- Java8 简明教程
- Java8 并发编程
- Java8 反应式编程
 PDF电子书集合
PDF电子书集合
Java8 用并行流处理海量数据集详解
在第 7 章中,我们引入了流的概念,即 Java 8 的新特性。流是可以并行或顺序处理的元素序列。在本章中,您将学习如何使用具有以下主题的流:
在第 7 章中处理具有并行流的海量数据集–Map and Reduce 模型中,我们对流进行了介绍。让我们记住他们最重要的特点:
- 流的元素不存储在内存中
- 流不能被重用
- 流对数据进行延迟处理
- 流操作无法修改流源
- 流允许您链接操作,因此一个操作的输出就是下一个操作的输入
流由以下三个主要元素组成:
- 生成流元素的源
- 零个或多个中间操作生成另一个流的输出
- 一个终端操作,生成结果,结果可以是简单的对象、数组、集合、映射或其他任何内容
StreamAPI 提供了不同的终端操作,但由于灵活性和功能,还有两个更重要的操作。在第 7 章中,您学习了如何使用reduce()方法,在本章中,您将学习如何使用collect()方法。让我们来介绍一下这种方法。
collect()方法
collect()方法允许您对流的元素进行转换和分组,生成一个新的数据结构和流的最终结果。您最多可以使用三种不同的数据类型:输入数据类型、来自流的输入元素的数据类型、用于在collect()方法运行时存储元素的中间数据类型,以及collect()方法返回的输出数据类型。
collect()方法有两种不同的版本。第一个版本接受以下三个功能参数:
- 供应商:创建中间数据类型对象的函数。如果使用顺序流,此方法将被调用一次。如果使用并行流,此方法可能会被多次调用,并且每次都必须生成一个新对象。
- 累加器:调用此函数处理输入元素并将其存储在中间数据结构中。
- 合并器:调用此函数将两个中间数据结构合并为一个。此函数将仅使用并行流调用。
此版本的collect()方法使用两种不同的数据类型:来自流的元素的输入数据类型和用于存储中间元素并返回最终结果的中间数据类型。
collect()方法的第二个版本接受一个实现Collector接口的对象。您可以自己实现这个接口,但是使用Collector.of()静态方法更容易。此方法的参数如下所示:
- 供应商:此功能创建一个中间数据类型的对象,如前所示
- 累加器:调用此函数处理输入元素,必要时进行转换,并存储在中间数据结构中
- 合并器:调用此函数将两个中间数据结构合并为一个,其工作原理如前所述
- Finisher:如果需要进行最终转换或计算,调用此函数将中间数据结构转换为最终数据结构
- 特征:您可以使用最后一个变量参数来指示正在创建的收集器的某些特征
实际上,这两个版本之间有点不同。三个参数 collect 接受一个组合器,即BiConsumer,它必须将第二个中间结果合并到第一个中间结果中。与之不同的是,此合并器是BinaryOperator,应该返回合并器。因此,它可以自由地将第二个合并到第一个或第一个合并到第二个,或者创建新的中间结果。还有另一个版本的of()方法,除了 finisher 之外,它接受相同的参数;在这种情况下,不执行精加工转换。
Java 在Collectors工厂类中为您提供了一些预定义的收集器。您可以使用其静态方法之一获取这些收集器。其中一些方法是:
-
averagingDouble()、averagingInt()和averagingLong():返回一个收集器,允许您计算double、int或long函数的算术平均值。 -
groupingBy():返回一个收集器,允许您根据流对象的属性对流元素进行分组,生成一个映射,其中键是所选属性的值,值是具有确定值的对象列表。 -
groupingByConcurrent():除两个重要区别外,与上一个类似。第一种方法是,与groupingBy()方法相比,它在并行模式下的工作速度更快,但在顺序模式下的工作速度较慢。第二个也是最重要的区别是,groupingByConcurrent()函数是一个无序收集器。列表中的项目不保证与流中的项目顺序相同。另一方面,groupingBy()收集器保证订购。 -
joining():返回一个Collector工厂类,将输入元素连接成字符串。 -
partitioningBy():返回一个Collector工厂类,该工厂类根据谓词的结果对输入元素进行分区。 -
summarizingDouble()、summarizingInt()和summarizingLong():它们返回一个Collector工厂类,用于计算输入元素的汇总统计信息。 -
toMap():返回一个Collector工厂类,允许您基于两个映射函数将输入元素转换为映射。 -
toConcurrentMap():与前一个类似,但同时进行。如果没有自定义合并,toConcurrentMap()对于并行流来说速度更快。与groupingByConcurrent()一样,这也是一个无序收集器,而toMap()使用遭遇顺序进行转换。 -
toList():返回一个Collector工厂类,将输入元素存储到列表中。 -
toCollection():此方法允许您按遭遇顺序将输入元素累积到新的Collection工厂类(TreeSet、LinkedHashSet等)中。该方法接收创建集合作为参数的Supplier接口的实现。 -
maxBy()和minBy():返回一个Collector工厂类,根据作为参数传递的比较器生成最大和最小元素。 -
toSet():返回将输入元素存储到集合中的Collector。
在第 7 章中,您学习了如何实现一个搜索工具,使用反向索引查找类似于输入查询的文档,该工具使用并行流处理海量数据集–Map and Reduce 模型。这种数据结构使搜索操作更容易、更快,但在某些情况下,您必须对一大组数据执行搜索操作,而不会有反向索引来帮助您。在这些情况下,您必须处理数据集的所有元素以获得正确的结果。在本例中,您将看到其中一种情况以及StreamAPI 的reduce()方法如何帮助您。
为了实现此示例,您将使用亚马逊产品共同购买网络元数据的子集,其中包含关于亚马逊销售的 548552 种产品的信息,其中包括标题、salesrank 以及类似产品、类别和评论的列表。您可以从下载此数据集 https://snap.stanford.edu/data/amazon-meta.html 。我们已获取了前 20000 个产品,并将每个产品记录存储在单独的文件中。我们已经更改了一些字段的格式,以简化数据处理。所有字段均为property:value格式。
基本类
我们有一些在并发版本和串行版本之间共享的类。让我们看看每一个的细节。
产品类别
Product类存储有关产品的信息。以下是Product类:
-
id:这是产品的唯一标识符。 -
asin:这是亚马逊的标准识别号。 -
title:这是产品的名称。 -
