- Java8 简明教程
- Java8 并发编程
- Java8 反应式编程
 PDF电子书集合
PDF电子书集合
Java8 深入研究并发数据结构和同步工具详解
每个计算机程序中最重要的元素之一是数据结构。数据结构允许我们存储应用根据需要以不同方式读取、转换和写入的数据。选择合适的数据结构是获得良好性能的关键。错误的选择会大大降低算法的性能。Java 并发 API 包括一些设计用于并发应用的数据结构,而不会引起数据不一致或信息丢失。
并发应用中的另一个关键点是同步机制。您可以使用它们通过创建一个关键部分来实现互斥,也就是说,一段代码一次只能由一个线程执行。但您也可以使用同步机制来实现线程之间的依赖关系,例如,当一个并发任务必须等待另一个任务的完成时。Java 并发 API 包括基本的同步机制,比如synchronized关键字和非常高级的工具,比如您在第 5 章中使用的CyclicBarrier类或Phaser类,分阶段运行任务–相位器类。
在本章中,我们将介绍以下主题:
每一个计算机程序都处理数据。他们从数据库、文件或其他源获取数据,转换该数据,然后将转换后的数据写入数据库、文件或其他目标。这些程序处理存储在内存中的数据,并使用数据结构将数据存储在内存中。
在实现并发应用时,必须非常小心地使用数据结构。如果不同的线程可以修改存储在唯一数据结构中的数据,则必须使用同步机制来保护对该数据结构的修改。如果不这样做,可能会出现数据争用情况。您的应用有时可能工作正常,但下一次可能会因随机异常而崩溃、卡在无限循环中或默默地产生错误的结果。结果将取决于执行的顺序。
要避免数据争用情况,您可以:
- 使用非同步数据结构,并自行添加同步机制
- 使用 Java 并发 API 提供的数据结构,该结构在内部实现同步机制,并经过优化以用于并发应用
第二个选项是最推荐的。通过本节的页面,您将回顾最重要的并发数据结构,这些数据结构特别重视 Java8 的新特性。
阻塞和非阻塞数据结构
Java 并发 API 提供两种并发数据结构:
- 阻塞数据结构:这种数据结构提供了在其上插入和删除数据的方法,当操作无法立即完成时(例如,如果您想要获取一个元素,并且数据结构为空),发出调用的线程将被阻塞,直到操作可以完成为止
- 非阻塞数据结构:这种数据结构提供了在其上插入和删除数据的方法,当操作无法立即完成时,返回特殊值或抛出异常
有时,对于阻塞数据结构,我们有一个非阻塞等价物。例如,ConcurrentLinkedDeque类是非阻塞数据结构,LinkedBlockingDeque是阻塞等价物。阻塞数据结构具有类似于非阻塞数据结构的方法。例如,Deque接口定义了pollFirst()方法,该方法在 deque 为空时不阻塞返回null。每个阻塞队列实现也实现了这个方法。
Java 集合框架(JCF提供了一组不同的数据结构,可以用于顺序编程。Java 并发 API 扩展了这些结构,提供了可在并发应用中使用的其他结构。这包括:
- 接口:扩展了 JCF 提供的接口,增加了一些可以在并发应用中使用的方法
- 类:实现前面的接口,提供可以在应用中使用的实现
在以下部分中,我们将介绍可在并发应用中使用的接口和类。
接口
首先,让我们描述并发数据结构实现的最重要的接口。
阻塞队列
队列是一种线性数据结构,允许您在队列的末尾插入元素,并从一开始获取元素。这是一种先进先出(FIFO的数据结构,队列中引入的第一个元素是最先处理的元素。
JCF 定义了Queue接口,该接口定义了队列中要实现的基本操作。此接口提供了以下方法:
- 在队列末尾插入一个元素
- 从队列头检索并删除元素
- 在不从队列头移除元素的情况下进行检索
该接口定义了这些方法的两个版本,当可以执行该方法时,它们具有不同的行为(例如,如果要检索空队列的元素):
- 引发异常的方法
- 返回特殊值的方法,例如
false或null
下表包括每个操作的方法名称:
活动
|
例外
|
特殊价值
|
| --- | --- | --- |
| 插入 | add() | offer() |
| 取回并移除 | remove() | poll() |
| 检索但不删除 | element() | peek() |
BlockingDeque接口对Queue接口进行了扩展,增加了一些方法,如果操作可以完成,可以阻止调用线程。这些方法是:
活动
|
阻碍
|
| --- | --- |
| 插入 | put() |
| 取回并移除 | take() |
| 取回而不删除 | 不适用 |
封锁德克
deque是一种线性数据结构,类似于队列,但允许您插入和删除数据结构两侧的元素。JCF 定义了扩展Queue接口的Deque接口。除了Queue接口提供的方法外,还提供了插入、检索和删除的方法,以及两端不删除的检索方法:
活动
|
例外
|
特殊价值
|
| --- | --- | --- |
| 插入 | addFirst()、addLast() | offerFirst()、offerLast() |
| 取回并移除 | removeFirst()、removeLast() | pollFirst()、pollLast() |
| 取回而不删除 | getFirst()、getLast() | peekFirst()、peekLast() |
BlockingDeque接口扩展了Deque接口,增加了当操作无法完成时阻止调用线程的方法:
活动
|
阻碍
|
| --- | --- |
| 插入 | putFirst()、putLast() |
| 取回并移除 | takeFirst()、takeLast() |
| 取回而不删除 | 不适用 |
并行图
映射(有时也称为关联数组)是一种允许您存储(键、值)对的数据结构。JCF 提供了Map接口,该接口定义了使用映射的基本操作。这包括以下方法:
-
put():在地图中插入(键、值)对 -
get():返回与键关联的值 -
remove():删除与指定键关联的(键、值)对 -
containsKey()和containsValue():如果映射包含该值的指定键,则返回 true
该接口在 Java8 中进行了修改,包括以下新方法。您将在本章后面学习如何使用这些方法:
-
forEach():此方法在地图的所有元素上执行给定的函数。 -
compute()、computeIfAbsent()和computeIfPresent():这些方法允许您指定一个函数来计算与键关联的新值。 -
merge():此方法允许您指定将(键、值)对合并到现有映射中。如果关键点不在地图中,则直接插入。如果没有,则执行指定的函数。
ConcurrentMap扩展Map接口,为并发应用提供相同的方法。注意,在 Java8 中(与 Java7 不同,ConcurrentMap接口没有向Map接口添加新方法。
【转移队列】T0
该接口扩展了BlockingQueue接口,并添加了将元素从生产者转移到消费者的方法,生产者可以在消费者取下元素后再进行转移。此接口添加的新方法有:
-
transfer():将一个元素转移到消费者,等待(阻塞调用线程)直到该元素被消费。 -
tryTransfer():如果有消费者等待,则转移元素。如果不是,则此方法返回false值,并且不在队列中插入元素。
课程
Java 并发 API 提供了前面描述的接口的不同实现。其中一些没有添加任何新特性,但另一些添加了新的有趣功能。
LinkedBlockingQueue
此类实现了BlockingQueue接口,以提供具有阻塞方法的队列,这些阻塞方法可以有有限数量的元素。它还实现了Queue、Collection和Iterable接口。
ConcurrentLinkedQueue
此类实现了Queue接口以提供线程保存无限队列。在内部,它使用非阻塞算法来保证应用中不会出现数据竞争。
链接锁紧装置
这个类实现了BlockingDeque接口,以提供一个包含阻塞方法的 deque,该阻塞方法可以有有限数量的元素。它比LinkedBlockingQueue有更多的功能,但可能有更多的开销,因此当不需要 deque 特性时,应该使用LinkedBlockingQueue。
ConcurrentLinkedEque
