- JavaScript 代码整洁指南
 PDF电子书集合
PDF电子书集合
JavaScript 现实世界的挑战详解
JavaScript 程序员面临的许多挑战可能不是语言本身,而是他们的代码必须存在于其中并与之交互的生态系统。 JavaScript 通常用于 web 的上下文中,在浏览器或服务器上,因此遇到的问题域通常由 HTTP 和 DOM 等主题来描述。 我们经常不得不与框架、api 和机制作斗争,这些框架、api 和机制有时显得笨拙、不直观和复杂。 在本章中,我们将熟悉一些最常见的挑战,以及我们可以用来克服它们的方法和抽象。
我们将首先探讨 DOM 以及在 JavaScript 中构建雄心勃勃的单页应用(spa)所面临的挑战。 然后,我们将探讨依赖性管理和安全性的主题,因为这两者在当今的领域中都是日益重要的竞争力。 这一章的目的并不是对主题进行全面的覆盖,而是快速的深入研究,你可能会发现在今天的 web 平台上制作干净的 JavaScript 的重大任务是相关的。
在本章中,我们将涵盖以下主题:
浏览器提供了文档对象模型(DOM)API,允许开发人员读取并动态改变 web 文档。 在 1997 年首次引入时,它的范围非常有限,但在过去 20 年里有了很大的扩展,现在我们可以通过编程访问各种各样的浏览器功能。
DOM 本身为我们提供了从给定页面的解析 HTML 派生的元素层次结构。 JavaScript 可以通过 API 访问这个层次结构。 这个 API 允许我们选择元素、遍历元素树以及检查元素属性和特征。 下面是一个 DOM 树的例子,使用相应的 JavaScript 来访问它:

多年来,我们访问特定 DOM 节点的方式发生了变化,但其基本的树状结构仍然保持不变。 通过访问这个结构,我们可以从元素中读取、修改它们,或者自己向元素树添加元素。
与 DOM API 是一组提供的其他本地浏览器 API,可以做的事情,如阅读饼干,变异的本地存储,建立后台任务(工人),CSS 对象模型和操作上的(CSSOM)。
*就在最近的 2012 年,web 开发人员通常只使用 JavaScript 来增强已经在页面标记中体现出来的体验。 例如,他们可能只是简单地向按钮添加了滚动状态或向表单字段添加了验证。 这样的添加被认为是一种渐进式增强*,用户可以在没有 JavaScript 的情况下体验网站,如果他们想,但启用 JavaScript 会在某种程度上增强他们的体验。
Progressive enhancement is a principle that espouses the importance of functionality that is resilient to environmental constraints. It tells us that we should try to provide all users with as much functionality as their environment allows. It is often conceptually paired with graceful d**egradation*, which is the ability for a piece of software to maintain limited functionality even when its dependencies are unmet or only partially met (for example, a client-side validated <form> that is submittable even on browsers without JavaScript support is said to gracefully degrade*).
然而,如今,web 应用的前端部分几乎完全使用 JavaScript 构建,并在单个页面中表达,这种情况已经非常普遍。 这些通常被称为 spa。 SPA 将重写当前页面的内容和当前浏览器地址,而不是让用户自然地在网站周围导航,每次操作都在浏览器中加载新页面。 因此,spa 依赖于用户浏览器是否支持 JavaScript 和其他 api。 spa 通常不会优雅地降级,尽管提供一系列回退以便所有用户都能接收功能是最佳实践(也是明智的做法!)。
SPA 的扩散可以归因于开发者体验和用户体验的提升:
- 架构(DX):在前端客户端和后端 API 层之间有一个更好的关注点分离。 这可以产生一个更清晰的体系结构,有助于从 UI 描述业务逻辑。 拥有一个管理呈现和动态增强的代码库也可以极大地简化事情。
- 状态持久性(UX):用户可以在 web 应用中导航和执行操作,而不必丢失页面内的状态,如填充的输入字段或滚动位置。 此外,UX 可以包括多个不同的窗格、模态或独立填充的部分,并且可以持久化,不管采取什么操作。
- 性能(用户体验) 也就是说,在应用的初始加载之后,任何进一步的请求都可以被优化为简单的 JSON REST 响应,没有不必要的样板标记,这样浏览器就可以减少重新解析或重新呈现样板 HTML、CSS 和 JavaScript 的时间。
对 web 应用日益增长的需求和 SPA 的激增意味着程序员开始更多地依赖浏览器 api,特别是 DOM,来创建丰富和动态的体验。 然而,令人痛苦的事实是,DOM 从未打算迎合丰富的桌面式体验的创建。 正因为如此,在使 DOM 适应当前需求的过程中,出现了许多成长的烦恼。 此外,创建框架需要一个缓慢且迭代的过程,以便在一个并非最初为其设计的平台上开发丰富的体验。
当尝试将 DOM 绑定到数据时,DOM(通常是浏览器 api)无法满足 spa 的当前需求的最明显的一种情况是。 现在我们将更深入地探讨这个主题。
多年来,多个框架试图解决的一个特定挑战是 DOM 与数据的绑定。 在上一章关于 MVVM 的章节中,我们简要讨论了数据绑定。 任何 GUI 都需要有一种方法来让显示的像素反映底层数据。
通过 DOM,我们可以动态地创建特定的元素,并按照自己的意愿放置它们。 然后,用户可以通过与这些元素交互(通常是通过输入字段和按钮),将他们的意图强加到应用上。 我们通过 DOM 事件绑定到这些用户操作,然后可能会影响底层数据的更改。 这个更改需要在 DOM 中反映出来。 这种来回通常称为双向结合。 历史上,为了实现这一点,我们需要手动创建一个 DOM 树,在元素上设置事件监听器,然后当任何底层数据(或状态)发生变化时,手动更改这些 DOM 元素。
A reminder: State is the current situation of a program: everything the user sees and everything that underlies what they see. The state of a given application may be represented in more than one place, and these representations may become out-of-sync. We can imagine a scenario in which the same data is displayed in two places but is not consistent.
手工处理 DOM 的挑战在于,如果没有某种抽象,它就不能很好地伸缩。 很容易拿一块数据,从这些数据得出一个 DOM 树,但在 DOM 树与变化数据和数据绑定到用户驱动的 DOM 的变化(例如,单击按钮)相当繁重的事情来实现。
为了说明这个挑战,考虑一个简单的购物列表,它的形式是一个数组,每个条目都是字符串:
const shoppingList = ['Bananas', 'Apples', 'Chocolate'];从这些数据派生 DOM 树非常简单:
const ul = document.createElement('ul');
shoppingList.forEach(item => {
const li = ul.appendChild(document.createElement('li'));
li.textContent = item;
});
document.body.appendChild(ul);这段代码将生成以下 DOM 树(并将其添加到<body>):
<ul>
<li>Bananas</li>
<li>Apples</li>
<li>Chocolate</li>
</ul>但是如果我们的数据改变了呢? 如果有<input>,用户可以通过它添加新物品,会发生什么? 为了适应这些情况,我们必须实现一个抽象来保存数据并在数据发生变化时引发事件(或调用回调)。 此外,我们还需要一些方法将每个单独的数据项绑定到一个 DOM 节点。 如果要将第一项"Bananas"更改为"Melons",那么我们只需对 DOM 进行必要的最小突变,以反映该更改。 在这种情况下,我们想要替换第一个<li>元素的内部文本节点的data属性(换句话说,文本节点中包含的实际文本):
shoppingList[0] = 'Melons';
ul.children[0].firstChild.data = shoppingList[0];抽象地说,这种类型的更改称为DOM 调和,涉及反映对 DOM 中的数据所做的任何更改。 大体上有三种类型的和解:
- Update:如果一个已有的数据项被更新,那么需要更新相应的 DOM 节点来反映这个变化
- delete:如果删除了一个已有的数据项,那么相应的 DOM 节点也应该被删除
- 创建:如果添加了新的数据项,那么应该创建一个新的 DOM 节点,将其附加到活动 DOM 树中的正确位置,然后链接为该数据项的相应 DOM 节点
DOM 协调是一个相对简单的过程。 我们可以很容易地创建具有更新/添加/删除功能的ShoppingListComponent,但它将与数据和 DOM 的结构高度耦合。 正如我们所看到的,与单个更新相关的逻辑可能涉及文本节点内容的特定突变。 如果我们想稍微改变 DOM 树或数据结构,那么我们必须显著重构ShoppingListComponent。
许多现代库和框架都试图通过将 DOM 协调过程抽象到声明式接口后面来减少这个过程的负担。 React 就是一个很好的例子,它允许您在 JavaScript 中使用它的 JSX 语法声明 DOM 树。 JSX 看起来像添加了插值分隔符({...})的常规 HTML,在这里可以编写常规 JavaScript 来表示数据。
在这里,我们正在创建一个组件,它生成一个简单的<h1>问候,用大写的name填充:
function LoudGreeting({ name }) {
return <h1>HELLO { name.toUpperCase() } </h1>;
}LoudGreeting组件可以像这样渲染到<body>:
ReactDOM.render(
<LoudGreeting name="Samantha" />,
document.body
);结果会是:
<body>
<h1>HELLO SAMANTHA</h1>
</body>我们可以用以下方式实现一个ShoppingList组件:
function ShoppingList({items}) {
return (
<ul>
{
items.map((item, index) => {
return <li key={index}>{item}</li>
})
}
</ul>
);
}然后我们可以按照以下方式渲染它,在组件调用中传递特定的购物列表项:
ReactDOM.render(
<ShoppingList items={["Bananas", "Apples", "Chocolate"]} />,
document.body
);这是一个简单的例子,但让我们了解了 React 是如何工作的。 React 的真正神奇之处在于它能够根据数据的变化选择性地重新呈现 DOM。 在我们的示例中,我们可以通过更改数据来响应用户操作来探索这一点。
React 和大多数其他框架为我们提供了一个简单的事件监听机制,这样我们就可以以与传统监听相同的方式监听用户事件。 通过 React 的 JSX,我们可以做以下事情:
<button
onClick={() => {
console.log('I am clicked!')