group:这是产品的分组。该属性可以取值为Baby Product、Book、CD、DVD、Music、Software、Sports、Toy、Video或Video Games。 -
salesrank:表示亚马逊的 salesrank。 -
similar:这是文件中包含的类似项目的数量。 -
categories:这是一个String对象列表,其类别分配给产品。 -
reviews:这是一个Review对象的列表,其中包含分配给产品的评论(用户和价值)。
此类仅包含属性的定义以及相应的getXXX()和setXXX()方法,因此不包含其源代码。
复习课
正如我们前面提到的,Product类包括一个Review对象列表,其中包含用户对产品的评论信息。此类将每个审阅的信息存储在以下两个属性中:
-
user:审核用户的内部代码 -
value:用户对产品的评分
此类仅包含属性的定义以及相应的getXXX()和setXXX()方法,因此不包含其源代码。
ProductLoader 类
ProductLoader类允许您将产品信息从文件加载到Product对象。它实现了一个load()方法,该方法接收一个Path对象,该对象的路径指向包含产品信息的文件,并返回一个Product对象。这是它的源代码:
public class ProductLoader {
public static Product load(Path path) {
try (BufferedReader reader = Files.newBufferedReader(path)) {
Product product=new Product();
String line=reader.readLine();
product.setId(line.split(":")[1]);
line=reader.readLine();
product.setAsin(line.split(":")[1]);
line=reader.readLine();
product.setTitle(line.substring (line.indexOf(':')+1));
line=reader.readLine();
product.setGroup(line.split(":")[1]);
line=reader.readLine();
product.setSalesrank(Long.parseLong (line.split(":")[1]));
line=reader.readLine();
product.setSimilar(line.split(":")[1]);
line=reader.readLine();
int numItems=Integer.parseInt(line.split(":")[1]);
for (int i=0; i<numItems; i++) {
line=reader.readLine();
product.addCategory(line.split(":")[1]);
}
line=reader.readLine();
numItems=Integer.parseInt(line.split(":")[1]);
for (int i=0; i<numItems; i++) {
line=reader.readLine();
String tokens[]=line.split(":");
Review review=new Review();
review.setUser(tokens[1]);
review.setValue(Short.parseShort(tokens[2]));
product.addReview(review);
}
return product;
} catch (IOException x) {
throw newe UncheckedIOException(x);
}
}
}第一种方法——基本搜索
第一种方法接收一个单词作为输入查询,并搜索存储产品信息的所有文件,无论该单词是否包含在定义产品的某个字段中,无论是哪个字段。它将只显示包含单词的文件名。
为了实现这个基本方法,我们已经实现了实现main() 方法的ConcurrentMainBasicSearch类。首先,我们初始化查询和存储所有文件的基本路径:
public class ConcurrentMainBasicSearch {
public static void main(String args[]) {
String query = args[0];
Path file = Paths.get("data");我们只需要一个流来生成字符串列表,结果如下:
try {
Date start, end;
start = new Date();
ConcurrentLinkedDeque<String> results = Files
.walk(file, FileVisitOption.FOLLOW_LINKS)
.parallel()
.filter(f -> f.toString().endsWith(".txt"))
.collect(ArrayList<String>::new,
new ConcurrentStringAccumulator (query),
List::addAll);
end = new Date();我们的流包含以下元素:
- 我们使用
Files类的walk()方法启动流,该方法将文件集合的基Path对象作为参数传递。此方法将以流的形式返回所有文件以及存储在该路由下的目录。 - 然后,我们使用
parallel()方法将流转换为并发流。 - 我们只对以
.txt扩展名结尾的文件感兴趣,所以我们使用filter()方法过滤它们。 - 最后,我们使用
collect()方法将Path对象的流转换为具有文件名的String对象的ConcurrentLinkedDeque流。
我们使用三参数版本的collect()方法,使用以下功能参数:
-
供应商:我们使用
ArrayList类的new方法引用为每个线程创建一个新的数据结构来存储相应的结果。 -
累加器:我们在
ConcurrentStringAccumulator类中实现了自己的累加器。我们将在后面描述这个类的细节。 -
合并器:我们使用
ConcurrentLinkedDeque类的addAll()方法连接两个数据结构。在这种情况下,第二个集合中的所有元素都将添加到第一个集合中。第一个集合将用于进一步合并或作为最终结果。
最后,我们将流得到的结果写入控制台:
System.out.println("Results for Query: "+query);
System.out.println("*************");
results.forEach(System.out::println);
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