这个类实现了Deque接口,以提供一个线程 save unlimited deque,允许您在 deque 的两端添加和删除元素。它比ConcurrentLinkedQueue有更多的功能,但可能会像LinkedBlockingDeque一样有更多的开销。
阵列锁定队列
此类实现BlockingQueue接口,以提供基于数组的具有有限元素数目的阻塞队列的实现。它还实现了Queue、Collection和Iterable接口。与基于非并发数组的数据结构(ArrayList和ArrayDeque不同,ArrayBlockingQueue分配构造函数中指定的固定大小的数组,并且从不调整其大小。
延迟队列
此类实现了BlockingDeque接口,以提供一个具有阻塞方法和无限数量元素的队列实现。这个队列的元素必须实现Delayed接口,所以它们必须实现getDelay()方法。如果该方法返回负值或零值,则延迟已过期,可以从队列中提取元素。队列的头是延迟值为负值最大的元素。
LinkedTransferQueue
此类提供了TransferQueue接口的实现。它提供了一个具有无限数量元素的阻塞队列,并且可以将它们用作生产者和消费者之间的通信通道,生产者可以在其中等待消费者处理其元素。
优先阻塞队列
该类提供了BlockingQueue接口的实现,在该接口中,可以根据元素的自然顺序或通过类构造函数中指定的比较器轮询元素。此队列的头由元素的排序顺序决定。
ConcurrentHashMap
此类提供了ConcurrentMap接口的实现。它提供了一个线程安全的哈希表。除了 Java 8 版本中Map接口中添加的方法外,此类还添加了其他方法:
-
search()、searchEntries()、searchKeys()和searchValues():这些方法允许您对(键、值)对、键或值应用搜索功能。搜索函数可以是 lambda 表达式,当搜索函数返回 NOTNULL 值时,方法结束。这是执行该方法的结果。 -
reduce()、reduceEntries()、reduceKeys()和reduceValues():这些方法允许您应用reduce()操作来转换流中出现的(键、值)对、键或条目(请参阅第 8 章、使用并行流处理海量数据集–映射和收集模型获取更多有关reduce()方法的详细信息)。
增加了更多的方法(forEachValue、forEachKey等等),但这里不介绍这些方法。
使用新功能
在本节中,您将学习如何将 Java8 中引入的新特性用于并发数据结构。
ConcurrentHashMap 的第一个示例
在第 8 章中使用并行流处理海量数据集–地图和收集模型中,您实现了一个应用,用于搜索来自 20000 个亚马逊产品的数据集。我们从亚马逊产品联合采购网络元数据中获取了这些信息,其中包括 548552 种产品的信息,包括 title、salesrank 和类似产品。您可以从下载此数据集 https://snap.stanford.edu/data/amazon-meta.html 。在该示例中,您使用名为productsByBuyer的ConcurrentHashMap<String, List<ExtendedProduct>>来存储关于用户购买的产品的信息。此映射的键是用户的标识符,值是用户购买的产品列表。您将使用该映射来学习如何使用ConcurrentHashMap类的新方法。
forEach()方法
此方法允许您指定将在ConcurrentHashMap的每对(键、值)上执行的函数。该方法有很多版本,但最基本的版本只有一个可以表示为 lambda 表达式的BiConsumer函数。例如,您可以使用此方法打印每个用户购买了多少产品,使用以下代码:
productsByBuyer.forEach( (id, list) -> System.out.println(id+": "+list.size()));这个基本版本是通常的Map接口的一部分,并且总是按顺序执行。在这段代码中,我们使用了一个 lambda 表达式,id是元素的键,list是元素的值。
在另一个例子中,我们使用了forEach()方法来计算每个用户的平均评分。
productsByBuyer.forEach( (id, list) -> {
double average=list.stream().mapToDouble(item -> item.getValue()).average().getAsDouble();
System.out.println(id+": "+average);
});在这段代码中,我们还使用了 lambda 表达式,id是元素的键,list是元素的值。我们使用应用于产品列表的流来计算平均评级。
此方法的其他版本如下所示:
-
forEach(parallelismThreshold, action):这是您必须在并发应用中使用的方法的版本。如果映射包含的元素多于第一个参数中指定的数量,则此方法将并行执行。 -
forEachEntry(parallelismThreshold, action):与前面相同,但在本例中,该动作是Consumer接口的一个实现,该接口接收一个带有键和元素值的Map.Entry对象。在这种情况下,还可以使用 lambda 表达式。 -
forEachKey(parallelismThreshold, action):与前面相同,但在这种情况下,该动作将仅应用于ConcurrentHashMap的键。 -
forEachValue(parallelismThreshold, action):与前面相同,但在这种情况下,该动作将仅应用于ConcurrentHashMap的值。
当前实现使用公共ForkJoinPool实例执行并行任务。
search()方法
此方法将搜索功能应用于ConcurrentHashMap的所有元素。此搜索函数可以返回 null 值或与 null 不同的值。search()方法将返回搜索函数返回的第一个非空值。此方法接收两个参数:
-
parallelismThreshold:如果映射的元素数超过此参数指定的数量,则此方法将并行执行。 -
searchFunction:这是BiFunction接口的实现,可以表示为 lambda 表达式。该函数接收每个元素的键和值作为参数,如前所述,如果找到要搜索的内容,则必须返回非 null 值,如果没有,则必须返回 null 值。
例如,您可以使用此功能查找包含单词的第一本书:
ExtendedProduct firstProduct=productsByBuyer.search(100,
(id, products) -> {
for (ExtendedProduct product: products) {
if (product.getTitle() .toLowerCase().contains("java")) {
return product;
}
}
return null;
});
if (firstProduct!=null) {
System.out.println(firstProduct.getBuyer()+":"+ firstProduct.getTitle());
}在本例中,我们使用 100 作为parallelismThreshold和 lambda 表达式来实现搜索函数。在这个函数中,对于每个元素,我们处理列表中的所有产品。如果我们发现一个产品包含单词java,我们将退回该产品。这是search()方法返回的值。最后,我们在控制台中写下买家和产品的标题。
此方法还有其他版本:
-
searchEntries(parallelismThreshold, searchFunction):在这种情况下,搜索功能是Function接口的实现,该接口接收Map.Entry对象作为参数 -
searchKeys(parallelismThreshold, searchFunction):在这种情况下,搜索功能仅应用于ConcurrentHashMap的按键 -
searchValues(parallelismThreshold, searchFunction):在这种情况下,搜索功能仅应用于ConcurrentHashMap的值
reduce()方法