}}
>Click me!</button>在我们的购物列表问题域的例子中,我们想要创建<input />,它可以从用户那里接收新物品。 为此,我们可以创建一个单独的组件ShoppingListAdder:
function ShoppingListAdder({ onAdd }) {
const inputRef = React.useRef();
return (
<form onSubmit={e => {
e.preventDefault();
onAdd(inputRef.current.value);
inputRef.current.value = '';
}}>
<input ref={inputRef} />
<button>Add</button>
</form>
);
}在这里,我们使用 React Hook(称为useRef)来给我们一个持久引用,我们可以在组件渲染之间重用它来引用我们的<input />。
React Hooks (typically named use[Something]) are a relatively recent addition to React. They've simplified the process of keeping persistent state across component renders. A re-render occurs whenever our ShoppingListAdder function is invoked. But useRef() will return the same reference on every single call within ShoppingListAdder. A singular React Hook can be thought of as the Model in MVC.
对于我们的ShoppingListAdder组件,我们传递了一个onAdd回调,我们可以看到,当用户添加了一个新项目时(换句话说,当<form>提交时),这个回调会被调用。 为了使用一个新组件,我们希望将其放置在ShoppingList中,然后在onAdd被调用时通过向我们的食品列表中添加一个新项目来响应:
function ShoppingList({items: initialItems}) {
const [items, setItems] = React.useState(initialItems);
return (
<div>
<ShoppingListAdder
onAdd={newItem => setItems(items.concat(newItem))}
/>
<ul>
{items.map((item, index) => {
return <li key={index}>{item}</li>
})}
</ul>
</div>
);
}正如你所看到的,我们正在使用另一种类型的 React Hook,称为useState,以持久存储我们的项目。 initialItems可以被传递到我们的组件(作为一个参数),但我们随后从这些派生出一组持久项,我们可以在组件的重新渲染中自由地进行变异。 这就是我们的onAdd回调函数所做的:它向当前的项列表中添加一个新项(由用户输入):

调用setItems将在幕后调用组件的重新渲染,导致<li>Coffee</li>被附加到动态 DOM 中。 创建、更新和删除的处理都是类似的。 React 这类抽象的美妙之处在于,您不需要将这些突变视为 DOM 逻辑的不同部分。 我们所需要做的就是从我们的数据集中派生出一个组件/DOM 树,React 将会找出协调 DOM 所需的精确更改。
为了确保我们理解发生了什么,当一段数据(状态)通过钩子(例如,setItems(...))被改变时,React 会做以下操作:
- React 重新调用组件(重新呈现)
- React 将重新渲染返回的树与之前的树进行比较
- React 使活动 DOM 的基本粒度突变得以反映所有更改
其他现代框架也借鉴了这种方法。 这些抽象中内置的 DOM 协调机制的一个很好的副作用是,通过它们的声明性语法,我们可以从任何给定的数据派生出确定的组件树。 这与命令式方法形成鲜明对比,在命令式方法中,我们必须自己手动选择和修改特定的 DOM 节点。 声明式方法为我们提供了一种纯粹的函数,使我们能够生成确定性和幂等的输出。
As you may recall from Chapter 4, SOLID and Other Principles, functional purity and idempotence give us standalone testable units of predictable input and output. They allow us to say X input will always result in Y output. This transparency aids tremendously in both the reliability and the comprehensibility of our code.
构建大型 web 应用仍然是一个挑战,即使已经解决了调和难题。 给定页面中的每个组件或视图都需要使用其正确的数据填充,并需要传播更改。 我们接下来将探索这个挑战。
当构建一个 web 应用时,你很快就会遇到这样的挑战:在页面中获取不同的部件或组件,以便彼此通信。 在任何时候,应用都应该表示完全相同的数据集。 如果某些内容发生了变化,无论是通过用户操作还是其他机制,这些变化都需要反映在所有适当的地方。
这个问题发生在不同的规模。 您可能有一个聊天应用,其中输入的消息需要尽可能快地传播给所有参与者。 或者,您可能有一段数据需要在同一个应用视图中多次表示,因此所有这些表示都需要保持同步。 例如,如果用户在配置文件设置窗格中更改了他们的名字,那么这应该合理地更新在可见应用中显示他们名字的其他地方:
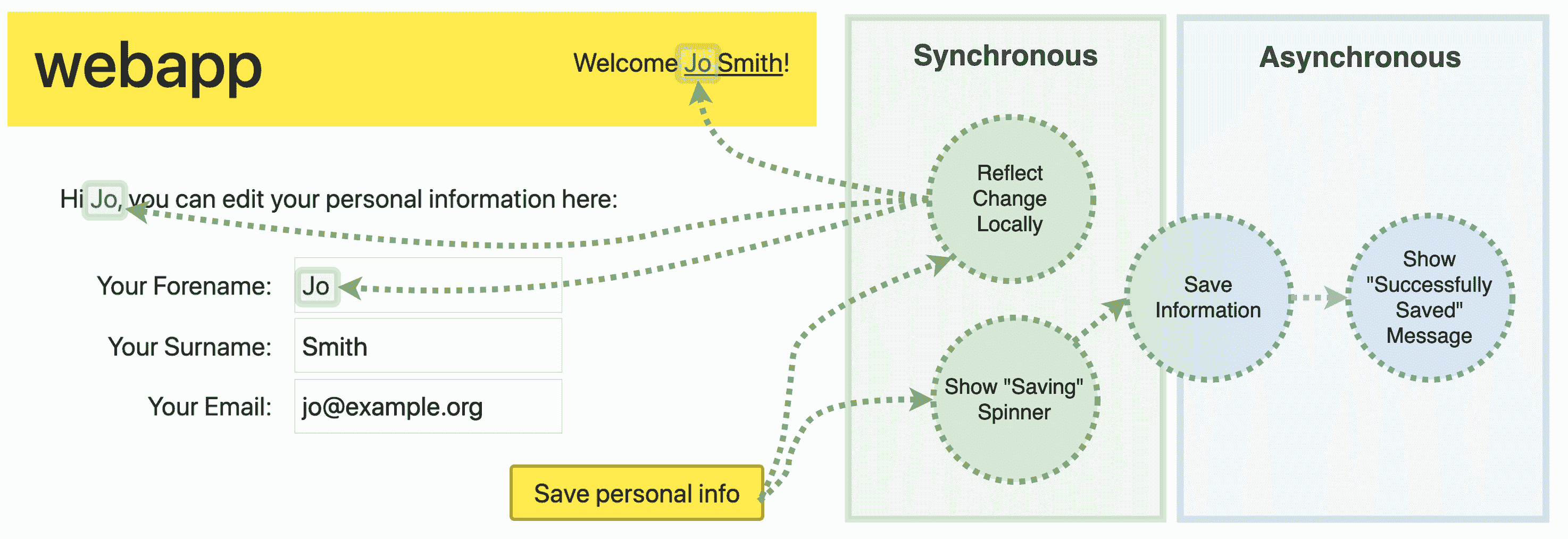
在传统的非 spa 中,Save personal info 按钮只需提交一个<form>,页面就会完全重新加载,并从服务器发送一个全新的带有更新状态的标记块。 在 SPA 中,它稍微复杂一些。 我们需要将数据提交到服务器,然后以某种方式仅用新数据更新页面的相关部分。
为了解决这个问题,我们必须仔细考虑应用中的数据流或状态。 面临的挑战是尽快在所有需要体现的地方反映出相关数据的真实来源。 为了实现这一点,我们需要一种方法让代码库的不同部分相互通信。 这里有几个我们可以使用的范例:
-
面向事件:这意味着具有特定的全局事件,可以发出并侦听(例如,
userProfileNameChange)。 然后,页面中的任何组件或视图都可以绑定到此事件,并通过更新其内容做出相应的反应。 因此,状态同时存在于许多不同的区域(在各种组件或视图之间)。 - 面向状态:这意味着拥有一个全局状态对象,该对象包含用户名的单个真实源。 这个状态对象,或者它的一部分,可以递归地通过组件树向下传递,这意味着,在任何更改时,整个组件树都会被提供新的状态。 因此,状态是集中的,但无论何时发生变化都会传播。
如果我们考虑一个用户通过<input />改变他们的名称,我们可以设想以下不同的路径的数据流到所有依赖于名称数据的组件:

从根本上说,这些方法实现了相同的事情:它们将数据呈现给 DOM。 关键的不同之处在于更改(在本例中是名称的更改)如何在整个应用中进行通信,以及数据在任何时候驻留在哪里:
- 事件导向范式的数据同时存在于多个地方。 因此,如果由于某种原因,其中一个地方未能绑定到该事件的突变,那么您可能会以不同步的数据表示告终。
- 面向状态的范式只有一个数据的规范表示,有效地将数据输送给相关视图或组件,因此它们总是使用最新版本。
面向状态的范式是越来越普遍的方法,因为它使我们能够以更清晰的方式思考我们的数据及其表示。 我们可以说,我们有一个单一的数据表示,我们从该数据派生组件(或 UI)。 这是一种纯功能的方法,因为组件实际上只是一个确定的数据到给定 UI 的映射。 因为任何给定的组件只关心它的输入数据,所以它不需要对它所处的环境做太多的假设。 例如,我们可能有一个UserInfo组件,有四个预期输入值:
{
forename: 'Leah',
surname: 'Brown',
hobby: 'Kites',
location: 'Edinburgh'
}由于该组件不依赖于任何全局事件或其他上下文假设,因此可以很容易地将其隔离。 这不仅有助于理解和可维护性,而且使我们能够编写更简单的测试。 UserInfo组件可以自己提取和测试,与它最终驻留的应用没有相互依赖关系。
React 是表达这种面向状态范式的流行框架,但许多其他框架也在效仿。 在 React 中,结合 JSX,我们可以这样表达我们的UserInfo组件:
function UserInfo({ forename, surname, hobby, location }) {
return (
<div>
<h1>User Info</h1>
<dl>
<dt>Forename:</dt> <dd>{forename}</dd>
<dt>Surname:</dt> <dd>{surname}</dd>
<dt>Hobby:</dt> <dd>{hobby}</dd>
<dt>Location:</dt> <dd>{location}</dd>
</dl>
</div>
);
}在这里,我们可以看到这个组件的输出仅仅是它的输入的映射。 这样一个简单的 I/O 案例可以很容易地进行测试和推理。 这让人回想起的美丽迪米特法则(LoD),我们在第四章,【显示】固体和其他原则,这告诉我们,UserInfo组件没有业务知道其数据来自或地方; 它只需要完成它唯一的职责:从它的四个输入,它只需要为我们提供一个干净漂亮的 DOM 层次结构。
当然,现实生活中的 web 应用要复杂得多,我们无法用我们的名字举例说明。 然而,如果我们记住了分离关注点的基础,以及构建隔离良好且功能纯粹的视图或组件,那么就会有一些我们无法干净地解决的挑战。
在构建 web 应用时,我们可能需要改变用户在浏览器中看到的地址,以反映当前正在访问的资源。 这是浏览器和 HTTP 工作的核心原则。 HTTP 地址应该表示资源。 因此,当用户希望更改他们正在查看的资源时,地址应该相应地更改。
历史上,在浏览器中改变当前 URL 的唯一方法是用户通过<a href>或类似的导航到不同的页面。 然而,当 spa 开始流行时,JavaScript 程序员需要变得有创造性。 在早期,一个受欢迎的黑客是变异的散列组件的 URL(example.org/path/#hash),这将给用户的体验穿越传统的网站,每个导航或行动将导致一个新的地址,浏览器的历史上一个新的条目, 因此可以使用浏览器中的后退和前进按钮。
*The approach of mutating the #hash of a URL was famously used in Google's Gmail application when it launched in 2004 so that the address bar in the browser would accurately express what email or view you were currently looking at. Many other SPAs followed suit.
幸运的是,几年后,History API 找到了进入浏览器的方法,现在它是更改地址以响应 SPA 中的导航或操作的标准。 具体来说,这个 API 允许我们通过推入新的状态或替换当前状态来操纵浏览器会话历史。 例如,当用户在一个虚构的 SPA 中表示希望更改为About Us视图时,我们可以将其表示为推入其历史的新状态,如下所示:
window.history.pushState({ view: 'About' }, 'About Us', '/about');这将立即将浏览器中的地址更改为'/about'。 通常,调用代码还会触发相关视图的呈现。 Routing 是指呈现新 DOM 和改变浏览器历史的组合过程。 具体来说,路由器承担以下责任:
- 呈现与当前地址对应的视图、组件或页面
- 将接口公开给其他代码,以便引导导航
- 监听用户对地址的更改(
popstate事件)
为了说明这些职责,我们可以为应用创建一个简单的路由器,它可以非常简单地在 URL 路径中表示的任何颜色的背景上显示Hello {color}!。 因此,/red将渲染红色背景文字Hello red!。 和/magenta将渲染一个品红背景与文本,Hello magenta!:

下面是我们的colorRouter实现:
const colorRouter = new class {
constructor() {
this.bindToUserNavigation();
if (!window.history.state) {
const color = window.location.pathname.replace(/^\//, '');
window.history.replaceState({ color }, color, '/' + color);
}
this.render(window.history.state.color);
}
bindToUserNavigation() {
window.addEventListener('popstate', event => {
this.render(event.state.color);
});
}
go(color) {
window.history.pushState({ color }, color, '/' + color);
this.render(color);
}
render(color) {
document.title = color + '!';
document.body.innerHTML = '';
document.body.appendChild(
document.createElement('h1')
).textContent = 'Hello ${color}!';
document.body.style.backgroundColor = color;
}
};Notice how we're using the Class Singleton pattern here (as introduced in the last chapter). Our colorRouter abstraction is well-suited to this pattern as we need specific construction logic and we want to present a singular interface. We could have also used the Revealing Module pattern.