} catch (IOException e) {
e.printStackTrace();
}
}
}每当我们想要处理流的路径以评估是否必须将其名称包括在结果列表中时,将执行累加器函数参数。为了实现这个功能,我们已经实现了ConcurrentStringAccumulator类。让我们看看这个类的详细信息。
ConcurrentStringAccumulator 类
ConcurrentStringAccumulator类加载包含产品信息的文件,以确定其是否包含查询项。它实现了BiConsumer接口,因为我们想将其用作collect() 方法的参数。我们已经用List<String>和Path类参数化了该接口:
public class ConcurrentStringAccumulator implements BiConsumer<List<String>, Path> {它将查询定义为在构造函数中初始化的内部属性,如下所示:
private String word;
public ConcurrentStringAccumulator (String word) {
this.word=word.toLowerCase();
}在BiConsumer中,我们定义了accept()接口。此方法接收两个参数:一个ConcurrentLinkedDeque<String>类和一个Path类。
要加载文件并确定其是否包含查询,我们使用以下流:
@Override
public void accept(List<String> list, Path path) {
boolean result;
try (Stream<String> lines = Files.lines(path)) {
result = lines
.parallel()
.map(l -> l.split(":")[1].toLowerCase())
.anyMatch(l -> l.contains(word))我们的流包含以下元素:
- 我们使用
Files类的lines()方法在一个 try with resources 语句中创建String对象流。此方法接收指向文件的Path对象作为参数,并返回包含文件所有行的流。 - 然后,我们使用
parallel()方法将流转换为并发流。 - 然后,我们使用
map()方法获得每个属性的值。正如我们在本节介绍中提到的,每一行都有property:value格式。 - 最后,我们使用
anyMatch()方法来了解是否有任何属性的值包含查询项。
如果计数器变量的值大于0,则该文件包含查询项,我们将该文件的名称包含在ConcurrentLinkedDeque类中,结果如下:
if (counter>0) {
list.add(path.toString());
}
} catch (Exception e) {
System.out.println(path);
e.printStackTrace();
}
}
}第二种方法——高级搜索
我们的基本搜索有一些缺点:
- 我们在所有属性中查找查询词,但可能我们只想在其中一些属性中查找,例如在标题中
- 我们只显示文件的名称,但如果我们将附加信息显示为产品的标题,则会提供更多信息
为了解决这些问题,我们将实现实现main()方法的ConcurrentMainSearch类。首先,我们初始化查询和存储所有文件的基本Path对象:
public class ConcurrentMainSearch {
public static void main(String args[]) {
String query = args[0];
Path file = Paths.get("data");然后,我们使用以下流生成一个ConcurrentLinkedDeque类的Product对象:
try {
Date start, end;
start=new Date();
ConcurrentLinkedDeque<Product> results = Files
.walk(file, FileVisitOption.FOLLOW_LINKS)
.parallel()
.filter(f -> f.toString().endsWith(".txt"))
.collect(ArrayList<Product>::new,
new ConcurrentObjectAccumulator (query),
List::addAll);
end=new Date();此流与我们在基本方法中实现的流具有相同的元素,但有以下两个更改:
- 在
collect()方法中,我们在累加器参数中使用ConcurrentObjectAccumulator类 - 我们将
ConcurrentLinkedDeque类参数化为Product类
最后,我们在控制台中写入结果,但在本例中,我们写入每个产品的标题:
System.out.println("Results");
System.out.println("*************");
results.forEach(p -> System.out.println(p.getTitle()));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
} catch (IOException e) {
e.printStackTrace();
}
}
}您可以更改此代码以编写有关产品的任何信息,如 salesrank 或类别。
此实现与前一个实现之间最重要的更改是ConcurrentObjectAccumulator类。让我们看看这个类的详细信息。
ConcurrentObjectAccumulator 类
ConcurrentObjectAccumulator类通过ConcurrentLinkedDeque<Product>和Path类实现BiConsumer接口参数化,因为我们想在collect() 方法中使用它。它定义了一个名为word的内部属性来存储查询项。此属性在类的构造函数中初始化:
public class ConcurrentObjectAccumulator implements
BiConsumer<List<Product>, Path> {
private String word;
public ConcurrentObjectAccumulator(String word) {
this.word = word;
}accept()方法(在BiConsumer接口中定义)的实现非常简单:
@Override
public void accept(List<Product> list, Path path) {
Product product=ProductLoader.load(path);
if (product.getTitle().toLowerCase().contains (word.toLowerCase())) {