此方法类似于Stream框架提供的reduce()方法,但在本例中,您直接使用ConcurrentHashMap的元素。此方法接收三个参数:
-
parallelismThreshold:如果ConcurrentHashMap的元素数超过此参数指定的数量,则此方法将并行执行。 -
transformer:此参数是BiFunction接口的实现,可以表示为 lambda 函数。它接收一个键和一个值作为参数,并返回这些元素的转换。 -
reducer:此参数是BiFunction接口的实现,也可以表示为 lambda 函数。它接收 transformer 函数返回的两个对象作为参数。此功能的目标是将这两个对象组合为一个对象。
作为该方法的一个示例,我们将获得一个具有1(最差值)值的评审的产品列表。我们使用了两个辅助变量。第一个是transformer。这是一个BiFunction接口,我们将使用它作为reduce() 方法的transformer元素:
BiFunction<String, List<ExtendedProduct>, List<ExtendedProduct>> transformer = (key, value) -> value.stream().filter(product -> product.getValue() == 1).collect(Collectors.toList());此功能将接收用户的id密钥和该用户购买产品的ExtendedProduct对象列表。我们处理列表中的所有产品,并返回评级为 1 的产品。
第二个变量是减速器BinaryOperator。我们将其用作reduce()方法的减速器功能:
BinaryOperator<List<ExtendedProduct>> reducer = (list1, list2) ->{
list1.addAll(list2);
return list1;
};reduce 接收两个ExtendedProduct列表,并使用addAll()方法将它们连接成一个列表。
现在,我们只需要实现对reduce()方法的调用:
List<ExtendedProduct> badReviews=productsByBuyer.reduce(10, transformer, reducer);
badReviews.forEach(product -> {
System.out.println(product.getTitle()+":"+ product.getBuyer()+":"+product.getValue());
});reduce()方法还有其他版本:
-
reduceEntries()、reduceEntriesToDouble()、reduceEntriesToInt()和reduceEntriesToLong():在这种情况下,变压器和减速器功能在Map.Entry对象上工作。最后三个版本分别返回一个double、一个int和一个long值。 -
reduceKeys()、reduceKeysToDouble()和reduceKeysToInt()、reduceKeysToLong():在这种情况下,变压器和减速器功能在地图的键上工作。最后三个版本分别返回一个double,一个int。和一个long值。 -
reduceToInt()、reduceToDouble()和reduceToLong():在这种情况下,transformer 功能分别作用于键和值,reducer 方法分别作用于int、double或long号。这些方法返回一个int、double和long值。 -
reduceValues()、reduceValuesToDouble()、reduceValuesToInt()和reduceValuesToLong():在这种情况下,变压器和减速器功能在映射的值上工作。最后三个版本分别返回一个double、一个int和一个long值。
compute()方法
此方法(在Map接口中定义)将元素的键和BiFunction接口的实现作为参数接收,该接口可以表示为 lambda 表达式。如果ConcurrentHashMap中存在该键,则该函数将接收该元素的键和值;如果ConcurrentHashMap中不存在该键,则该函数将接收 null。该方法将用函数返回的值替换与键关联的值,如果不存在,则将其插入到ConcurrentHashMap中,如果为先前存在的项返回了null,则删除该项。请注意,在BiFunction执行期间,可以锁定一个或多个映射条目。因此,您的BiFunction不应该工作很长时间,也不应该尝试更新同一地图中的任何其他条目。否则可能会出现死锁。
例如,我们可以将此方法与 Java8 中引入的名为LongAdder的新原子变量一起使用,以计算与每个产品相关联的不良评论的数量。我们创建了一个名为 counter 的新ConcurrentHashMap。关键是产品的标题和LongAdder类的对象值,用于计算每个产品有多少不良评论。
ConcurrentHashMap<String, LongAdder> counter=new ConcurrentHashMap<>();我们处理上一节计算的badReviews``ConcurrentLinkedDeque的所有元素,并使用compute()方法创建和更新与每个产品关联的LongAdder。
badReviews.forEach(product -> {
counter.computeIfAbsent(product.getTitle(), title -> new LongAdder()).increment();
});
counter.forEach((title, count) -> {
System.out.println(title+":"+count);
});最后,我们在控制台中编写结果。
ConcurrentHashMap 的另一个示例
ConcurrentHashMap类中增加了另一个方法,在 Map 接口中定义。正是merge()方法允许您将(键、值)对合并到映射中。如果ConcurrentHashMap中不存在密钥,则直接插入。如果该键存在,则必须从旧键和新键中定义与该键关联的新值。此方法接收三个参数:
- 我们要合并的密钥。
- 我们要合并的值。
-
BiFunction的一个实现,可以表示为 lambda 表达式。此函数接收与键关联的旧值和新值作为参数。该方法将与此函数返回的值的键相关联。BiFunction是在映射的部分锁下执行的,因此保证不会对同一个密钥同时执行。
例如,我们已将上一节中使用的亚马逊 20000 个产品在审查年度的文件中进行了拆分。每年,我们都会加载ConcurrentHashMap,其中产品是关键,评审列表是价值。因此,我们可以使用以下代码加载 1995 年和 1996 年的审查:
Path path=Paths.get("data\\amazon\\1995.txt");
ConcurrentHashMap<BasicProduct, ConcurrentLinkedDeque<BasicReview>> products1995=BasicProductLoader.load(path);
showData(products1995);
path=Paths.get("data\\amazon\\1996.txt");
ConcurrentHashMap<BasicProduct, ConcurrentLinkedDeque<BasicReview>> products1996=BasicProductLoader.load(path);
System.out.println(products1996.size());
showData(products1996);如果我们想将ConcurrentHashMap的两个版本合并为一个,我们可以使用以下代码:
products1996.forEach(10,(product, reviews) -> {
products1995.merge(product, reviews, (reviews1, reviews2) -> {
System.out.println("Merge for: "+product.getAsin());