使用这个路由器,我们可以用我们的颜色调用colorRouter.go(),它会改变地址,并按预期呈现:
colorRouter.go('red');
// Navigates to `/red` and renders "Hello red!"即使在这个简单的场景中,我们的路由器也有一些复杂性。 当用户最初通过传统的浏览页面上的土地,例如,也许通过example.org/red输入地址栏,历史状态的对象将是空的,当我们还没有告知浏览器会话,/red与状态,{ color: "red" }。
为了填充这个初始状态,我们需要获取当前的location.pathname(/red),然后通过删除初始的斜杠从它提取颜色。 你可以在构造函数colorRouter中看到这样的逻辑:
if (!window.history.state) {
const color = window.location.pathname.replace(/^\//, '');
window.history.replaceState({ color }, color, '/' + color);
}对于更复杂的路径,这个逻辑可能会变得相当复杂。 在一个典型的路由器中,需要容纳许多不同的路径模式。 因此,通常会使用 URL 解析库来正确地提取 URL 的每个部分,并允许路由器正确地路由该地址。
It's important to use a properly constructed URL parsing library for use in production routers. Such libraries tend to accommodate all of the edge-cases implicit in URLs, and should ideally be compliant with the URI specification (RFC 3986). An example of this would be URI.js (available on npm as uri-js).
多年来,大型框架中出现了各种路由库和路由抽象。 它们呈现给程序员的界面都略有不同。 例如,React Router 允许你通过 JSX 语法将独立路由声明为一系列 React 组件:
function MyApplication() {
return (
<Router>
<Route exact path="/" component={Home} />
<Route path="/about/:employee" component={AboutEmployee} />
</Router>
);
}Vue.js 是一个不同的框架,它提供了自己独特的路由抽象:
const router = new VueRouter({
routes: [
{ path: '/', component: Home }
{ path: '/about/:employee', component: AboutEmployee }
]
})您可能会注意到,在这两个示例中,都有一个指定为/about/:employee的 URL 路径。 冒号后面跟着一个给定的标记或单词,这是一种常用的方式,用来表示路径的特定部分是动态的。 通常需要动态响应 URL,该 URL 包含关于特定资源的标识信息。 这是合理的,所有以下页面应该产生不同的内容:
/about/john/about/mary/about/nika
将这些全部指定为单独的路由(对于大型数据集来说几乎是不可能的)会非常麻烦,所以路由器总是有某种方式来表达这些动态部分。 url 的层次性质通常也反映在路由器提供的声明性 api 中,通常允许我们指定组件或视图的层次结构,以响应这种层次结构的 url。 下面是一个可以传递给 Angular(另一个流行框架!)的 Router 服务的routes名称示例:
const routes = [
{ path: "", redirectTo: "home", pathMatch: "full" },
{ path: "home", component: HomeComponent },
{
path: "about/:employee",
component: AboutEmployeeComponent,
children: [
{ path: "hobbies", component: EmployeeHobbyListComponent },
{ path: "hobbies/:hobby", component: EmployeeHobbyComponent }
]
}
];我们可以看到,AboutEmployeeComponent附着在about/:employee路径上,其子组件分别附着在hobbies和hobbies/:hobby路径上。 像/about/john/hobbies/kayaking这样的地址会直观地渲染AboutEmployeeComponent,而在其中渲染EmployeeHobbyComponent。
你可以在这里观察到路由器和渲染是如何纠缠在一起的。 有独立的路由库确实是可能的,但是框架提供自己的路由抽象更为典型。 这允许我们在视图、组件或小部件旁边指定我们的路由,或者框架为将事物呈现给 DOM 提供的任何抽象。 从根本上说,尽管这些前端路由抽象在表面上有所不同,但它们将实现相同的结果。
许多 JavaScript 程序员面临的另一个现实世界的挑战是依赖项管理,无论他们主要工作在客户端还是服务器端。 接下来我们将开始探索这个问题。
在单一网页的上下文中加载 JavaScript 过去很简单。 我们可以简单地在文件来源的某个地方放置几个<script>标签,然后就结束了。
然而,这些年来,随着用户需求的增加,我们的 JavaScript 的复杂性也在急剧增长。 与此同时,我们的代码库也在增长。 在一段时间内,不断添加更多的<script>标签是很自然的。 然而,在某种程度上,这种方法并不可靠。 除了在每次页面加载时产生多个 HTTP 请求的负担之外,这种方法还使程序员很难平衡它们的依赖关系。 在那些日子里,JavaScript 是典型的,花时间仔细排序<script>位置,这样,对于任何特定的脚本,它的依赖在它自己加载之前就到位了。
这样的 HTML 标记并不少见:
<!-- Library Dependencies -->
<script src="/js/libs/jquery.js"></script>
<script src="/js/libs/modernizr.js"></script>
<!-- Util Dependencies -->
<script src="/js/utils/data.js"></script>
<script src="/js/utils/timer.js"></script>
<script src="/js/utils/logger.js"></script>
<!-- App Widget Dependencies -->
<script src="/js/app/widgets/Nav.js"></script>
<script src="/js/app/widgets/Tile.js"></script>
<script src="/js/app/widgets/PicTile.js"></script>
<script src="/js/app/widgets/PicTileImage.js"></script>
<script src="/js/app/widgets/SocialButtons.js"></script>
<!-- App Initialization -->
<script src="/js/app/init.js"></script>从性能的角度来看,这种方法是昂贵的,因为浏览器在继续解析和呈现剩下的文档之前必须获取每个资源。 因此,HTML 文档的<head>内嵌脚本的大量集合被认为是反模式,因为它们会阻碍用户在很长一段时间内使用网站。 即使将脚本移动到<body>的底部也不是理想的,因为浏览器仍然需要连续加载和执行它们。
可以预见的是,我们日益复杂的应用开始超越这种方法。 开发人员需要更好的性能和更精细的脚本加载控制。 值得庆幸的是,这些年来,我们在如何管理依赖项、如何捆绑它们以及如何将代码库提供给浏览器方面都取得了各种改进。
在本节中,我们将探索这些年来发生的改进,并试图理解当前的最佳实践是什么。
在 2010 年之前(大约),在浏览器中加载大型复杂 JavaScript 代码库的方法很少有共识。 然而,很快,开发人员创建了异步模块定义(AMD)格式。 这是在 JavaScript 中定义模块的标准的第一次流行尝试。 它既包括声明每个模块上的依赖项的能力,也包括异步加载机制。 这是对多个内联<script>标签缓慢和阻塞特性的巨大改进。
RequireJS 是一个支持这种格式的流行库。 要使用它,你只需要在文档中放置一个单一的入口点<script>:
<script data-main="scripts/main" src="scripts/require.js"></script>这里的data-main属性将指定我们的代码库的入口点,然后它自己将加载初始的依赖集和初始化应用,像这样:
requirejs([
"navigationComponent",
"chatComponent"
], function(navigationComponent, chatComponent) {
// Initialize:
navigationComponent.render();
chatComponent.render();
});每个依赖项会define自己和自己的依赖项,像这样:
// The Navigation Component AMD Module
define(
// Name of the module
'navigationComponent',
// Dependencies of the module
['utilA', 'utilB'],
// Definition of the module returned from function
function (utilA, utilB) {
return /* Definition of navigationComponent */;
}
