本文整理自 BIGO 在 nMeetp 上的主题分享,主要介绍 BIGO 过去一年在数据管理建设方面的理解和探索。而 BIGO 数据管理的核心重点在于元数据平台的建设,用以支撑上层数据管理和建设应用,包括数据地图、数据建模、数据治理和权限管理等等。本文主要围绕以下五个方向展开:
- OneMeta 基础建设;
- 图引擎:Nebula 替换 JanusGraph
- 数据资产平台应用;
- Adhoc 即席查询;
- 未来规划
数据管理平台
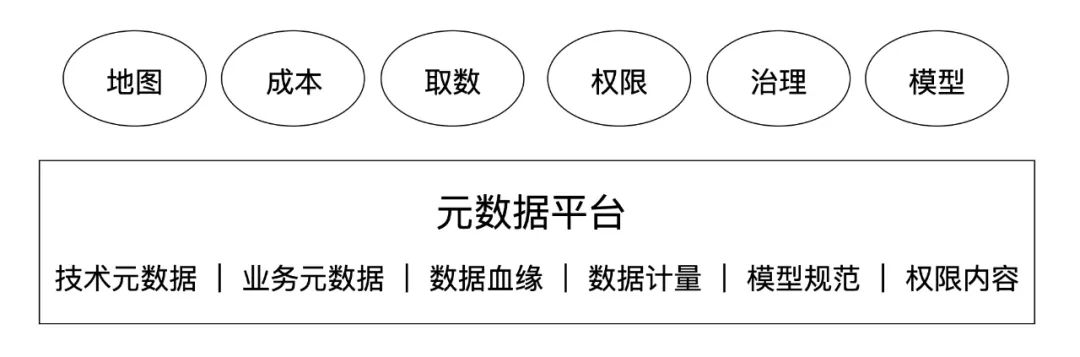
上图为 BIGO 数据资产管理平台的抽象图,如上图所示,在元数据平台里面存储着技术元数据、业务元数据、数据血缘、数据计量、规范模型、权限内容等数据,基于元数据平台上层对接应用层,包括:地图、成本、取数、权限、治理、模型。
OneMeta 基础建设
业务背景
目前 BIGO 数据管理面临以下问题:
- 元数据杂乱无标准,没有统一的搜索和管理平台;
- 数据没有血缘关系,各个开发平台如同数据孤岛;
- 没有业务类元数据,业务方难以查询及统一口径;
- 数据权限管控粗放,权限申请及审批流程原始化;
简单来说:缺少标准、数据缺少联系、缺少业务元数据、缺少细颗粒度的权限管控,为此,BIGO 内部搭建了元数据管理平台 OneMeta 来解决上述问题。
而 OneMeta 的平台能力如下:
- 全域元数据实时入库及管理功能,统一构建公司个人及团队数据资产目录。
- 数据地图、取数查询、数据治理、血缘姻联、权限管理、规范模型等应用存储管理能力。
- 支持 HIVE / HDFS / OOZIE / CLICKHOUSE / BAINA / SPARKSQL / KYUUBI / KAFKA 等元数据及血缘关系的存储。
- 精准计量业务元数据:各式各样的元数据的操作次数、冷热程度、业务归属等信息更新。
元数据平台架构
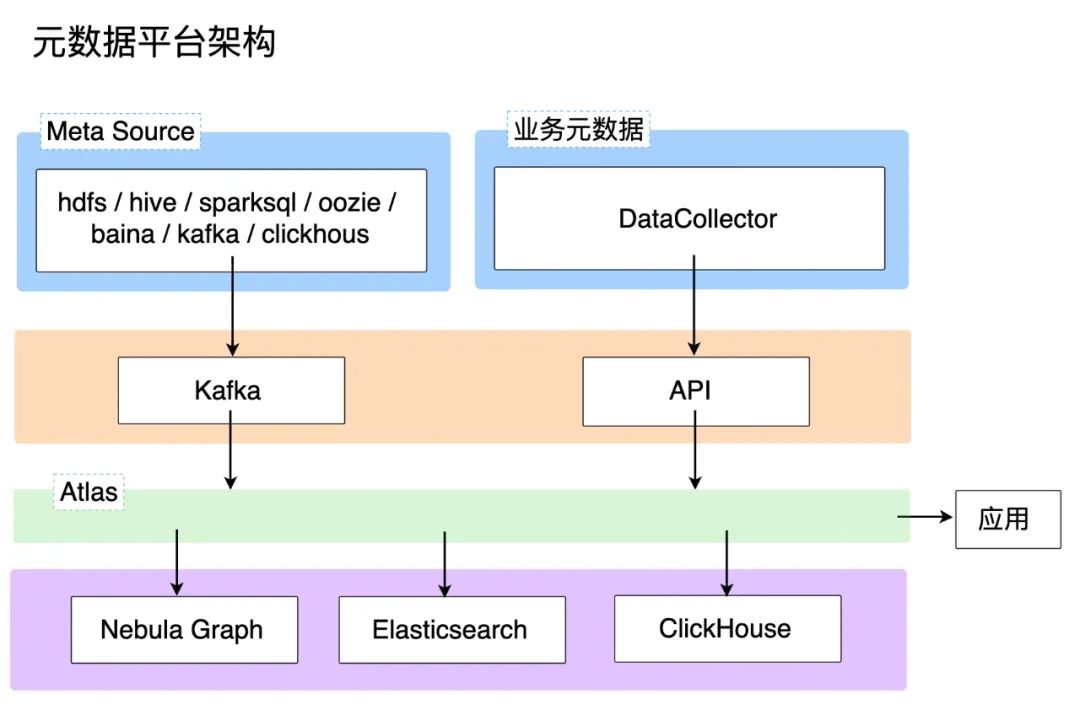
BIGO 元数据平台主要依赖 Apache Atlas、Vesoft Nebula、Yandex ClickHouse 和 BIGO 内部开发的 DataCollector 进行构建,整体上可以划分为四层。
最上层(蓝色部分)是数据采集的源头和 DataCollector 服务,各个平台的技术元数据主要以 Hook 的形式实时收集,而业务元数据则通过 DataCollector 服务以小时或天级定时调度、更新;第二层(橙色部分)是消息队列和 API 层,提供通道接入数据到 Atlas;第三层则是 Atlas(绿色部分),这是最核心的元数据管理层,所有元数据、属性信息和血缘关系等都在 Atlas 进行管理,此外 Atlas 层还提供了接口供应用调用;最底层(紫色部分)是存储层,主要使用 Nebula Graph、Elasticsearch 和 ClickHouse,其中主要的元数据都存储在 Nebula 中,其中需要全文索引的数据通过 Nebula Graph 转存到 ES,而需要查询历史趋势或聚合的数据时,则去 CK(ClickHouse)中读取数据。
Apache Atlas 优化