reviews1.addAll(reviews2);
return reviews1;
});
});我们处理 1996 年ConcurrentHashMap的所有元素,对于每个(键、值)对,我们在 1995 年ConcurrentHashMap上调用merge()方法。merge功能将接收两个评论列表,因此我们只需将它们连接成一个。
ConcurrentLinkedQue 类的示例
Collection接口还包括 Java8 中的新方法。大多数并发数据结构都实现了这个接口,因此我们可以使用这些新特性。其中两种是第 7 章中使用的stream()和parallelStream()方法;使用并行流处理海量数据集–映射和约简模型和第 8 章,使用并行流处理海量数据集–映射和收集模型。让我们看看如何将另外两个使用ConcurrentLinkedDeque的产品与我们在前面章节中使用的 20000 个产品一起使用。
removeIf()方法
此方法在Collection接口中有一个默认实现,该实现不是并发的,并且不被ConcurrentLinkedDeque类重写。此方法接收Predicate接口的实现作为参数,该接口将接收Collection元素作为参数,并应返回true或false值。该方法将处理Collection的所有元素,并删除那些通过谓词获得true值的元素。
例如,如果要删除 salesrank 高于 1000 的所有产品,可以使用以下代码:
System.out.println("Products: "+productList.size());
productList.removeIf(product -> product.getSalesrank() > 1000);
System.out.println("Products; "+productList.size());
productList.forEach(product -> {
System.out.println(product.getTitle()+": "+product.getSalesrank());
});spliterator()方法
此方法返回Spliterator接口的实现。拆分器定义StreamAPI 可以使用的数据源。您很少需要直接使用 spliterator,但有时可能需要创建自己的 spliterator 来生成流的自定义源(例如,如果您实现自己的数据结构)。如果您有自己的拆分器实现,您可以使用StreamSupport.stream(mySpliterator, isParallel)在其上创建流。这里,isParallel是一个布尔值,用于确定创建的流是否并行。拆分器类似于迭代器,可以使用它遍历集合中的所有元素,但可以拆分它们以并发方式进行遍历。
拆分器有八个不同的特性来定义其行为:
-
CONCURRENT:可以安全地同时修改拆分器源 -
DISTINCT:拆分器返回的所有元素都是不同的 -
IMMUTABLE:拆分器源不能修改 -
NONNULL:拆分器从不返回null值 -
ORDERED:拆分器返回的元素是有序的(表示它们的顺序很重要) -
SIZED:拆分器能够使用estimateSize()方法返回精确数量的元素 -
SORTED:拆分器源已排序 -
SUBSIZED:如果您使用trySplit()方法拆分此拆分器,则生成的拆分器将为SIZED和SUBSIZED
此接口最有用的方法是:
-
estimatedSize():此方法将估计拆分器中的元素数。 -
forEachRemaining():此方法允许您将Consumer接口的实现应用于尚未处理的拆分器元素,该接口可以用 lambda 函数表示。 -
tryAdvance():此方法允许您将Consumer接口的实现应用于拆分器要处理的下一个元素(如果有),该接口可以用 lambda 函数表示。 -
trySplit():此方法尝试将拆分器拆分为两部分。调用方拆分器将处理一些元素,返回的拆分器将处理其他元素。如果拆分器为ORDERED,则返回的拆分器必须处理元素的严格前缀,调用必须处理严格后缀。 -
hasCharacteristics():此方法允许您检查拆分器的属性。
让我们看一个具有ArrayList数据结构的此方法的示例,其中包含 20000 个产品。
首先,我们需要一个辅助任务来处理一组产品,将它们的标题转换为小写。此任务将有一个Spliterator作为属性:
public class SpliteratorTask implements Runnable {
private Spliterator<Product> spliterator;
public SpliteratorTask (Spliterator<Product> spliterator) {
this.spliterator=spliterator;
}
@Override
public void run() {
int counter=0;
while (spliterator.tryAdvance(product -> {
product.setTitle(product.getTitle().toLowerCase());
})) {
counter++;
};
System.out.println(Thread.currentThread().getName() +":"+counter);
}
}如您所见,此任务在完成执行时写入已处理产品的数量。
在主要方法中,一旦我们将 20000 个产品装入ConcurrentLinkedQueue,我们就可以获得拆分器,检查它的一些特性,并查看它的估计尺寸。
Spliterator<Product> split1=productList.spliterator();
System.out.println(split1.hasCharacteristics (Spliterator.CONCURRENT));
System.out.println(split1.hasCharacteristics (Spliterator.SUBSIZED));
System.out.println(split1.estimateSize());然后,我们可以使用trySplit()方法划分拆分器,并查看两个拆分器的大小:
Spliterator<Product> split2=split1.trySplit();
System.out.println(split1.estimateSize());
System.out.println(split2.estimateSize());最后,我们可以在一个执行器中执行两个任务,一个用于拆分器,以查看每个拆分器是否真正处理了预期数量的元素。
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
executor.execute(new SpliteratorTask(split1));
executor.execute(new SpliteratorTask(split2));在以下屏幕截图中,您可以看到执行此示例的结果:

您可以看到在拆分拆分器之前,estimatedSize()方法如何返回 20000 个元素。执行trySplit()方法后,两个拆分器都有 10000 个元素。这些是每个任务处理的元素。
原子变量
Java 1.5 中引入了原子变量,以提供对integer、long、boolean、reference和Array对象的原子操作。它们提供了一些方法来递增、递减、建立值、返回值,或者在当前值等于预定义值时建立值。
在 Java8 中,添加了四个新类。它们是DoubleAccumulator、DoubleAdder、LongAccumulator和LongAdder。在上一节中,我们使用LongAdder类统计产品的不良评论数量。此类提供了与AtomicLong类似的功能,但当您频繁更新来自不同线程的累积和,并且仅在操作结束时请求结果时,此类的性能更好。DoubleAdder函数与之相同,但具有双值。这两个类的主要目标都是拥有一个计数器,该计数器可以由不同的线程以一致的方式更新。这些类中最重要的方法是:
-