list.add(product);
}
}
}该方法接收指向我们将要处理的文件作为参数的Path对象和存储结果的ConcurrentLinkedDeque类。我们使用ProductLoader类将文件加载到Product对象中,然后检查产品的标题是否包含查询词。如果它包含查询,我们将Product对象添加到ConcurrentLinkedDeque类中。
示例的串行实现
与本书中的其他示例一样,我们已经实现了两个版本的搜索操作的串行版本,以验证并发流允许我们获得性能的改进。
通过删除Stream对象中的parallel()调用,使流并发,可以实现前面描述的四个类的串行等效。
在这本书的源代码中,我们已经包含了SerialMainBasicSearch、SerialMainSearch、SerialStringAccumulator和SerialObjectAccumulator类,这些类都是与前面注释的更改相对应的串行类。
比较实现
我们已经测试了我们的实现(两种方法:串行和并发版本),以比较它们的执行时间。为了测试它们,我们使用了三种不同的查询:
- 模式
- JAVA
- 树
对于每个查询,我们都对串行流和并行流执行了两个搜索操作(basic 和 object)。我们已经使用 JMH 框架(来执行它们 http://openjdk.java.net/projects/code-tools/jmh/ ),允许您在 Java 中实现微基准测试。使用nanoTime()或currentTimeMillis()等方法进行基准测试是更好的方法。我们已经在一台四核处理器的计算机上执行了 10 次,并计算了这 10 次的中间执行时间。以下是以毫秒为单位的结果:
字符串搜索
|
对象搜索
| | --- | --- | --- | | | Java | 图案 | 树 | Java | 图案 | 树 | | 序列号 | 4318.551 | 4372.565 | 4364.674 | 4573.985 | 4588.957 | 4591.100 | | 并发 | 32402.969 | 2428.729 | 2412.747 | 2190.053 | 2173.511 | 2173.936 |
我们可以得出以下结论:
- 使用不同查询得到的结果非常相似
- 对于串行流,字符串搜索的执行时间优于对象搜索的执行时间
- 对于并发流,对象搜索的执行时间优于字符串搜索的执行时间
- 在所有情况下,并发流都比串行流具有更好的性能
例如,如果我们将对象搜索的并发版本和串行版本与使用加速的查询模式进行比较,我们会得到以下结果:
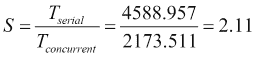
推荐系统根据客户购买/使用的产品/服务以及购买/使用相同服务的用户购买/使用的产品/服务,向客户推荐产品或服务。
我们使用了上一节中介绍的示例来实现推荐系统。产品的每个描述都包括对一个产品的多个客户的评论。该评审包括客户对产品的评分。
在本例中,您将使用这些评论来获得客户可能感兴趣的产品列表。我们将获得客户购买的产品清单。为了获得该列表,使用评论中给出的平均分数对购买这些产品的用户列表和这些用户购买的产品列表进行排序。这将是为用户推荐的产品。
普通班
我们在上一节中使用的类的基础上增加了两个新类。这些课程包括:
-
ProductReview:此类使用两个新属性扩展了 product 类 -
ProductRecommendation:此类存储产品推荐信息
让我们看看这两个类的详细信息。
ProductReview 类
ProductReview类扩展了Product类,添加了两个新属性:
-
buyer:此属性存储产品的客户名称 -
value:此属性存储该客户在其评论中给予该产品的值
该类包括属性的定义:对应的getXXX()和setXXX()方法,从Product对象创建ProductReview对象的构造函数,以及新属性的值。它非常简单,因此不包含其源代码。
产品推荐类
ProductRecommendation类存储产品推荐的必要信息,包括以下内容:
-
title:我们推荐的产品名称 -
value:该推荐的得分,计算为该产品所有评审的平均得分
该类包括属性的定义、相应的getXXX()和setXXX()方法,以及compareTo()方法的实现(该类实现Comparable接口),这将允许我们按其值降序排列建议。它的非常简单,所以不包括它的源代码。
推荐系统——主类
我们已经在ConcurrentMainRecommendation类中实现了我们的算法,以获得向客户推荐的产品列表。此类实现了main()方法,该方法接收我们希望获得其推荐产品的客户的 ID 作为参数。我们有以下代码:
public static void main(String[] args) {
String user = args[0];
Path file = Paths.get("data");
try {
Date start, end;
start=new Date();在最终的解决方案中,我们使用了不同的流来转换数据。第一个从其文件加载整个Product对象列表:
List<Product> productList = Files
.walk(file, FileVisitOption.FOLLOW_LINKS)
.parallel()
.filter(f -> f.toString().endsWith(".txt"))
.collect(ConcurrentLinkedDeque<Product>::new
,new ConcurrentLoaderAccumulator(), ConcurrentLinkedDeque::addAll);此流具有以下元素:
- 我们使用
Files类的walk()方法启动流。此方法将创建一个流来处理数据目录下的所有文件和目录。 - 然后,我们使用
parallel()方法将流转换为并发流。 - 然后,我们只获取扩展名为
.txt的文件。 - 最后,我们使用
collect()方法获得Product对象的ConcurrentLinkedDeque类。它与上一节中使用的非常相似,不同之处在于我们使用了另一个累加器对象。在本例中,我们使用稍后将描述的ConcurrentLoaderAccumulator类。
一旦我们有了产品列表,我们将使用客户的标识符作为该地图的键,在地图中组织这些产品。我们使用ProductReview类存储产品客户的信息。我们将创建尽可能多的ProductReview对象,因为评论有Product。我们使用以下流进行转换:
Map<String, List<ProductReview>> productsByBuyer=productList
.parallelStream()
.<ProductReview>flatMap(p -> p.getReviews().stream().map(r -> new ProductReview(p, r.getUser(), r.getValue())))