);这在精神上与现在 ECMAScript 规范中指定的模块相似,除了 AMD 与任何特定的语言语法无关。 将模块之类的东西引入 JavaScript 完全是社区驱动的努力。
AMD 规定每个模块都是在一个回调中定义的,依赖项可以传递给这个回调,这意味着像 RequireJS 这样的加载工具可以异步加载所有的依赖项,然后在完成后调用回调。 这是一个重大的推动前端 JavaScript 时,因为这意味着我们可以很容易地加载大量依赖图的方式缓解的过程(更少依赖杂耍)编写代码,使代码加载到浏览器在一个非阻塞性能的方式。
在与 AMD 类似的时间,一种新的标准驱动的努力开始出现,称为CommonJS。 这试图使require(...)语法成为各种非浏览器环境中的标准,并希望这种语法最终也能在前端得到支持。 下面是一个 CommonJS 模块的例子(如果你习惯了在 Node.js 中编程,这可能看起来很熟悉):
const navigationComponent = require('components/navigation');
const chatComponent = require('components/chat');
module.exports = function() { /* exported functionality */ };这成为了各种非浏览器环境的标准,如 Node.js、SproutCore 和 CouchDB。 也可以使用 CommonJS 编译器将你的 CommonJS 模块编译成类似于 AMD 的浏览器可使用脚本。 在此之后,大约在 2017 年,ES 模块应运而生。 这给了我们对import和export语句的语言支持,有效地解决了如何在 JavaScript 中定义模块的历史挑战:
// ES Modules
import navigationComponent from 'components/navigation';
import chatComponent from 'components/chat';
export default function() { /* do stuff */ };在 Node.js 中,这些模块的文件名后缀必须是.mjs而不是.js,这样引擎就知道应该是import和export,而不是传统的 CommonJS 模块定义语法。 在浏览器中,可以使用<script type="module">进行加载。 然而,即使浏览器支持 ES 模块,构建和捆绑 JavaScript 到传统的非模块化脚本标记仍然是可取的。 这是由于性能和跨浏览器兼容性的因素。 不过不要担心:我们仍然可以在编写代码时使用 ES 模块! Babel 之类的工具可用于将最新的 JavaScript 语法编译并打包成跨许多环境兼容的 JavaScript。 将 Babel 之类的工具设置为构建和开发过程的一部分是典型的做法。
在过去,JavaScript 社区没有可用的包管理器。 相反,个人和组织通常会自己发布代码,使开发人员能够手动下载最新版本。 随着 Node.js 和 npm 的引入,这一切都改变了。 最后,有一个中心的包存储库可以轻松地拉入我们的项目中。 这不仅对服务器端 Node.js 项目有用,而且对整个前端项目也有用。 npm 的出现可能是促使 JavaScript 生态系统走向成熟的最重要事件之一。
如今,每一个涉及 JavaScript 的项目都会在顶级的package.json文件中列出清单,通常至少会指定一个名称、描述、版本和版本依赖项列表:
{
"name": "the-fruit-lister",
"description": "An application that lists types of fruits",
"version": "1.0",
"dependencies": {
"express": "4.17.1"
},
"main": "app/init.js"
}在package.json中有各种各样的可用字段,所以有必要研究一下 npm 文档来理解所有这些字段。 下面是一些最常见的问题:
-
name:包装的名称可能是最重要的东西。 如果您计划将包发布到 npm,那么这个名称必须是唯一的。 -
description:这是对你的模块的简要描述,以帮助开发人员理解它的用途。 更详细的信息通常放在README或README.md文件中。 -
version:这是一个Semantic Versioning(SemVer)兼容的版本(形式为[Major].[Minor].[Patch],例如5.11.23)。 -
dependencies:这是一个将每个依赖包名称映射到一个版本范围的对象。 版本范围是一个具有一个或多个空格分隔的描述符的字符串。 依赖项也可以指定为 tarball/Git URL。 -
devDependencies:这在功能上与dependencies相同,除了它只用于开发过程中需要的依赖项,如代码质量分析器和测试库。 -
main:这可以引用模块 ID,它是程序的主要入口点。 例如,如果您的包被命名为super-utils,并且有人安装了它,然后做了require("super-utils"),那么您的main模块的导出对象将被返回。
npm assumes that your package and any packages you rely on follow the rules of SemVer, which uses a pattern of [Major].[Minor].[Patch] (for example, 1.0.2). SemVer prescribes that any breaking changes must result in the major portion incrementing, whereas backward-compatible feature additions should result in only the \minor portion incrementing, and backward-compatible bug fixes should result in the patch portion incrementing. Full details can be found at https://semver.org/.
在package.json所在的目录下运行npm install会导致 npm 下载指定的依赖项版本。 在声明依赖项时,默认情况下,npm 将附加一个插入符号(^),这意味着 npm 将选择与指定的主版本一致的最新可用版本。 因此,如果指定了^1.2.3,则可以有效地安装1.99.99(等等)以内的任何内容。
有几个模糊版本范围,您可以使用:
-
version:必须与version完全匹配 -
>version:必须大于version -
>=version:必须大于等于version -
<version:必须小于version -
<=version:必须小于等于version -
~version:约等于version(仅增加补丁部分) -
^version:兼容version(只增加次要/补丁部分) -
1.2.x:1.2.0、1.2.1等,但不包括1.3.0(此处x有意义)
有争议的是,npm 最大的问题是,未经检查的新包的引入和它们在功能方面的粒度已经导致项目具有难以置信的庞大和笨拙的依赖图。 有些单独的包只导出单一的、狭窄的实用函数,这种情况并非闻所未闻。 例如,除了通用的字符串实用程序包之外,您可能还会发现一个特定的字符串函数作为它自己的包,例如大写的。 这些包本身并没有问题——它们中的许多都有有用的用途——但是一个笨拙的依赖关系图可能会导致它自己的问题。 任何流行的包,无论是被破坏的,还是没有严格遵循 SemVer,都可能导致问题在整个 JavaScript 生态系统中传播,最终影响您的项目。
To help to prevent bugs and security issues, it is highly recommended to specify your dependencies with fixed versions and update dependencies manually only when you have checked their respective changelogs. Nowadays, some tools can help you to keep dependencies up to date without sacrificing security (for example, dependabot, owned by GitHub).
建议使用依赖关系管理系统确保下载包的完整性与密码散列(一个校验和,突出恶意更改),以确保包你最终执行肯定是你打算安装并没有在传输过程中受损或损坏。 Yarn 就是这样一个系统的例子(参见https://yarnpkg.com)。 它实际上是 npm 上一个更安全、更高效的抽象。 除了更安全之外,Yarn 还可以避免不一致的包解析,即当对给定代码库的依赖项进行两次安装时,下载的依赖项可能会不同(由于 npm 版本声明的模糊特性)。 这种不一致可能导致相同的代码库在两个实例中表现不同(这是一个非常令人头痛的问题,也是 bug 的前兆!) Yarn 将当前的锁定依赖关系图、对应的版本和校验和存储在一个yarn.lock文件中,如下所示:
# THIS IS AN AUTOGENERATED FILE. DO NOT EDIT THIS FILE DIRECTLY.
# yarn lockfile v1
array-flatten@1.1.1:
version "1.1.1"
resolved "https://registry.yarnpkg.com/array-flatten/-/array-flatten-1.1.1.tgz#9a5f699051b1e7073328f2a008968b64ea2955d2"
integrity sha1-ml9pkFGx5wczKPKgCJaLZOopVdI=
...这里,我们只看到一个依赖项,但通常会有成百上千的依赖项,因为它不仅包括你的直接依赖项,还包括那些依赖项的依赖项。
依赖性管理是一个已经写了很多关于它的话题,所以如果你上网查看,就会发现并不缺乏意见和解决方案。 从根本上说,由于我们关注的是干净的代码,我们应该回到我们的原则。 首先,我们应该在依赖系统和依赖本身中寻求的是可靠性、效率、可维护性和可用性。 在依赖关系的上下文中,当涉及到可维护性时,我们感兴趣的是我们维护使用并依赖于依赖关系的代码的能力,以及依赖关系的维护者保持依赖关系最新且无 bug 的能力。