add():使用指定为参数的值增加计数器的值 -
increment():相当于add(1) -
decrement():相当于add(-1) -
sum():此方法返回计数器的当前值
考虑到DoubleAdder类没有increment()和decrement()方法。
LongAccumulator和DoubleAccumulator类相似,但它们有一个非常重要的区别。它们有一个构造函数,您可以在其中指定两个参数:
- 内部计数器的标识值
- 将新值累加到累加器中的函数
请注意,函数不得依赖于累加顺序。在这种情况下,最重要的方法是:
-
accumulate():此方法接收long值作为参数。它应用函数将计数器增加或减少到当前值和参数。 -
get():返回计数器的当前值。
例如,以下代码将在所有执行中在控制台中写入 362880:
LongAccumulator accumulator=new LongAccumulator((x,y) -> x*y, 1);
IntStream.range(1, 10).parallel().forEach(x -> accumulator.accumulate(x));
System.out.println(accumulator.get());我们在累加器中使用交换运算,因此对于任何输入顺序,结果都是相同的。
任务同步是指在这些任务之间进行协调,以获得所需的结果。在并发应用中,我们可以有两种同步:
- 进程同步:当我们想要控制任务的执行顺序时,我们使用这种同步。例如,任务在开始执行之前必须等待其他任务的完成。
- 数据同步:当两个或多个任务访问同一个内存对象时,我们使用这种同步。在这种情况下,必须保护对该对象的写入操作中的访问。如果不这样做,可能会出现一个数据竞争条件,即程序的最终结果会随着执行的不同而变化。
Java 并发 API 提供了允许您实现这两种同步的机制。Java 语言提供的最基本的同步机制是synchronized关键字。此关键字可以应用于方法或代码块。在第一种情况下,一次只能有一个线程执行该方法。在第二种情况下,必须指定对对象的引用。在这种情况下,同一时间只能执行一个受对象保护的代码块。
Java 还提供其他同步机制:
-
Lock接口及其实现类:此机制允许您实现一个关键部分,以确保只有一个线程将执行该代码块。 - 实现Edsger Dijkstra引入的众所周知的信号量同步机制的
Semaphore类。 -
CountDownLatch允许您实现一个或多个线程等待其他线程完成的情况。 -
CyclicBarrier允许您在一个公共点上同步不同的任务。 -
Phaser允许您分阶段执行并发任务。我们在第 5 章中对该机制进行了详细描述,将运行任务分为阶段–相位器类。 -
Exchanger允许您在两个任务之间实现一个数据交换点。 - Java 8 的新特性
CompletableFuture扩展了执行者任务的Future机制,以异步方式生成任务的结果。您可以指定生成结果后要执行的任务,以便控制任务的执行顺序。
在下一节中,我们将向您展示如何使用这些机制,特别注意 Java8 版本中引入的CompletableFuture机制。
CommonTask 类
我们实现了一个名为CommonTask类的类。此类将在0和10秒之间的随机时间段内休眠调用线程。这是它的源代码:
public class CommonTask {
public static void doTask() {
long duration = ThreadLocalRandom.current().nextLong(10);
System.out.printf("%s-%s: Working %d seconds\n",new Date(),Thread.currentThread().getName(),duration);
try {
TimeUnit.SECONDS.sleep(duration);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}我们将在以下部分中实现的所有任务都将使用该类来模拟其执行时间。
锁接口
最基本的同步机制之一是Lock接口及其实现类。基本的实现类是ReentrantLock类。您可以使用此类以简单的方式实现关键部分。例如,下面的任务使用lock()方法在其代码的第一行获得锁,并使用unlock()方法在最后一行释放锁。只有一个任务可以同时执行这两句话之间的代码。
public class LockTask implements Runnable {
private static ReentrantLock lock = new ReentrantLock();
private String name;
public LockTask(String name) {
this.name=name;
}
@Override
public void run() {
try {
lock.lock();
System.out.println("Task: " + name + "; Date: " + new Date() + ": Running the task");
CommonTask.doTask();
System.out.println("Task: " + name + "; Date: " + new Date() + ": The execution has finished");
} finally {
lock.unlock();
}
}
}例如,如果您使用以下代码在一个执行器中执行十个任务,则可以对此进行检查:
public class LockMain {
public static void main(String[] args) {
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new LockTask("Task "+i));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}在下图中,您可以看到执行此示例的结果。您可以看到一次如何只执行一个任务。

信号量类
信号量机制由 Edsger Dijkstra 于 1962 年引入,用于控制对一个或多个共享资源的访问。此机制基于一个内部计数器和两个名为wait()和signal()的方法。当线程调用wait()方法时,如果内部计数器的值大于 0,则信号量递减内部计数器,线程访问共享资源。如果内部计数器的值为 0,线程将被阻塞,直到有线程调用signal()方法。当线程调用signal()方法时,信号量会查看是否有一些线程处于waiting状态(它们调用了wait()方法)。如果没有线程等待,它将递增内部计数器。如果有线程在等待信号量,它将获取其中一个线程,该线程将返回wait()方法并访问共享资源。其他正在等待的线程继续等待轮到它们。
在 Java 中,信号量在Semaphore类中实现。wait()方法称为acquire(),而signal()方法称为release()。例如,在本例中,我们在Semaphore类保护其代码的情况下使用了此任务:
public class SemaphoreTask implements Runnable{
private Semaphore semaphore;
public SemaphoreTask(Semaphore semaphore) {
this.semaphore=semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
CommonTask.doTask();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}
}在主程序中,我们执行十个任务,这些任务共享一个用两个共享资源初始化的Semaphore类,因此我们将同时运行两个任务。
public static void main(String[] args) {
Semaphore semaphore=new Semaphore(2);
