证运行到完成。 它们的实现应该考虑它们将要运行的上下文。 如果您的生成器打算用作迭代器,那么它应该尊重迭代的隐含期望:它是底层数据或生成逻辑的只读操作。 虽然有可能在生成器中改变底层数据,但应该避免这种情况。
JavaScript 中的数组是一种专门的对象类型,因为它包含一组有序的元素。
你可以使用它的字面语法来表达数组,字面语法是用方括号分隔的逗号分隔的表达式列表:
const friends = ['Rachel', 'Monica', 'Ross', 'Joe', 'Phoebe', 'Chandler'];这些逗号分隔的表达式可以是我们想要的复杂或简单的:
[
[1, 2, 3],
function() {},
Symbol(),
{
title: 'wow',
foo: function() {}
}
]数组能够包含所有类型的值。 对于如何使用数组,很少有限制。 从技术上讲,一个数组的length限制在 40 亿左右,因为它的length存储为 32 位整数。 当然,在大多数情况下,这样做是绝对没问题的。
数组中的每个索引元素都有一个数值属性,并有一个length属性描述有多少个元素。 它们也有一组有用的方法来读取和操作其中的数据:
friends[0]; // => "Rachel"
friends[5]; // => "Chandler"
friends.length; // => 6
friends.map(name => name.toUpperCase());
// => ["RACHEL", "MONICA", "ROSS", "JOE", "PHOEBE", "CHANDLER"]
friends.join(' and ');
// => "Rachel and Monica and Ross and Joe and Phoebe and Chandler"过去,数组是使用传统的for(...)和while(...)循环进行迭代的,该循环向length方向增加一个计数器,因此在每次迭代时,可以通过array[counter]访问当前元素,如下所示:
for (let i = 0; i < friends.length; i++) {
// Do something with `friends[i]`
}然而,现在更可取的是使用其他迭代方法,如forEach或for...of:
for (let friend of friends) {
// Do something with `friend`
}
friends.forEach((friend, index) => {
// Do something with `friend`
});for...of的优点是易碎,这意味着您可以在其中使用break和continue语句,并轻松地从迭代中退出。 它也适用于任何可迭代的对象,而forEach只是一个Array方法。 然而,forEach样式是有用的,因为它通过回调的第二个参数为您提供迭代的当前索引。
Which style of iteration you use should be determined by the value you are iterating over and what you wish to do on each iteration. Nowadays, it is quite rare to need to use traditional styles of array iteration such as for(...) and while(...).
大多数本机 Array 方法是泛型的,这意味着它们可以用于任何看起来像数组的对象。 所有我们需要实现一个数组的外观是使用一个length属性和每个索引的单独属性(从 0 索引):
const arrayLikeThing = {
length: 3,
0: 'Suspiciously',
1: 'similar to',
2: 'an array...'
};
// We can "borrow" an array's join method by assigning
// it to our object:
arrayLikeThing.join = [].join;
arrayLikeThing.join(' ');
// => "Suspiciously similar to an array..."在这里,我们构造了一个类似数组的对象,然后通过借用数组的join方法(也就是从Array.prototype中借用)为它提供了自己的join方法。 本地数组join方法一般实现,它不介意操作一个对象只要对象数组的履行合同提供length属性和相应的索引(0、1、2,等等)。 大多数本机数组方法都是类似的泛型方法。
语言本身中类数组对象的一个例子是我们在本章前面讨论过的arguments绑定。 另一个例子是NodeList,它是从各种 DOM 选择方法返回的一种对象类型。 如果有必要,我们可以通过借用并调用 arrayslice方法,从这些对象中派生出合适的数组,如下所示:
const arrayLikeObject = { length: 2, 0: 'foo', 1: 'bar' };
// "Borrowing" a method from an array and forcing its
// execution context via call():
[].slice.call(arrayLikeObject);
// "Borrowing" a method explicitly from the Array.prototype
// and forcing its execution context via call():
Array.prototype.slice.call(arrayLikeObject);然而,对于arguments或NodeList对象,我们也可以依赖于它们是可迭代的,这意味着我们可以使用 spread 语法来派生一个 true 数组:
// "spread" a NodeList into an Array:
[...document.querySelectorAll('div span a')];
// "spread" an arguments object into an Array:
[...arguments];如果您发现自己需要创建一个类似数组的对象,可以考虑让它实现可迭代协议(我们将对此进行探讨),这样就可以以这种方式使用扩展语法。
Set和WeakSet是允许我们存储唯一对象序列的原生抽象。 这与数组相反,数组不能保证值的唯一性。 这里有一个例子:
const foundNumbersArray = [1, 2, 3, 4, 3, 2, 1];
const foundNumbersSet = new Set([1, 2, 3, 4, 3, 2, 1]);
foundNumbersArray; // => [1, 2, 3, 4, 3, 2, 1]
foundNumbersSet; // => Set{ 1, 2, 3, 4 }正如您所看到的,如果给Set的值已经存在于Set中,那么它们将始终被忽略。