在 JavaScript 领域,大约在 AMD 和 CommonJS 开始出现的同时,命令行绑定器和构建工具也在崛起。 这使我们能够将大型依赖关系图捆绑到单个文件中,这些文件可以用单个<script>加载。 像 GruntJS 和 gulp.js 这样的构建工具的普及意味着,慢慢地,我们作为程序员编写的 JavaScript 可以更加清晰和易于理解,而不是浏览器的加载特性。 我们也可以开始利用派生语言和子集,如 CoffeeScript、TypeScript 和 JSX。 这样的 JavaScript 改编可以很容易地编译,然后捆绑成完全可操作的 JavaScript 发送到浏览器。
我们现在所处的世界是一个构建和捆绑工具非常普遍的世界。 有几个特定的构建工具,如 Grunt、gulp.js、webpack 和 Browserify。 此外,开发人员可以很容易地使用 npmscripts指令创建常用命令行指令的快捷方式。
通常,构建涉及到任何需要在开发代码基础上进行的准备工作,以使它们能够用于生产。 这可以包括从检查 CSS 到绑定 JavaScript 的任何事情。 具体来说,捆绑涉及将大型依赖关系图(JavaScript 文件)编译并整理成单个 JavaScript 文件。 这是必要的,以便我们能够以最高效和兼容的方式为浏览器提供 JavaScript 代码库。 捆绑工具通常会输出一个文件,文件内容的散列作为文件名的一部分,例如,main-f522dccf1ff37b.js。 这个文件名可以动态或静态地插入到 HTML 中的<script>标签中,以提供给浏览器:
<script src="/main-f522dccf1ff37b.js"></script>文件名中包含文件内容的散列可以确保浏览器总是加载更新后的文件,而不依赖于之前缓存的文件版本。 这些文件通常也被缩小。 最小化包括解析 JavaScript 并生成一个功能相同但更小的表示,并采取所有可能的措施来占用更少的空间,如缩短变量名和删除空格和换行符。 它与 HTTP 压缩技术(如.gzip)结合使用,以确保从服务器到客户端的 HTTP 传输尽可能小和快。 通常,你会有不同的开发和生产构建,因为一些构建步骤,比如最小化,会使开发(和调试!)更加困难。
为浏览器提供绑定的 JavaScript 通常是通过一个单一的<script>标签引用绑定的 JavaScript 文件名,该文件名位于你为浏览器提供的 HTML 中的某个地方。 在选择方法时,有几个重要的性能考虑因素。 最重要的指标是,从初始请求开始,用户可以多快地开始使用应用。 当加载 superWebApp.example.com 时,我们可以想象用户可能经历的延迟:
- :每个资源获取可能涉及 DNS 查找,SSL 握手,完成 HTTP 请求和响应周期。 响应通常是流的,这意味着浏览器可能在响应完成之前就开始解析它。 浏览器通常并发地发出适量的请求。
-
解析 HTML:这涉及到浏览器解析每个标记名,并反复构建 HTML 的 DOM 表示。 一些遇到的标签会导致新的可获取资源进入队列,如
<img src>、<script src>或<link type="stylesheet" href>。 - 解析 CSS:这涉及到浏览器解析任何获取的 CSS 中的每个规则集。 引用的资源,比如背景图片,只有在页面上找到相应的元素时才会被获取。
- 解析/编译 JavaScript
- :这将只发生一次,当所有的 CSS 已经加载。 如果有异步加载的 CSS 或其他美学资源(如字体或图像),那么可能有几次重绘/重新渲染页面可以考虑完全渲染。
-
执行 JavaScript:根据对应的
<script>的位置,一段 JavaScript 将执行,然后可能会改变 DOM 或执行自己的取回。 这可能会阻止任何其他抓取/解析/呈现的发生。
通常情况下,最好是在浏览器完成所有其他工作之后才执行 JavaScript。 然而,这并不总是理想的。 加载重要资源可能需要一些 JavaScript,因此应该尽早执行这些 JavaScript,以便那些 HTTP 获取可以与浏览器的其他准备工作同时进行。
放置主绑定的<script>(您的main代码基)对于决定 JavaScript 何时被获取、何时执行以及 DOM 执行时的状态是至关重要的。
以下是最受欢迎的<script>位置及其各自的优势:
-
<head>内的<script src>:解析过程中遇到<script>就会取该脚本。 获取和执行将按顺序进行,并将阻止其他解析的发生。 这被认为是一种不好的做法,因为它不必要地阻碍了对文档其余部分的继续解析(从用户的角度来看,因此增加了页面加载的延迟)。 -
<script src>at the end of<body>:解析过程中一旦遇到<script>,就会获取该脚本。 获取和执行将以串行方式进行,并将阻止其他解析的发生。 通常,解析可以被认为是基本完成的,因为<script>是<body>中的最后一件事。 -
<script src defer>在<head>:此脚本将进行入队抓取一旦遇到<script>在解析期间,这取会发生并发的解析 HTML 浏览器方便一次。 该脚本只在整个文档被解析后执行。 -
<script src async>在<head>:此脚本将进行入队抓取一旦遇到<script>在解析期间,这取会发生并发的解析 HTML 浏览器方便一次。 脚本的执行将在获取后立即执行,并将阻止继续解析。
在<head>中有<script defer>通常是更好的,因为它可以尽快获取,它不会阻碍解析,并且只有在解析完成后才会执行。 如果您提供一个单一的捆绑脚本,并为 JavaScript 提供一个可以立即操作和呈现的完全解析的 DOM,那么这往往会给用户以最快的体验。
事实上,向浏览器提供 JavaScript 是一件简单的事情。 为了用户的利益,我们需要让我们的 web 应用快速运行,这只会让情况变得更加复杂。 越来越复杂的 JavaScript 代码库产生越来越大的包,因此加载这些包需要时间。 因此,您可能需要认真对待 JavaScript 的加载性能,并花时间进行研究。 性能很容易被遗忘,但却非常重要。
JavaScript 生态系统中另一个同样容易被遗忘的主题是安全性,这也是我们现在要探讨的。
安全性是可靠代码库的重要组成部分。 对于用户来说,有一个隐含的假设,即任何给定的软件都将按照其功能预期运行,不会导致他们的数据或设备的损坏。 干净的代码考虑安全性就像它考虑其他功能期望一样——作为一个重要的需求,应该仔细地实现和彻底地测试。
由于 JavaScript 主要用于网络环境——无论是在服务器端还是客户端,它永远都充满了安全漏洞的可能性。 事实上,浏览器是远程代码执行的沙箱工具,这意味着我们的终端用户和我们一样容易受到风险的影响。 为了保护我们自己和我们的用户,我们需要对存在的漏洞类型以及如何应对它们有不同的理解。 有大量关于安全漏洞的吓人信息。 我们不能期望在本书中涵盖所有这些漏洞,但如果我们探索了几个常见的漏洞,那么我们将更加谨慎和意识到,并开始理解我们应该采取的措施类型。
(XSS)是一种漏洞,攻击者可以将自己的可执行代码(通常是 JavaScript)注入到 web 应用的前端,这样浏览器就会像被信任的那样运行。 XSS 可以通过多种方式显示,但这些都可以归结为两种核心类型:
-
存储 XSS:这涉及到攻击者以某种方式将看似无害的数据中的可执行代码保存到 web 应用中,并将其持久化,然后返回给 web 应用的其他用户。 一个简单的例子是一个社交媒体网站,它允许我指定我的名字为 HTML(例如,
<em>James!</em>),但不阻止包含潜在危险的可执行 HTML,允许我指定一个名字,如<script>alert('XSS!')...。 -
反射 XSS:这涉及到攻击者将受害者发送到一个 URL,同时将他们的可执行有效负载与请求一起发送,在 URL、HTTP 头或请求体中。 然后当用户到达页面时执行此可执行有效负载。 这方面的一个例子是一个搜索页面,它将查询返回给用户(这是任何搜索页面的共同特征),但以一种无法逃离 HTML 的方式执行,这意味着攻击者只需要将受害者发送到
/search?q=<script>alert('XSS!')...。
在这里,在页面中呈现存储或反射有效负载的方式非常关键。 传统上,XSS 向量仅限于服务器端呈现未转义的用户输入 HTML。 因此,如果 Bob 将他的社交媒体帐户名设置为<script>alert("Bob's XSS")...,那么当从服务器请求 Bob 的页面时,返回的标记将包括准备由浏览器解析和执行的<script>。 然而,如今,涉及客户端呈现的 spa 和网站要普遍得多,这意味着不是服务器的错误在于允许未转义的 HTML 进入文档标记,而是客户机(JavaScript 代码基)的错误在于直接将危险内容呈现到 DOM 中。 因此,依赖于客户端呈现的 XSS 攻击通常被称为基于 dom 的 XSS。
XSS payloads can come in a variety of forms. It's very rarely as simple as a <script> tag. Attackers use a variety of complex encodings, archaic HTML, and even CSS to embed their nefarious JavaScript. Cleansing XSS from strings is therefore not trivial and it is instead recommended to place no trust whatsoever in user-entered content.
我们可以想象这样一个场景,在这个场景中,我们的 JavaScript 代码库有一个UserProfile组件,它呈现任何用户的名称和概要信息。 在初始化时,该组件从一个看起来像/profile/{id}.json的 REST 端点请求数据,返回以下 JSON:
{
"name": "<script>alert(\"XSS...\");</script>",
"hobby": "...",
"profielImage": "..."