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new SemaphoreTask(semaphore));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}下面的屏幕截图显示了执行此示例的结果。您可以看到两个任务如何同时运行:
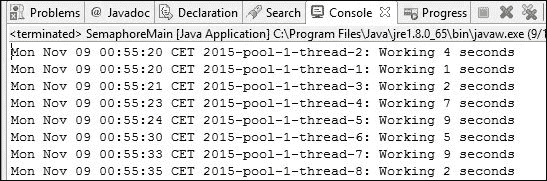
倒计时闩锁类
此类提供了一种等待一个或多个并发任务完成的机制。它有一个内部计数器,必须用我们要等待的任务数初始化它。然后,await()方法休眠调用线程,直到内部计数器到达零,countDown()方法递减该内部计数器。
例如,在本任务中,我们使用countDown()方法减少CountDownLatch对象的内部计数器,该对象作为其构造函数中的参数接收。
public class CountDownTask implements Runnable {
private CountDownLatch countDownLatch;
public CountDownTask(CountDownLatch countDownLatch) {
this.countDownLatch=countDownLatch;
}
@Override
public void run() {
CommonTask.doTask();
countDownLatch.countDown();
}
}然后,在main()方法中,我们在执行器中执行任务,并使用CountDownLatch的await()方法等待它们的最终完成。该对象使用我们要等待的任务数初始化。
public static void main(String[] args) {
CountDownLatch countDownLatch=new CountDownLatch(10);
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
System.out.println("Main: Launching tasks");
for (int i=0; i<10; i++) {
executor.execute(new CountDownTask(countDownLatch));
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.
executor.shutdown();
}以下屏幕截图显示了执行此示例的结果:

自行车运载类
此类允许您在公共点同步某些任务。所有任务将在此点等待,直到所有任务都已到达。在内部,它还管理一个内部计数器,其中包含尚未到达该点的任务。当一个任务到达确定的点时,它必须执行await()方法来等待其余的任务。当所有任务到达后,CyclicBarrier对象会唤醒它们,以便它们继续执行。
此类允许您在所有参与方到达时执行另一个任务。要进行配置,必须在对象的构造函数中指定可运行对象。
例如,我们实现了以下 Runnable,它使用CyclicBarrier对象等待其他任务:
public class BarrierTask implements Runnable {
private CyclicBarrier barrier;
public BarrierTask(CyclicBarrier barrier) {
this.barrier=barrier;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+": Phase 1");
CommonTask.doTask();
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+": Phase 2");
}
}我们还实现了另一个Runnable对象,当所有任务都执行了await()方法时,CyclicBarrier将执行该对象。
public class FinishBarrierTask implements Runnable {
@Override
public void run() {
System.out.println("FinishBarrierTask: All the tasks have finished");
}
}最后,在main()方法中,我们在一个执行器中执行十个任务。您可以看到CyclicBarrier是如何用我们想要同步的任务数和FinishBarrierTask对象的对象初始化的:
public static void main(String[] args) {
CyclicBarrier barrier=new CyclicBarrier(10,new FinishBarrierTask());
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new BarrierTask(barrier));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}以下屏幕截图显示了执行此示例的结果:

您可以看到,当所有任务到达调用await()方法的点时,FinishBarrierTask被执行,然后所有任务继续执行。
可完成的未来类
这是 Java8 并发 API 中引入的新同步机制。它扩展了Future机制,赋予其更大的动力和灵活性。它允许您实现一个事件驱动模型,链接只有在其他任务完成时才会执行的任务。与Future接口一样,CompletableFuture必须用操作返回的结果类型参数化。与Future对象一样,CompletableFuture类表示异步计算的结果,但CompletableFuture的结果可以由任何线程建立。当计算正常结束时有complete()方法建立结果,当计算异常结束时有completeExceptionally()方法。如果两个或多个线程在同一个CompletableFuture上调用complete()或completeExceptionally()方法,则只有第一个调用生效。
首先,您可以使用其构造函数创建CompletableFuture。在这种情况下,您必须使用前面解释的complete()方法来确定任务的结果。但您也可以使用runAsync()或supplyAsync()方法创建一个。runAsync()方法执行Runnable对象并返回CompletableFuture<Void>,因此计算无法返回任何结果。supplyAsync()方法执行Supplier接口的一个实现,该接口用该计算返回的类型参数化。Supplier接口提供get()方法。在该方法中,我们必须包含任务的代码并返回由其生成的结果。在这种情况下,CompletableFuture的结果将是Supplier接口的结果。
此类提供了许多方法,允许您组织实现事件驱动模型的任务的执行顺序,其中一个任务直到前一个任务完成后才开始执行。以下是其中一些方法:
-
thenApplyAsync():该方法将Function接口的实现作为参数接收,该接口可以表示为 lambda 表达式。调用CompletableFuture完成后,执行此功能。此方法将返回CompletableFuture以获取Function的结果。 -
thenComposeAsync():此方法类似于thenApplyAsync,但在提供的函数返回CompletableFuture时也很有用。 -
thenAcceptAsync():此方法与前一方法类似,但参数是Consumer接口的实现,也可以指定为 lambda 表达式;在这种情况下,计算不会返回结果。 -
thenRunAsync():此方法与前一种方法相同,但在本例中接收一个Runnable对象作为参数。 -
thenCombineAsync():此方法接收两个参数。第一个是另一个CompletableFuture实例。另一个是可指定为 lambda 函数的BiFunction接口的实现。此BiFunction将在CompletableFuture(调用方和参数)都已完成时执行。此方法将返回CompletableFuture以获取BiFunction的结果。 -