可以通过向构造函数传递一个可迭代的值来初始化集合; 例如,字符串:
new Set('wooooow'); // => Set{ 'w', 'o' }如果你需要将一个Set转换成一个数组,你可以简单地使用 spread 语法(集合本身是可迭代的):
[...foundNumbersSet]; // => [1, 2, 3, 4]weakset 与前面提到的 WeakMaps 类似。 它们是用于弱的,以允许该值在程序的另一部分中被垃圾回收的方式保存值。 使用集合的语义和最佳实践与使用数组的语义和最佳实践类似。 如果需要存储唯一的值序列,建议只使用 set; 否则,就使用一个简单的数组。
iterable 协议允许包含序列的值共享一组共同的特征,允许它们都被迭代或以类似的方式处理。
We can say that an object that implements the iterable protocol is iterable. Iterable objects within JavaScript include Array, Map, Set, and String.
任何对象都可以定义自己的可迭代协议,只要在属性名的Symbol.iterator(映射到内部的@@iterator属性)下提供一个迭代器函数即可。
该迭代器函数必须通过返回带有next函数的对象来实现迭代器协议。 当调用这个next函数时,必须返回一个具有done和value键的对象,该键指示迭代的当前值以及迭代是否完成:
const validIteratorFunction = () => {
return {
next: () => {
return {
value: null, // Current value of the iteration
done: true // Whether the iteration is completed
};
}
}
};所以,完全清楚地说,有两种不同的协议:
-
可迭代协议:任何通过
[Symbol.iterator]实现@@iterator的对象都将实现该协议。 本地示例包括Array、String、Set和Map。 -
迭代器协议:返回
{... next: Function}形式的对象,且其next方法在调用时返回以下形式的对象的任何函数:
对于一个要实现 iterable 协议的对象,它必须实现[Symbol.iterator],像这样:
const zeroToTen = {};
zeroToTen[Symbol.iterator] = function() {
let current = 0;
return {
next: function() {
if (current > 10) return { done: true };
return {
done: false,
value: current++
};
}
}
};
// We can see the effect of the iterable via the spread operator:
[...zeroToTen]; // => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]当您希望控制迭代的顺序,或者希望以某种方式在迭代期间处理、过滤或生成值时,通过 iterable 协议提供自定义迭代方法可能会很有用。 例如,在这里,我们将迭代器函数指定为 generator 函数,您可能还记得,该函数返回一个既满足迭代器又满足 iterable 协议的生成器。 这个生成器函数将为存储的每个单词生成两种变体——一个大写字母和一个小写字母:
const words = {
values: ['CoFfee', 'ApPLE', 'Tea'],
[Symbol.iterator]: function*() {
for (let word of this.values) {
yield word.toUpperCase();
yield word.toLowerCase();
}
}
};
[...words]
// => ["COFFEE", "coffee", "APPLE", "apple", "TEA", "tea"]像这样将迭代器函数指定为生成器函数要比手动实现迭代器协议简单得多。 生成器自然地履行了这一契约,因此可以更无缝地使用它们。 生成器也更易于阅读和简洁,并具有实现迭代器和可迭代协议的双重好处,这意味着它们可以用于装饰具有迭代功能的对象:
const someObject = {
[Symbol.iterator]: function*() { yield 123; }
};
[...someObject]; // => [123]他们自己也可以提供这种迭代能力:
function* someGenerator() {
yield 123;
}
[...someGenerator()]; // => [123]重要的是要记住,在自定义可迭代对象中完成的任何工作都应该符合使用者的期望。 迭代通常被认为是只读操作,因此您应该避免在迭代期间底层值集的变化。 实现您自己的可迭代对象可能非常强大,但也可能导致代码消费者的意外行为,他们不知道您的自定义迭代逻辑。
对于那些熟悉的人和那些可能只是第一次体验你的界面或抽象的人来说,平衡自定义迭代的便利性至关重要。
JavaScript 通过对象类型RegExp原生支持正则表达式,允许它们通过字面语法/foo/或直接通过构造函数(RegExp('foo'))来表达。 正则表达式用于定义可以对字符串进行匹配或执行的字符模式。
下面是一个例子,我们从文本语料库中只提取长单词(>=10字符):
const string = 'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Etiam sit amet odio ultrices nunc efficitur venenatis laoreet nec leo.';
string.match(/\w{10,}/g); // => ["consectetur", "adipiscing"]The grammar and syntax of regular expressions can be complex. It is technically an entire language unto itself, requiring many days of study. We won't be able to explore all of its complexity here. We will, however, be covering the ways in which we typically operate on regular expressions within JavaScript and explore some of the challenges in doing so. It is suggested that you conduct further study into regular expressions yourself.