}然后该组件通过innerHTML将接收到的名称呈现给 DOM,而不转义或清理其内容:
class UserProfile extends Component {
// ...
render() {
this.containerElement.innerHTML = `<h1>${this.data.name}</h1>`;
this.containerElement.innerHTML += `<p>Other profile content...</p>`;
}
}所有渲染UserProfile组件的用户都有可能执行任意的(潜在的破坏性的)HTML。 无论任意 HTML 来自反射源还是存储源,这都是一个问题。
抽象 DOM 呈现的通用 JavaScript 框架的流行意味着攻击者只需在库或框架中找到一个漏洞,就可以攻击数千个不同的网站。 幸运的是,大多数框架在默认情况下都有插值机制,强制将插入的数据呈现为文本,而不是 HTML。 例如,React 总是会为通过 JSX 的插值分隔符(花括号)插入的任何数据生成文本节点。 我们可以在这里看到这个效果:
function Stuff({ msg }) {
return <div>{msg}</div>
}
const msg = '<script>alert("Oh no!");</script>';
ReactDOM.render(<Stuff msg={msg} />, document.body);这将导致包含<script>的数据被字面上呈现为文本,因此<body>元素的结果innerHTML如下所示:
<div>
<script>alert("Oh no!");</script>
</div>因为潜在的危险 HTML 被呈现为文本,所以不会发生执行,XSS 攻击也被阻止了。 不过,这并不是发生 XSS 攻击的唯一方式。 客户端框架通常会有依赖内联<script>标签的模板解决方案,比如:
<script type="text/x-template">
<!-- VueJS Example -->
<div class="tile" @click="check">
<div :class="{ tile: true, active: active }"></div>
<div class="title">{{ title }}</div>
</div>
</script>这是一个方便的方式声明模板中使用后呈现特定的组件,但这样的模板中经常使用结合服务器端渲染和插值,这样的组合是容易 XSS 如果攻击者可以强迫一个危险的字符串由服务器插入到模板,如下所示:
<!-- ERB (Rails) Template -->
<script type="text/x-template">
<!-- VueJS Template -->
<h1>Welcome <%= user.data.name %></h1>
</script>如果user.data.name包含恶意的 HTML,那么我们的 JavaScript 在客户端无法阻止攻击。 当我们呈现代码时,可能已经太晚了。
在现代的 web 应用中,我们必须警惕 XSS,无论是存储的还是反射的,在服务器和客户机上呈现的。 这是一个令人费解的组合,可能的向量,所以至关重要的是,确保你采取了一系列对策:
- 永远不要相信用户输入的数据。 理想情况下,不允许用户输入任何 HTML。 如果可以,则使用 HTML 解析库,并将信任的特定标记和属性列入白名单。
- 永远不要把不可信的数据放在 HTML 注释,
<script>元素,<style>元素,或者 HTML 标签或属性名应该出现的地方(例如,<HERE ...>或<div HERE=...>)。 如果必须,把它放在 HTML 元素中,并确保它完全转义(例如,&→&和"→")。 - 如果在常规(非 javascript) HTML 属性中插入不受信任的数据,则使用
&#xHH;格式转义所有小于256的 ASCII 值。 如果插入到常规 HTML 元素的内容中,则转义以下字符即可:&、<、>、"、'和/。 - 避免将不可信的数据插入 JavaScript 执行的区域,如
<script>x = 'HERE'</script>或<img onmouseover="x='HERE'">,但如果绝对必须,请确保数据被转义,以便它不能打破其引号或其包含的 HTML。 - 不是将 javascript 可读的数据嵌入到
<script>中,而是使用 JSON 将数据传输到客户端,要么通过请求,要么通过将数据嵌入到<div>这样的无操作元素中(确保它是完全 html 转义的!),然后自己提取并反序列化。 - 使用适当限制的内容安全策略(CSP)(我们将在下一节对此进行解释)。
这些对策并不详尽,所以建议也彻底 readthrough打开 Web 应用安全性项目(OWASP)跨站点脚本预防备忘单:https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html[【5】。](https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html)
作为一种额外的安全措施,配置一个适当的 CSP 也很重要。
CSP 是一个相对较新的 HTTP 报头,所有现代浏览器都可以使用它。 它是而不是普遍支持或尊重的,所以不应该依赖它作为我们对付 XSS 的唯一防御手段。 然而,如果正确配置,它可以防止大多数 XSS 漏洞。 不支持 CSP 的浏览器将退回到同源策略的默认行为,而同源策略本身提供了关键的安全级别。
The same-origin policy is a vital security mechanism employed by all browsers that restricts the ability of documents or scripts when accessing some resources from other origins (origins match when they share the same protocol, port, and host). This policy means that, for example, JavaScript within leah.example.org cannot fetch alice.example.org/data.json. With the advent of CSP, it is, however, possible for alice.example.org to express a level of trust and provide such access by disabling the same-origin policy just for leah.example.org.
Content-Security-Policy标题允许你指定不同类型的资源可以从哪里加载。 它本质上是一个原始白名单,浏览器将验证所有发出的请求。
它可以被指定为一个普通的 HTTP 报头:
Content-Security-Policy: default-src 'self'或者可以指定为meta标签:
<meta http-equiv="Content-Security-Policy" content="default-src 'self'">该值的格式为一个或多个策略指令,以“;”分隔,每个策略指令以fetch指令开始。 这些参数指定了资源的类型(例如,img-src,media-src,和font-src),或者默认的(default-src),如果不是单独指定的话,所有指令都将返回。 fetch 指令后面跟着一个或多个用空格分隔的源,每个源指定该资源类型的资源可以从哪里加载。 可能的来源包括 url、协议、'self'(引用文档本身的来源)等等。
以下是一些 CSP 值的例子,并对每个值进行了解释:
-
default-src 'self':这是一个限制最大的指令,声明只能在文档中加载来自文档本身的资源(无论是从<img>、<script>、XHR 还是其他任何地方)。 不允许有其他来源。 -
default-src 'self'; img-src cdn.example.com:该指令声明只能从文档本身的来源加载资源,除了图像(例如,<img src>和 css 声明的图像),它可以从来源cdn.example.com加载。 -
default-src 'self' *.trusted.example.com:声明只有来自同一来源或的资源是有效的*.trusted.example.com。 -
default-src https://bank.example.com:声明只能加载来自 ssl 安全来源https://bank.example.com的资源。 -
default-src *; script-src https::声明资源可以从任何有效的 URL 加载,但<script src>除外,<script src>必须从 HTTPS URL 加载资源。
什么是适当的限制性 CSP 完全取决于您的特定 web 应用,您可能正在处理的用户生成内容的类型,以及您处理的数据的敏感性。 拥有一个合适的 CSP 不仅可以保护您不创建潜在的 XSS 向量(通过从潜在的受损源加载),还可以帮助抵消执行 XSS 漏洞。 CSP 通过以下具体方式来防御 XSS:
- CSP 使
eval()和其他类似技术失效。 这些是 XSS 的常见向量,特别是在使用这些方法解析 JSON 的旧浏览器中。 如果您愿意,可以通过'unsafe-eval'源显式启用eval。 - CSP 禁用内联
<script>和<style>标签、JavaScript 协议和内联事件句柄(例如,<img onload="..." />)。 这些都是常见的 XSS 向量。 你可以通过指定unsafe-inline作为相关获取指令的源来显式地启用这些功能,但建议你从外部源加载脚本和样式,这样浏览器就可以根据你的 CSP 白名单来验证源。 * 作为最后的努力,如果配置良好,CSP 可以阻止当前正在执行的 XSS 加载自己的恶意资源或使用被泄露的数据调用,从而限制其造成破坏的能力。
*# 子资源的完整性
Subresource Integrity(SRI)是浏览器中的一个安全特性,允许我们验证他们获取的资源是否交付,没有任何意外的操作或妥协。 这种操纵可能发生在资产服务的地方(例如,您的 CDN 被黑客攻击)或网络传输期间(例如,中间人攻击)。
要验证脚本,必须提供一个完整性属性,该属性包含哈希算法的名称(例如sha256、sha384或sha512),然后是哈希本身。 这里有一个例子:
<script src="//cdn.example.com/foo.js" integrity="sha384-367drQif3oVsd8RI/DR8RsFbY1fJei9PN6tBnqnVMpUFw626Dlb86YfAPCk2O8ce"></script>要生成该哈希,可以使用 OpenSSL 的 CLI,如下所示:
cat FILENAME.js | openssl dgst -sha384 -binary | openssl base64 -A除了在<script>上使用完整性属性,你还可以在<link>上使用它来验证 CSS 样式表。 要强制执行 SRI,可以使用有用的 CSP 头文件:
Content-Security-Policy: require-sri-for script; require-sri-for style;这样做将确保没有完整性散列的任何脚本或样式表将无法加载。 一旦获取,如果提供的完整性散列与接收文件的散列不匹配,那么它将被忽略(就像它没有被获取一样)。 将 SRI 与 CSP 结合使用可以有效地防御 XSS。
跨站请求伪造(CSRF)是指用户在没有意图的情况下,通过恶意代码发送命令,通常以 HTTP GET 或 POST 请求的形式发送。 一个简单的例子是,如果一个位于bank.example.com的银行网站有一个 API 端点,允许登录的用户将给定的金额转移到指定的账户号码。 端点可能如下所示:
POST bank.example.com/transfer?amount=5000&account=12345678即使用户通过bank.example.com域的会话 cookie 进行身份验证,恶意网站也可以很容易地嵌入并提交<form>,将转账转移到自己的账户上,如下所示:
<form
method="post"
action="//bank.example.com/transfer?amount=5000&account=12345678">
</form>
<script>
document.forms[0].submit();
</script>不管端点使用什么 HTTP 方法,或者它接受什么类型的请求体或参数,它都容易受到 CSRF 攻击,除非它确保请求来自它自己的网站。 浏览器固有的同源策略部分解决了这个问题,该策略阻止某些类型的请求发生(例如通过 XHR 或 PUT/DELETE 请求的 JSON POST 请求), 但浏览器本身并不能阻止用户无意中点击某个网站的链接或提交伪造恶意 POST 请求的表单。 毕竟,这些操作是浏览器的全部目的。
由于 web 没有内在的机制来阻止 CSRF,开发人员只好提出自己的防御措施。 防止 CSRF 的一种常见机制是使用 CSRF 令牌(实际上应该称为Anti-CSRF 令牌)。 这是一个生成的密钥(随机、长且无法猜测),随着每个常规请求发送到客户端,同时也作为用户会话数据的一部分存储在服务器上。 然后,服务器将要求浏览器将该密钥连同任何后续 HTTP 请求一起发送,以验证每个请求的源。 因此,我们的/transfer端点现在将不再只有两个参数,而是有第三个参数,token:
POST bank.example.com/transfer?