runAfterBothAsync():此方法接收两个参数。第一个是另一个CompletableFuture。另一个是Runnable接口的实现,当CompletableFuture(调用方和参数)都完成时,将执行该接口。 -
runAfterEitherAsync():此方法与前一个方法相同,但可运行任务在CompletableFuture对象之一完成时执行。 -
allOf():此方法接收CompletableFuture对象的变量列表作为参数。它将返回一个CompletableFuture<Void>对象,该对象将在所有CompletableFuture对象完成后返回其结果。 -
anyOf():此方法与前一个方法相同,但返回的CompletableFuture在CompletableFuture中的一个完成时返回其结果。
最后,如果要获取CompletableFuture返回的结果,可以使用get()或join()方法。这两种方法都会阻止调用线程,直到CompletableFuture完成,然后返回其结果。两种方法的主要区别在于get()抛出ExecutionException,这是一个已检查的异常,而join()抛出RuntimeException(这是一个未检查的异常)。因此,在非投掷 lambda 中使用join()更容易(如Supplier、Consumer或Runnable。
前面介绍的大多数方法都有Async后缀。这意味着这些方法将使用ForkJoinPool.commonPool实例以并发方式执行。那些版本中没有Async后缀的方法将以串行方式执行(即,在执行CompletableFuture的同一线程中),并将Async后缀和执行器实例作为附加参数。在这种情况下,CompletableFuture将在作为参数传递的执行器中异步执行。
使用 CompletableFuture 类
在本例中,您将学习如何使用CompletableFuture类以并发方式实现一些异步任务的执行。我们将使用亚马逊的 20000 个产品集合来实现以下任务树:
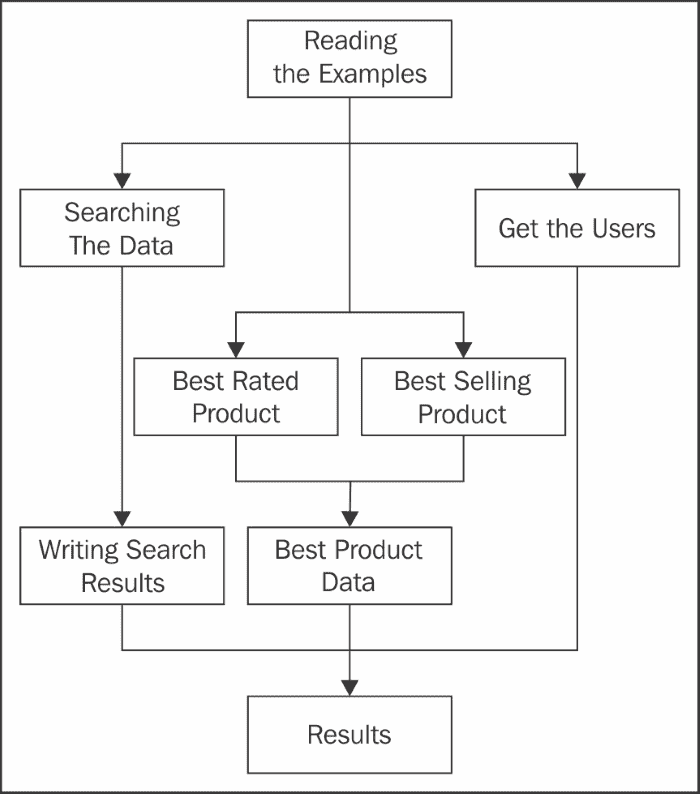
首先,我们将使用这些示例。然后,我们将执行四个并发任务。第一个将搜索产品。搜索完成后,我们将结果写入一个文件。第二个将获得最佳评级的产品。第三个将获得最畅销的产品。当这两个任务都完成时,我们将使用另一个任务连接它们的信息。最后,第四个任务将获得一个包含已购买产品的用户的列表。main()程序将等待所有任务的完成,然后写入结果。
让我们看看实现的细节。
辅助任务
在本例中,我们将使用一些辅助任务。第一个是LoadTask,它将从磁盘加载产品信息并返回Product对象列表。
public class LoadTask implements Supplier<List<Product>> {
private Path path;
public LoadTask (Path path) {
this.path=path;
}
@Override
public List<Product> get() {
List<Product> productList=null;
try {
productList = Files.walk(path, FileVisitOption.FOLLOW_LINKS).parallel()
.filter(f -> f.toString().endsWith(".txt")) .map(ProductLoader::load).collect (Collectors.toList());
} catch (IOException e) {
e.printStackTrace();
}
return productList;
}
}它实现了要作为CompletableFuture执行的Supplier接口。在内部,它使用一个流来处理和解析所有文件,从而获得产品列表。
第二个任务是SearchTask,它将在Product对象列表中执行搜索,查找标题中包含单词的对象。此任务是Function接口的实现。
public class SearchTask implements Function<List<Product>, List<Product>> {
private String query;
public SearchTask(String query) {
this.query=query;
}
@Override
public List<Product> apply(List<Product> products) {
System.out.println(new Date()+": CompletableTask: start");
List<Product> ret = products.stream()
.filter(product -> product.getTitle() .toLowerCase().contains(query))
.collect(Collectors.toList());
System.out.println(new Date()+": CompletableTask: end: "+ret.size());
return ret;
}
}接收到包含所有产品信息的List<Product>以及符合条件的产品的退货List<Product>。在内部,它在输入列表上创建流,对其进行过滤,并将结果收集到另一个列表中。
最后,WriteTask将在File中写入搜索任务中获得的产品。在我们的例子中,我们生成了一个 HTML 文件,但是可以用您想要的格式编写这些信息。此任务实现了Consumer接口,因此其代码必须如下所示:
public class WriteTask implements Consumer<List<Product>> {
@Override
public void accept(List<Product> products) {
// implementation is omitted
}
}main()方法
我们已经按照main()方法组织了任务的执行。首先,我们使用CompletableFuture类的supplyAsync()方法执行LoadTask。
public class CompletableMain {
public static void main(String[] args) {
Path file = Paths.get("data","category");
System.out.println(new Date() + ": Main: Loading products");
LoadTask loadTask = new LoadTask(file);
CompletableFuture<List<Product>> loadFuture = CompletableFuture
.supplyAsync(loadTask);然后,使用结果CompletableFuture,我们使用thenApplyAsync()在加载任务完成后执行搜索任务。
System.out.println(new Date() + ": Main: Then apply for search");
CompletableFuture<List<Product>> completableSearch = loadFuture
.thenApplyAsync(new SearchTask("love"));搜索任务完成后,我们希望将执行结果写入一个文件中。由于此任务不会返回结果,我们使用thenAcceptAsync()方法:
CompletableFuture<Void> completableWrite = completableSearch
.thenAcceptAsync(new WriteTask());
completableWrite.exceptionally(ex -> {
System.out.println(new Date() + ": Main: Exception "
+ ex.getMessage());
return null;
});我们已经使用 exceptive()方法来指定在写入任务引发异常时要执行的操作。