正则表达式允许我们描述一种字符模式。 它们用于从字符串中匹配和提取值。 例如,如果我们有一个在不同位置包含数字(1,2,3)的字符串,正则表达式将允许我们轻松地检索它们:
const string = 'some 1 content 2 with 3 digits';
string.match(/1|2|3/g); // => ["1", "2", "3"]正则表达式被写成由正斜杠分隔的模式,在最后一个正斜杠后面有可选的标志:
/[PATTERN]/[FLAGS]您编写的模式可以包含文字和特殊字符,它们一起告诉正则表达式引擎要查找什么。 我们在示例中使用的正则表达式包含文字字符(即1、2、3)和管道特殊字符(即|):
/1|2|3/g管道特殊字符告诉正则表达式引擎,管道左边或右边的字符可以匹配。 最后一个正斜杠后面的g是一个全局标志,指示引擎在字符串内全局搜索,在找到第一个匹配项后不要放弃。 对我们来说,这意味着正则表达式将匹配"1"、"2"或"3",无论它们出现在主题字符串中的哪个位置。
我们可以在正则表达式中使用一些特殊字符作为快捷方式。 符号[0-9]就是一个例子。 它是一个字符类,将匹配从0到9的所有数字,因此我们不必逐个列出所有这些数字。 还有一个速写字符类,\d,让我们可以更简洁地表达这一点。 因此,可以将正则表达式缩短为:
/\d/g对于更实际的应用,我们可以设想一个场景,在该场景中,我们希望匹配数字序列,比如电话号码。 也许我们只希望匹配那些以0800开头,并进一步包含4到6数字的电话号码。 我们可以用下面的正则表达式来做到这一点:
/0800\d{4,6}/g在这里,我们使用了{n, n}语法,它允许我们为前面的特殊字符\d表示一个数量。 我们可以通过将它传递给一个测试字符串的match方法来确认我们的模式是否有效:
`
This is a test in which exist some phone
numbers like 0800182372 and 08009991.