.collect(Collectors.groupingByConcurrent( p -> p.getBuyer()));此流具有以下元素:
- 我们使用
productList对象的parallelStream()方法启动流,所以我们创建了一个并发流。 - 然后,我们使用
flatMap()方法将我们拥有的Product对象流转换为唯一的ProductReview对象流。 - 最后,我们使用
collect()方法生成最终地图。在本例中,我们使用了由Collectors类的groupingByConcurrent()方法生成的预定义收集器。返回的收集器将生成一个映射,其中键将是买家属性的不同值和带有该用户购买的产品信息的ProductReview对象列表的值。如方法名称所示,此转换将以并发方式完成。
下一个流是本例中最重要的流。我们接受客户购买的产品,并向该客户提出建议。这是一个由一个流组成的两阶段过程。在第一阶段,我们获取购买原始客户购买的产品的用户。在第二阶段,我们将生成一个地图,其中包含这些客户购买的产品以及这些客户对产品的所有评论。这是该流的代码:
Map<String,List<ProductReview>> recommendedProducts=productsByBuyer.get(user)
.parallelStream()
.map(p -> p.getReviews())
.flatMap(Collection::stream)
.map(r -> r.getUser())
.distinct()
.map(productsByBuyer::get)
.flatMap(Collection::stream)
.collect(Collectors.groupingByConcurrent(p -> p.getTitle()));我们在该流程中有以下要素:
- 首先,我们获取用户购买的产品列表,并使用
parallelStream()方法生成一个并发流。 - 然后,我们使用
map()方法获得该产品的所有评论。 - 此时此刻,我们有一个
List<Review>流。我们将该流转换为Review对象流。现在我们有了一个用户购买的产品的所有评论流。 - 然后,我们将该流转换为一个
String对象流,其中包含进行评论的用户的名称。 - 然后,我们使用
distinct()方法获得用户的唯一名称。现在我们有了一个String对象流,其中包含购买与原始用户相同产品的用户的名称。 - 然后,我们使用
map()方法将每个客户转换为其购买的产品列表。 - 在这个时刻,我们有一个
List<ProductReview>对象流。我们使用flatMap()方法将该流转换为ProductReview对象流。 - 最后,我们使用
collect()方法和groupingByConcurrent()收集器生成产品地图。地图的关键是产品名称和ProductReview对象列表的值,以及之前获得的客户评论。
要完成我们的推荐算法,我们需要最后一步。对于每种产品,我们希望计算其在评论中的平均分数,并按降序对列表进行排序,以便首先显示排名靠前的产品。为了进行转换,我们使用了一个额外的流:
List<ProductRecommendation> recommendations = recommendedProducts
.entrySet()
.parallelStream()
.map(entry -> new
ProductRecommendation(
entry.getKey(),
entry.getValue().stream().mapToInt(p -> p.getValue()).average().getAsDouble()))
.sorted()
.collect(Collectors.toList());
end=new Date();
recommendations. forEach(pr -> System.out.println (pr.getTitle()+": "+pr.getValue()));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
} catch (IOException e) {
e.printStackTrace();
}
}
}我们处理在上一步中获得的映射。对于每个产品,我们处理其评审列表,生成一个ProductRecommendation对象。此对象的值计算为每次审查的平均值,使用流使用mapToInt()方法将ProductReview对象流转换为整数流,并使用average()方法获得字符串中所有数字的平均值。
最后,在推荐ConcurrentLinkedDeque类中,我们有一个ProductRecommendation对象列表。我们使用另一个流和sorted()方法对该列表进行排序。我们使用该流在控制台中写入最终列表。
ConcurrentLoaderAccumulator 类
为了实现这个示例,我们在collect()方法中使用了ConcurrentLoaderAccumulator类作为累加器函数,该方法将Path对象流以及所有要处理的文件的路由转换为Product对象的ConcurrentLinkedDeque类。这是此类的源代码:
public class ConcurrentLoaderAccumulator implements
BiConsumer<ConcurrentLinkedDeque<Product>, Path> {
@Override
public void accept(ConcurrentLinkedDeque<Product> list, Path path) {
Product product=ProductLoader.load(path);
list.add(product);
}
}实现BiConsumer接口。accept()方法使用ProducLoader类(在本章前面解释)从文件中加载产品信息,并将结果Product对象添加到ConcurrentLinkedDeque类中作为参数接收。
序列版本
与本书中的其他示例一样,我们实现了该示例的串行版本,以检查并行流是否提高了应用的性能。要实现此串行版本,我们必须遵循以下步骤:
- 将
ConcurrentLinkedDeque数据结构替换为List或ArrayList数据结构 - 将
parallelStrem()方法改为stream()方法 - 将
gropingByConcurrent()方法改为groupingBy()方法
您可以在本书的源代码中看到该示例的串行版本。
比较两个版本
为了比较我们推荐系统的串行版本和并发版本,我们获得了针对三个用户的推荐产品:
A2JOYUS36FLG4ZA2JW67OY8U6HHKA2VE83MZF98ITY