amount=5000&
account=12345678&
token=d55lv90s88x9mk...然后,服务器可以验证所提供的令牌是否存在于该用户的会话数据中。 有许多库和框架可以简化这一过程。 对于这个基本令牌机制,还有各种适配和配置。 其中一些只会为给定的时间或给定的请求周期生成一个令牌,而另一些则会为该用户的整个会话提供一个单一令牌。 还可以通过多种方式将令牌下游发送到客户端。 最常见的是在响应负载中作为文档标记的一部分,通常以<head>中的<meta>元素的形式出现:
<head>
<!-- ... -->
<meta name="anti-csrf-token" content="JWhpLxPSQSoTLDXm..." />
</head>这可以被 JavaScript 捕获,并与 JavaScript 动态发出的任何后续 GET 或 POST 请求一起发送。 或者在没有客户端呈现的传统网站的情况下,CSRF 令牌可以直接嵌入到<form>标记中作为隐藏的<input>发送到下游,这自然形成了表单最终提交给服务器的一部分:
<form>
<input
type="hidden"
name="anti-csrf-token"
value="JWhpLxPSQSoTLDXm..." />
<!-- Regular input fields here -->
<input type="submit" value="Submit" />
</form>If your web application is susceptible to XSS, then it is also inherently susceptible to CSRF, as the attacker will usually have access to the CSRF token and hence be able to masquerade any requests they make as legitimate, and the server won't be able to tell the difference. So, strong anti-CSRF measures are not sufficient on their own: you must have countermeasures for other potential vulnerabilities as well.
无论您使用何种反 csrf 措施,关键的需求都是对每一个更改用户数据或执行命令的请求进行验证,这些请求来自 web 应用本身的合法页面,而不是恶意生成的外部源。 更透彻地了解 CSRF 和可用的对策,我建议阅读和完全消化OWASP CSRF 预防备忘单:https://cheatsheetseries.owasp.org/cheatsheets/Cross-Site_Request_Forgery_Prevention_Cheat_Sheet.html【5】。
*# 其他安全漏洞
XSS 和 CSRF 只是触及了我们应该准备的攻击类型的表面。 防范所有可能的漏洞是非常具有挑战性的,而且通常是不现实的,但是如果我们不编写能够抵御最常见漏洞的代码,那就太愚蠢了。 对存在的漏洞类型有一个良好的总体理解可以帮助我们在编写代码时更加谨慎。
正如我们所探讨的,XSS 是一个非常多样化的漏洞,有许多可能的攻击向量。 但是我们可以通过一致和正确地识别可信和不可信的数据,以一般的方式来防御它。 我们可以限制不可信数据造成严重破坏的可能性,方法是只将其放置在非常特定的位置,正确地转义它,并确保我们有一个适当限制的 CSP。 同样地,对于 CSRF,攻击者有无数的方法来执行它,但是有一个可靠的 Anti-CSRF 令牌机制将使您免于大多数方法。 考虑到我们有限的资源,在安全领域我们所能希望的是,我们能够防范大多数流行的攻击。
以下是一些值得注意的常见漏洞的概要:
- SQL 或 NoSQL 注入:任何通过 SQL 或 NoSQL 查询表达的用户提交的数据,如果没有正确转义,都可以为攻击者提供对数据的访问和读取、变异或破坏的能力。 它与 XSS 类似,因为它们都是注入攻击的形式,因此我们对它的防御,再次归结为识别不可信的数据,然后正确地转义它。
- 认证/密码攻击:攻击者可以通过猜测用户的密码、暴力破解组合或使用彩虹表(一个常用密码哈希的数据库)来获得对用户帐户的未经授权访问。 通常,建议不要创建您自己的身份验证机制,而是依赖可信的库和框架。 您应该始终确保使用安全的散列算法(如bcrypt)。 一个很好的资源是 OWASP 的密码存储备忘单(https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html)。
- :攻击者可以通过劫持你的一个依赖来访问你的服务器端或前端代码库。 它们可以访问存在于依赖关系图中的 npm 包(在线搜索左键事件),或者破坏用于存储 JavaScript 资产的 CMS 或 CDN。 来抵消这些类型的漏洞,确保您使用一个安全的包管理系统如纱,尝试使用固定在你的
package.json版本模式,总是检查更新日志,前端,有一个适当的限制性 CSP 阻止任何恶意代码调用。
攻击的可能性总是存在的,所以我们需要将这种风险纳入我们的系统设计中。 我们不能指望对这些漏洞免疫,但当它们确实发生时,我们可以确保能够快速修复它们,与受影响的用户透明地沟通,并确保仔细考虑如何防止此类漏洞再次发生。
无论我们是为开发人员创建一个框架,还是为非技术用户创建一个 UI,我们代码的消费者总是希望它的行为安全。 这种期望越来越被编码成为法律(例如,在欧盟法律,一般数据保护监管(GDPR)),所以它是重要的认真对待它,花大量的时间在学习和预防。 安全实践是另一个例子,说明干净的代码不仅关系到我们的语法和设计模式,而且关系到我们的代码对用户及其日常生活的重大影响。
在本章中,我们探讨了各种现实世界中的挑战——任何 JavaScript 程序员都可能在浏览器和服务器上遇到这些问题。 用 JavaScript 编写干净的代码不仅关乎语言本身,还关乎它所处的网络生态系统以及它所带来的需求。 通过我们探索的 DOM,路由、依赖管理,和安全,我们希望得到一个洞察问题的技术领域,JavaScript 通常处理,和许多框架的升值,库和 standards-driven 存在的 api 来帮助我们处理这些问题。
在下一章中,我们将深入探讨编写简洁测试的艺术,这是一项极其重要的任务,不仅因为它让我们对自己的代码充满信心,还因为它确保了用户对我们的软件所期望的那种可靠性。*****