这部分讲解下 BIGO 基于开源的 Atlas 做了何种优化,主要有以下方面的优化:
- 通过 SpringBoot 切面实现审计能力建设。
- 引入 MicroMeter 和 Prometheus 实现监控告警能力建设。
- 抽离图引擎依赖,支持分布式 Nebula Graph 图引擎的读写,新增 3w+ 行代码。
- 新增访问速度控制及黑白名单功能,控制突发流量和恶意访问,保证系统稳定。
- 定期任务,以便清理失效 Process 过程数据,避免数据膨胀。
- 添加 Atlas 平滑退出机制,防止因重启导致消费消息丢失。
- 重构血缘关系 DAG 图展示,优化用户视觉体验同时避免大图渲染过慢问题。
- 支持血缘关系关联调度引擎工作流,解决数据血缘中最重要的「查找产出」一环。
- Hook 拓展:全新支持 Oozie、Kyuubi、Baina、ClickHouse、Kafka 等元数据采集。
- 若干原生版本代码中的 BUG 修复。
Data Collector 功能
在 BIGO 元数据平台中有个比较重要的功能——DataCollector,它是一个数据采集服务,主要功能用于定时收集并更新业务元数据(服务于上层的数据计量等应用),比如 HIVE 表每天的访问次数和访问人员、HDFS 路径的存储量、元数据的业务线归属、元数据的冷热判断、元数据的真实负责人等业务元数据。同时,DataCollector 还具备数据清理(生命周期 TTL)和同步数据接入层(Baina)元数据的功能。
图引擎替代
Atlas 原生图引擎是 JanusGraph,在使用过程中发现 Atlas Janus 有以下缺陷:第一,Atlas 依赖的内嵌 JanusGraph 图引擎存在单点问题,并发量上来后存在计算瓶颈。第二,JanusGraph 依赖 Solr 构建索引,虽然 JanusGraph 声称可用 Elasticsearch 替换 Solr,但实际操作起来却存在不少问题。此外,BIGO 内部对 Solr 不存在相关的技术累计,这需要投入一定的人力成本。第三,海量数据场景下 JanusGraph 搜索性能差,并存在偶发搜索不到数据的 BUG 难以解决。第四,JanusGraph 没有开源社区与公司内部团队支持,维护成本高。
再来说下 Nebula Graph 替换 JanusGraph 的几大优势。首先,业务同学和运维同学多方测试证明 Nebula Graph 在图探索性能上是 JanusGraph 的 N 倍以上。再者,Nebula Graph 是个分布式图数据库,支持分布式部署,计算和存储均可横向扩展,并且支持高并发。此外,Nebula Graph 开源社区活跃,产品不断迭代优化,支持千亿顶点和万亿边的数据量。最后,在 BIGO 内部有合作团队支持与维护 Nebula Graph 平台功能维护和开发。
图引擎替换的挑战&解决方案
虽然在选型上确定了用 Nebula Graph 来替换 JanusGraph,但是在实际的替换过程中还是存在一定的挑战。