对于这三个用户,我们使用 JMH 框架(执行了两个版本 http://openjdk.java.net/projects/code-tools/jmh/ ),允许您在 Java 中实现微基准测试。使用nanoTime()或currentTimeMillis()等方法进行基准测试是更好的方法。我们已经在一台四核处理器的计算机上执行了 10 次,并计算了这 10 次的中间执行时间。以下是以毫秒为单位的结果:
A2US36FLG4Z
|
A2JW67OY8U6HHK
|
A2VE83MZF98Y
| | --- | --- | --- | --- | | 序列号 | 4848.672 | 4830.051 | 4817.216 | | 并发 | 2454.003 | 2458.003 | 2527.194 |
我们可以得出以下结论:
- 三个用户的结果非常相似
- 并发流的执行时间总是优于顺序流的执行时间
如果我们比较并发版本和串行版本,例如,第二个用户使用加速,我们会得到以下结果:

社交网络正在改变我们的社会和人们之间的关系方式。Fackebook、Linkedin、Twitter 或 Instagram 拥有数百万用户,他们使用这些网络与朋友分享生活时刻,建立新的专业联系人,推广自己的专业品牌,结识新朋友,或者仅仅了解世界最新趋势。
我们可以将社交网络视为一个图,其中用户是该图的节点,用户之间的关系是该图的弧。正如图表所示,有一些社交网络,如 Facebook,用户之间的关系是无向的或双向的。如果用户A与用户B连接,则用户B也与A连接。相反,有一些社交网络,如 Twitter,用户之间的关系是直接的。在这种情况下,我们说用户A跟随用户B,但事实并非如此。
在本节中,我们将实现一种算法,用于计算用户之间具有双向关系的社交网络中每对用户的公共联系人。我们将实现中描述的算法 http://stevekrenzel.com/finding-friends-with-mapreduce 。该算法的主要步骤如下。
我们的数据源将是一个文件,其中存储每个用户及其联系人:
A-B,C,D,
B-A,C,D,E,
C-A,B,D,E,
D-A,B,C,E,
E-B,C,D,这意味着用户A将用户B、C和D作为联系人。考虑到这些关系是双向的,所以如果B是a的联系人,a也将是B的联系人,这两种关系都必须在文件中表示。因此,我们有以下两个部分的元素:
- 用户标识符
- 该用户的联系人列表
在下一步中,我们将生成一组元素,每个元素包含三个部分。这三个部分是:
- 用户标识符
- 朋友的用户标识符
- 该用户的联系人列表
因此,对于用户A,我们将生成以下元素:
A-B-B,C,D
A-C-B,C,D
A-D-B,C,D我们对所有元素都遵循相同的过程。我们将按字母顺序存储这两个用户标识符。因此,对于用户B,我们生成以下元素:
A-B-A,C,D,E
B-C-A,C,D,E
B-D-A,C,D,E
B-E-A,C,D,E一旦我们生成了所有新元素,我们就为两个用户标识符对它们进行分组。例如,对于元组A-B,我们将生成以下组:
A-B-(B,C,D),(A,C,D,E)最后,我们计算两个列表之间的交集。结果列表是两个用户之间的常见联系人。例如,用户A和B有共同的联系人C和D。
为了测试我们的算法,我们使用了两个数据集:
- 前面介绍的测试样本。
- 社交圈:可从下载的 Facebook 数据集 https://snap.stanford.edu/data/egonets-Facebook.html 包含来自 Facebook 的 4039 名用户的联系信息。我们已经将原始数据转换为示例中使用的数据格式。
基类
与本书中的其他示例一样,我们已经实现了该示例的串行和并发版本,以验证并行流提高了应用的性能。两个版本共享一些类。
人物类
Person类存储社交网络中每个人的信息,包括以下内容:
- 它是用户 ID,存储在 ID 属性中
- 该用户的联系人列表,存储为联系人属性中的
String对象列表
该类声明了这两个属性以及相应的getXXX()和setXXX()方法。我们还需要一个构造函数来创建该列表,并需要一个名为addContact()的方法将单个联系人添加到联系人列表中。这个类的源代码非常简单,所以这里不包括它。
配对班
PersonPair类扩展Person类,添加属性来存储第二个用户标识符。我们称这个属性为otherId。此类声明属性并实现相应的getXXX()和setXXX()方法。我们需要一个名为getFullId()的附加方法,该方法返回一个字符串,其中两个用户标识符由,字符分隔。这个类的源代码非常简单,所以这里不包括它。
数据加载器类
DataLoader类加载包含用户及其联系人信息的文件,将其转换为Person对象列表。它只实现一个名为load()的静态方法,该方法将文件路径作为String对象作为参数接收,并返回Person对象列表。
如前所述,该文件的格式如下:
User-C1,C2,C3...CN这里,User是用户的标识符,C1, C2, C3….CN是该用户的联系人的标识符。
这个类的源代码非常简单,所以这里不包括它。
并发版本
首先,让我们分析这个算法的并发版本。
普通人形象类
CommonPersonMapper类是辅助类,稍后将使用。它将生成您可以从Person对象生成的所有PersonPair对象。此类实现了用Person类和List<PersonPair>类参数化的Function接口。
实现Function接口中定义的apply()方法。首先,我们初始化要返回的List<PersonPair>对象,获取联系人列表并对其进行排序:
public class CommonPersonMapper implements Function<Person, List<PersonPair>> {
@Override
public List<PersonPair> apply(Person person) {
List<PersonPair> ret=new ArrayList<>();
List<String> contacts=person.getContacts();
Collections.sort(contacts);然后,我们处理整个联系人列表,为每个联系人创建PersonPair对象。如前所述,我们按字母顺序存储这两个联系人。ID 字段中较小的一个和otherId字段中的另一个:
for (String contact : contacts) {
PersonPair personExt=new PersonPair();
if (person.getId().compareTo(contact) < 0) {
personExt.setId(person.getId());
personExt.setOtherId(contact);
} else {
personExt.setId(contact);
personExt.setOtherId(person.getId());