然后,我们在completableFuture对象上使用thenApplyAsync()方法来执行任务,以获取购买产品的用户列表。我们将此任务指定为 lambda 表达式。考虑到此任务将与搜索任务并行执行。
System.out.println(new Date() + ": Main: Then apply for users");
CompletableFuture<List<String>> completableUsers = loadFuture
.thenApplyAsync(resultList -> {
System.out.println(new Date()
+ ": Main: Completable users: start");
List<String> users = resultList.stream()
.flatMap(p -> p.getReviews().stream())
.map(review -> review.getUser())
.distinct()
.collect(Collectors.toList());
System.out.println(new Date()
+ ": Main: Completable users: end");
return users;
});在完成这些任务的同时,我们还使用thenApplyAsync()方法执行了这些任务,以找到评级最佳的产品和最畅销的产品。我们也使用 lambda 表达式定义了这些任务。
System.out.println(new Date()
+ ": Main: Then apply for best rated product....");
CompletableFuture<Product> completableProduct = loadFuture
.thenApplyAsync(resultList -> {
Product maxProduct = null;
double maxScore = 0.0;
System.out.println(new Date()
+ ": Main: Completable product: start");
for (Product product : resultList) {
if (!product.getReviews().isEmpty()) {
double score = product.getReviews().stream()
.mapToDouble(review -> review.getValue())
.average().getAsDouble();
if (score > maxScore) {
maxProduct = product;
maxScore = score;
}
}
}
System.out.println(new Date()
+ ": Main: Completable product: end");
return maxProduct;
});
System.out.println(new Date()
+ ": Main: Then apply for best selling product....");
CompletableFuture<Product> completableBestSellingProduct = loadFuture
.thenApplyAsync(resultList -> {
System.out.println(new Date() + ": Main: Completable best selling: start");
Product bestProduct = resultList
.stream()
.min(Comparator.comparingLong (Product::getSalesrank))
.orElse(null);
System.out.println(new Date()
+ ": Main: Completable best selling: end");
return bestProduct;
});正如我们前面提到的,我们希望连接最后两个任务的结果。我们可以使用thenCombineAsync()方法来指定两个任务完成后将执行的任务。
CompletableFuture<String> completableProductResult = completableBestSellingProduct
.thenCombineAsync(
completableProduct, (bestSellingProduct, bestRatedProduct) -> {
System.out.println(new Date() + ": Main: Completable product result: start");
String ret = "The best selling product is " + bestSellingProduct.getTitle() + "\n";
ret += "The best rated product is "
+ bestRatedProduct.getTitle();
System.out.println(new Date() + ": Main: Completable product result: end");
return ret;
});最后,我们使用allOf()和join()方法等待最终任务的结束,并使用get()方法写入结果以获得它们。
System.out.println(new Date() + ": Main: Waiting for results");
CompletableFuture<Void> finalCompletableFuture = CompletableFuture
.allOf(completableProductResult, completableUsers,
completableWrite);
finalCompletableFuture.join();
try {
System.out.println("Number of loaded products: "
+ loadFuture.get().size());
System.out.println("Number of found products: "
+ completableSearch.get().size());
System.out.println("Number of users: "
+ completableUsers.get().size());
System.out.println("Best rated product: "
+ completableProduct.get().getTitle());
System.out.println("Best selling product: "
+ completableBestSellingProduct.get() .getTitle());
System.out.println("Product result: "+completableProductResult.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}在以下屏幕截图中,您可以看到此示例的执行结果:
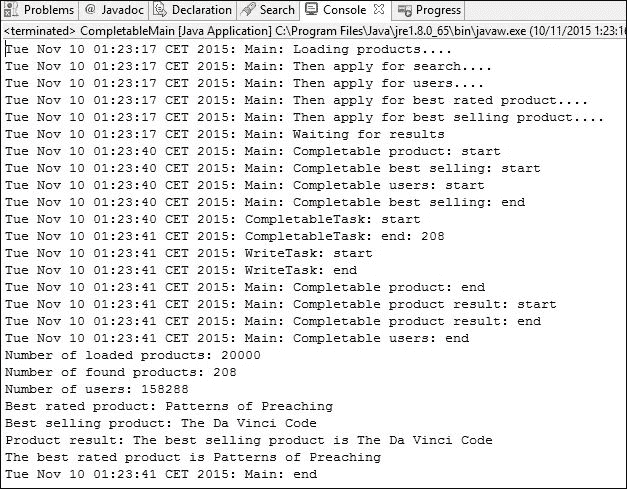
首先,main()方法执行所有配置并等待任务的完成。任务的执行遵循我们配置的顺序。
在本章中,我们回顾了所有并发应用的两个组件。第一个是数据结构。每个程序都使用它们在内存中存储它必须处理的信息。我们很快就了解了并发数据结构,详细描述了 Java 8 并发 API 中引入的影响ConcurrentHashMap类和实现Collection接口的类的新特性。
第二种是同步机制,允许您在多个并发任务需要修改数据时保护数据,并在必要时控制任务的执行顺序。在本例中,我们还很快地介绍了同步机制,详细描述了CompletableFuture,这是 Java 8 并发 API 的一个新特性。
在下一章中,我们将向您展示如何实现完整的并发系统,集成也可以并发的不同部分,并使用不同的类实现其并发性。