`.match(
/0800\d{4,6}/g
);
// => ["0800182372", "08009991"]这篇简短的介绍仅仅触及了正则表达式的表层功能。 正则表达式的语法允许我们表达非常复杂的内容,允许我们验证字符串中是否存在特定的文本,或者提取特定的文本以便在程序中使用。
正则表达式的字面语法允许特定的标志,例如i(忽略大小写),在最后一个正斜杠后指定。 这些标志将影响正则表达式的执行方式:
/hello/.test('hELlO'); // => false
/hello/i.test('hELlO'); // => true当使用RegExp构造函数时,你可以传递你的标志作为第二个参数:
RegExp('hello').test('hELlO'); // => false
RegExp('hello', 'i').test('hELlO'); // => true在 JavaScript 的正则表达式中有六个可用的标志:
-
i:ignore-case标志在匹配字母时忽略字符串的大小写(即:/a/i同时匹配字符串中的'a'和'A')。 -
g:global-match标志将使正则表达式查找所有匹配,而不是在第一次匹配后停止。 -
m:多行标志将使起始和结束锚(即^和$)标记单个行的起始和结束,而不是整个字符串。 -
s:dotAll标志将导致你的正则表达式中的点字符(通常只匹配非换行字符)匹配换行字符。 -
u:Unicode标志将把正则表达式中的字符序列作为单个 Unicode 码点而不是代码单元。 这意味着你可以轻松匹配和测试稀有或奇异的符号,如表情符号(请参阅本章的String类型章节,以更全面地理解 Unicode)。 -
y:sticky标志将导致所有RegExp操作尝试在lastIndex属性详细描述的精确索引上进行匹配,然后在匹配上发生lastIndex突变。
正如我们所看到的,正则表达式也可以通过RegExp构造函数来构造。 它可以作为构造函数或常规函数调用:无论哪种方式,你都会收到一个与字面语法派生的RegExp对象等价的对象:
new RegExp('[a-z]', 'i'); // => /[a-z]/i
RegExp('[a-z]', 'i'); // => /[a-z]/i这是一种非常独特的行为。 事实上,RegExp构造函数是唯一可以同时作为构造函数和常规函数调用的原生构造函数,并且在这两种情况下都返回一个新实例。 您还记得,原语构造函数(如String和Number)可以作为常规函数调用,但作为构造函数调用时,其行为会有所不同。
JavaScript 提供了 7 种能够利用正则表达式的方法:
-
RegExp.prototype.test(String):对传递的字符串运行正则表达式,如果找到至少一个匹配项则返回 true。 如果没有找到匹配,它将返回 false。 -
RegExp.prototype.exec(String):如果正则表达式有一个全局(g),则标志exec()将返回当前lastIndex的下一个匹配项(并在此之后更新正则表达式的lastIndex); 否则,它将返回正则表达式的第一个匹配项(类似于String.prototype.match)。 -
String.prototype.match(RegExp):该String方法将返回对字符串所传递的正则表达式的匹配(如果设置了全局标志,则返回所有匹配)。 -
String.prototype.replace(RegExp, Function):这个String方法将对每个单独的匹配执行传递的函数,并将对于每个匹配,用函数返回的任何内容替换匹配的文本。 -
String.prototype.matchAll(RegExp):这个String方法将返回所有结果及其所属组的迭代器。 当全局正则表达式包含各个匹配组时,这非常有用。 -
String.prototype.search(RegExp):这个String方法将返回第一个匹配项的索引,如果没有找到匹配项,则返回-1。 -
String.prototype.split(RegExp):该String方法将返回一个数组,其中包含由所提供的分隔符(可以是正则表达式)分割的字符串的部分。
有许多方法可供选择,但在大多数情况下,您可能会发现RegExp方法、test()和 String 方法match()和replace()是最有用的。
下面是这些方法的一些示例的纲要。 这应该让你对每种方法可能使用的情况有一个概念:
// RegExp.prototype.test
/@/.test('a@b.com'); // => true
/@/.test('aaa.com'); // => false
// RegExp.prototype.exec
const regexp = /\d+/g;
const string = '123 456 789';
regex.exec(string); // => ["123"]
regex.exec(string); // => ["456"]
regex.exec(string); // => ["789"]
regex.exec(string); // => null
// String.prototype.match
'Orders: #92838 #02812 #92833'.match(/\d+/); // => ["92838"]
'Orders: #92838 #02812 #92833'.match(/wo+w/g); // => ["92838", "02812", "92833"]
// String.prototype.matchAll
const string = 'Orders: #92333 <fulfilled> #92835 <pending>';
const matches = [
...string.matchAll(/#(\d+) <(\w+)>/g)
];
matches[0][1]; // => 92333
matches[0][2]; // => fulfilled
// String.prototype.replace
'1 2 3 4'.replace(/\d/, n => `<${n}>`); // => "<1> 2 3 4'
'1 2 3 4'.replace(/\d/g, n => `<${n}>`); // => "<1> <2> <3> <4>'