}最后,我们将联系人列表添加到新对象中,并将对象添加到结果列表中。处理完所有联系人后,我们将返回结果列表:
personExt.setContacts(contacts);
ret.add(personExt);
}
return ret;
}
}ConcurrentSocialNetwork 类
ConcurrentSocialNetwork是本例的主类。它只实现了一个名为bidirectionalCommonContacts()的静态方法。此方法接收社交网络中的联系人列表,并返回具有每对联系人之间的公共联系人的PersonPair对象列表。
在内部,我们使用两个不同的流来实现我们的算法。我们使用第一种方法将Person对象的输入列表转换为地图。此地图的键将是每对用户的两个标识符,值将是两个用户的联系人的PersonPair对象列表。因此,这些列表将始终包含两个元素。我们有以下代码:
public class ConcurrentSocialNetwork {
public static List<PersonPair> bidirectionalCommonContacts(
List<Person> people) {
Map<String, List<PersonPair>> group = people.parallelStream()
.map(new CommonPersonMapper())
.flatMap(Collection::stream)
.collect(Collectors.groupingByConcurrent (PersonPair::getFullId));此流包含以下组件:
- 我们使用输入列表的
parallelStream()方法创建流。 - 然后,我们使用前面解释的
map()方法和CommonPersonMapper类来转换PersonPair对象列表中的每个Person对象,以及该对象的所有可能性。 - 此时此刻,我们有一个
List<PersonPair>对象流。我们使用flatMap()方法将该流转换为PersonPair对象流。 - 最后,我们使用
collect()方法生成地图,使用groupingByConcurrent()方法返回的收集器,使用getFullId()方法返回的值作为地图的键。
然后,我们使用Collectors类的of()方法创建一个新收集器。此采集器将接收一个Collection字符串作为输入,使用一个AtomicReference<Collection<String>>作为中间数据结构,并返回一个Collection字符串作为返回类型。
Collector<Collection<String>, AtomicReference<Collection<String>>, Collection<String>> intersecting = Collector.of(
() -> new AtomicReference<>(null), (acc, list) -> {
acc.updateAndGet(set -> set == null ? new ConcurrentLinkedQueue<>(list) : set).retainAll(list);
}, (acc1, acc2) -> {
if (acc1.get() == null)
return acc2;
if (acc2.get() == null)
return acc1;
acc1.get().retainAll(acc2.get());
return acc1;
}, (acc) -> acc.get() == null ? Collections.emptySet() : acc.get(), Collector.Characteristics.CONCURRENT, Collector.Characteristics.UNORDERED);of()方法的第一个参数是供应商函数。当我们需要创建中间数据结构时,总是调用此供应商。在串行流中,此方法只调用一次,但在并发流中,此方法将在每个线程中调用一次。
() -> new AtomicReference<>(null),在我们的例子中,我们只需创建一个新的AtomicReference 来存储Collection<String>对象。
of()方法的第二个参数是累加器功能。此函数接收中间数据结构和输入值作为参数:
(acc, list) -> {
acc.updateAndGet(set -> set == null ? new ConcurrentLinkedQueue<>(list) : set).retainAll(list);
},在我们的例子中,acc参数是AtomicReference,而list参数是ConcurrentLinkedDeque。我们使用AtomicReference中的updateAndGet()方法。此方法更新当前值并返回新值。如果AtomicReference是null,我们将使用列表中的元素创建一个新的ConcurrentLinkedDeque。如果AtomicReference不为空,则存储ConcurrentLinkedDeque。我们使用retainAll()方法添加列表中的所有元素。
of()方法的第三个参数是组合器函数。此函数仅在并行流中调用,它接收两个中间数据结构作为参数,只生成一个。
(acc1, acc2) -> {
if (acc1.get() == null)
return acc2;
if (acc2.get() == null)
return acc1;
acc1.get().retainAll(acc2.get());
return acc1;
},在本例中,如果其中一个参数为 null,则返回另一个参数。否则,我们在acc1参数中使用retainAll()方法并返回结果。
of()方法的第四个参数是 finisher 函数。此函数用于转换要返回的数据结构中的最终中间数据结构。在我们的例子中,中间数据结构和最终数据结构是相同的,因此不需要转换。
(acc) -> acc.get() == null ? Collections.emptySet() : acc.get(),最后,我们使用最后一个参数向收集器指示收集器是并发的,也就是说,可以使用来自多个线程的相同结果容器并发调用累加器函数,并且是无序的,也就是说,此操作不会保留元素的原始顺序。
正如我们现在定义的收集器一样,我们必须将使用第一个流生成的映射转换为具有每对用户的公共联系人的PersonPair对象列表。我们使用以下代码:
List<PersonPair> peopleCommonContacts = group.entrySet()
.parallelStream()
.map((entry) -> {
Collection<String> commonContacts =
entry.getValue()
.parallelStream()
.map(p -> p.getContacts())
.collect(intersecting);
PersonPair person = new PersonPair();
person.setId(entry.getKey().split(",")[0]);
person.setOtherId(entry.getKey().split (",")[1]);
person.setContacts(new ArrayList<String> (commonContacts));
return person;
}).collect(Collectors.toList());
return peopleCommonContacts;
}
}我们使用entySet()方法处理地图的所有元素。我们创建一个parallelStream()方法来处理所有Entry对象,然后使用map()方法将每个PersonPair对象列表转换为一个具有公共联系人的唯一PersonPair对象。
对于每个条目,键是一对用户的标识符,作为分隔符连接,值是两个PersonPair对象的列表。第一个包含一个用户的联系人,另一个包含另一个用户的联系人。
我们为该列表创建一个流,用以下元素生成两个用户的公共联系人:
- 我们使用列表的
parallelStream()方法创建流 - 我们使用
map()方法将每个PersonPair()对象替换为其中存储的联系人列表 - 最后,我们使用收集器生成具有公共联系人的
ConcurrentLinkedDeque
最后,我们创建了一个新的PersonPair对象,其中包含用户标识符和常用联系人列表。我们将该对象添加到结果列表中。处理完地图的所有元素后,我们可以返回结果列表。
ConcurrentMain 类
ConcurrentMain类实现了main()方法来测试我们的算法。正如我们前面提到的一样,我们使用以下两个数据集对其进行了测试:
- 一个非常简单的数据集来测试算法的正确性
- 基于 Facebook 真实数据的数据集
这是此类的源代码:
public class ConcurrentMain {
public static void main(String[] args) {
Date start, end;
System.out.println("Concurrent Main Bidirectional - Test");
List<Person> people=DataLoader.load("data","test.txt");
start=new Date();
List<PersonPair> peopleCommonContacts= ConcurrentSocialNetwork.bidirectionalCommonContacts (people);
end=new Date();
peopleCommonContacts.forEach(p -> System.out.println (p.getFullId()+": "+getContacts(p.getContacts())));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
System.out.println("Concurrent Main Bidirectional - Facebook");
people=DataLoader.load("data","facebook_contacts.txt");
start=new Date();
peopleCommonContacts= ConcurrentSocialNetwork.bidirectionalCommonContacts (people);
end=new Date();
peopleCommonContacts.forEach(p -> System.out.println (p.getFullId()+": "+getContacts(p.getContacts())));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
}
private static String formatContacts(List<String> contacts) {
StringBuffer buffer=new StringBuffer();
for (String contact: contacts) {
buffer.append(contact+",");
}
return buffer.toString();
}
}序列版本
与本书中的其他示例一样,我们已经实现了本示例的系列版本。此版本与同时进行以下更改的版本相同:
- 将
parallelStream()方法替换为stream()方法 - 将
ConcurrentLinkedDeque数据结构替换为ArrayList数据结构 - 将
groupingByConcurrent()方法替换为groupingBy()方法 - 不要在
of()方法中使用最终参数
比较两个版本
我们使用 JMH 框架(使用两个数据集执行了两个版本 http://openjdk.java.net/projects/code-tools/jmh/ ),允许您在 Java 中实现微基准测试。使用基准测试框架是一个更好的解决方案,它可以使用currentTimeMillis()或nanoTime()等方法简单地测量时间。我们已经在一台四核处理器的计算机上执行了 10 次,并计算了这 10 次的中间执行时间。以下是以毫秒为单位的结果:
示例
|
| | --- | --- | --- | | 序列号 | 0.861 | 7002.485 | | 并发 | 1.352 | 5303.990 |
我们可以得出以下结论:
- 对于示例数据集,串行版本获得了更好的执行时间。产生此结果的原因是示例数据集的元素很少。
- 对于 Facebook 数据集,并发版本获得了更好的执行时间。
如果我们比较 Facebook 数据集的并发版本和串行版本,我们会得到以下结果:
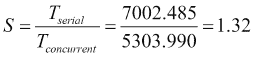
在本章中,我们使用Stream框架提供的collect() 方法的不同版本来转换和分组Stream的元素。本书和第 7 章使用并行流处理海量数据集–地图和简化模型,教您如何使用整个流 API。
基本上,collect()方法需要一个收集器来处理流的数据,并生成由形成流的一组聚合操作返回的数据结构。收集器使用三种不同的数据结构—输入元素类、处理输入元素时使用的中间数据结构和返回的最终数据结构。
我们使用collect() 方法的不同版本来实现一个搜索工具,该工具必须在一组没有反向索引的文件中查找查询,一个推荐系统,以及一个计算社交网络中两个用户之间常见联系人的工具。
在下一章中,我们将深入研究 Java 并发 API 提供的并发数据结构和同步机制。