// String.prototype.search
'abcdefghhijklmnop'.search(/k/); // => 11
// String.prototype.split
'time_in____a__tree'.split(/_+/); // ["time", "in", "a", "tree"]
正如您所看到的,大多数方法的行为都很直观。 然而,围绕着粘性和lastIndex属性有一些复杂性,我们将在这里详细介绍。
默认情况下,如果你的RegExp是全局的(即使用g标志),RegExp方法(即test()和exec())将在每次执行时改变RegExp对象的lastIndex属性。 这些方法将尝试匹配当前lastIndex属性(默认值为 0)指定的索引中的主题字符串,然后在每次后续调用时更新lastIndex。
如果你期望exec()或test()对给定的全局正则表达式和字符串总是返回相同的结果,这可能会导致意想不到的行为:
const alphaRegex = /[a-z]+/g;
alphaRegex.exec('aaa bbb ccc'); // => ["aaa"]
alphaRegex.exec('aaa bbb ccc'); // => ["bbb"]
alphaRegex.exec('aaa bbb ccc'); // => ["ccc"]
alphaRegex.exec('aaa bbb ccc'); // => null如果您试图在多个字符串上执行全局正则表达式而不自己重置lastIndex,也会导致混淆:
const alphaRegex = /[a-z]+/g;
alphaRegex.exec('monkeys laughing'); // => ["monkeys"]
alphaRegex.lastIndex; // => 7
alphaRegex.exec('birds flying'); // => ["lying"]如您所见,与"monkeys"子字符串匹配后,更新lastIndex下一个指数(7),这意味着,当上执行不同的字符串,正则表达式将继续上次和尝试匹配一切超出指数,在第二个字符串中,"birds flying",substring"lying"。
作为一条规则,为了避免这些混淆,重要的是始终拥有正则表达式的所有权。 如果你正在使用RegExp方法,不要接受来自程序其他地方的正则表达式。 同样,不要尝试在不同的字符串上使用exec()或test(),而在每次执行之前都要重置lastIndex:
const petRegex = /\b(?:dog|cat|hamster)\b/g;
// Testing multiple strings without resetting lastIndex:
petRegex.exec('lion tiger cat'); // => ["cat"]
petRegex.exec('lion tiger dog'); // => null
// Testing multiple strings with resetting lastIndex:
petRegex.exec('lion tiger cat'); // => ["cat"]
petRegex.lastIndex = 0;
petRegex.exec('lion tiger dog'); // => ["dog"]在这里,你可以看到,如果我们不重置lastIndex,我们的正则表达式将无法匹配随后传递给exec()方法的字符串。 然而,如果我们在每次后续的exec()调用之前重置lastIndex,我们将观察到一个匹配。
粘性意味着正则表达式将尝试匹配精确的lastIndex,如果匹配在那个精确的索引处不可用,它将失败(也就是说,返回null或false,这取决于所使用的方法)。 每次匹配,粘性标志(y)将强制RegExp读取lastIndex并改变lastIndex。 传统的粘性方法,如exec()和test(),正如我们前面提到的,总是会这样做,但y旗会强制粘性,即使使用非粘性方法,如match():
const regexp = /cat|hat/y; // match 'cat' or 'hat'
const string = 'cat in a hat';
// lastIndex is always zero by default, so will
// match from the start of the string:
regexp.lastIndex; // => 0
regexp.test(string); // => ["cat"]
// lastIndex has been modified following the last
// match but will not match anything as there is
// no cat or hat at index 3:
regexp.lastIndex; // => 3
string.match(regexp); // => null
// Set lastIndex to 9 (index of "hat"):
regexp.lastIndex = 9;
string.match(regexp); // => ["hat"]如果您在字符串或字符串系列的特定索引处寻找匹配,那么粘性可能会很有用。 然而,如果你不能完全控制lastIndex,它的行为可能会出乎意料。 正如我们前面提到的,一个好的通用规则是始终拥有您自己的RegExp对象的所有权,以便只有您的代码才能对lastIndex进行任何更改。
在本章中,我们已经开始深入研究 JavaScript 语言提供的内置类型。 我们探索的重点是通过干净代码的镜头来观察这些语言结构。 通过这样做,我们强调了在处理语言中一些更模糊的领域时谨慎的重要性。 我们已经发现了使用 JavaScript 类型时涉及到的许多棘手的边缘情况和挑战,例如浮点Number类型缺乏精确度,String类型 Unicode 的复杂性。 探索语言中这些更困难的部分,不仅可以让我们避开特定的陷阱,还可以让我们更加流利地使用 JavaScript 编写干净的代码。
在下一章中,我们将继续提高英语的流利程度。 我们将进一步了解 JavaScript 的类型系统,并开始操作这些类型以满足我们的需求。****