首先是在数据模型上,Nebula Graph 是个强 Schema 类型数据库,如果要替换弱类型的 JanusGraph 的话,需要弱化 Tag 和 Edge 的概念。然后,在数据类型支持方面二者也有出入,原生 Nebula Graph 对 MAP、LIST 之类的复杂类型支持程度不高。再者是索引的设计问题,在 Nebula Graph 中索引功能并非起到加速作用,而是 LOOKUP 此类搜索的必备条件。此外,Nebula Graph 本身是不支持事务的,这块给我们增加了不少的工作量。最后一点,是使用习惯的转变,在查询方式上 Nebula Graph 自研查询语言 nGQL,而 JanusGraph 支持通过 Java API 和 Gremlin 进行查询。
问题出现了如何解决呢?在强弱类型转换上,BIGO 内部修改了 Atlas 的核心代码,增加参数动态判断 DDL 数据类型。简单来说,在写入数据或者执行查询时,通过特定参数来判断该条 nGQL 操作何种数据类型。在数据类型支持方面,Atlas 业务层自定义数据序列化方式来支持复杂类型。在原生索引搜索上,在系统初始化时自动创建独立索引和复合索引解决 Atlas 的搜索问题。在事务方面,在 Atlas 业务层新增半事务接口,减少 Nebula Graph 存储层数据出错的概率。
Atlas 和 Nebula Graph 的改造
这里,集中讲述在图引擎替换过程中 BIGO 对 Atlas 和 Nebula Graph 的改造。
在 Atlas 改造过程中,BIOG 新增 3w+ 行代码解藕 Atlas 和原生图引擎 JanusGraph 并支持分布式图引擎 Nebula Graph 读写。通过改造全文索引实现在 Atlas 层以 INTERSECT 方式多条件并发过滤查询,从而提升搜索速度。还将 Atlas 的多属性更新改造为并发更新,加速元数据入库的更新速度。对消费消息丢失的预处理上,BIGO 在 Atlas 层添加平滑退出机制,防止因重启导致消费消息丢失。此外,Atlas 通过支持自定义多种(反)序列化方式实现对复杂类型数据的支持。刚有提到过事务支持,在 Atlas 层新增 Vertex#openTranscation/Vertex#commit 接口支持半事务,减少由于 Nebula Graph 无事务回滚出错。最后,在 Atlas 层合并大量独立索引为复合索引,通过创建默认索引和属性优化系统初始化速度。
而 Nebula Graph 方面,BIGO 也对其进行了改造。首先是对 LOOKUP 子句的改造,让其支持并发执行,经测试扫描 100 万数据的 Latency 从 8s 降低到了 1s。此外,支持了 LOOKUP 从 Elasticsearch 查询分页功能。再者,其他部分改造工作集中在 Elasticsearch,BIGO 支持了后端 ElasticSearch 中的数据更新和删除;对 Listener 也做了 Commitsnapshot 的支持,以及全量数据的更新。对全文索引支持了 REBUILD 功能,并将 REBUILD INDEX 权限下发到 admin 用户。BIGO 还增加了单独创建和删除全文索引功能,避免所有的列写入 ElasticSearch 增加其存储使用量。最后,对 Nebula Graph 的定期 Compaction 操作也进行了优化,减少上层性能波动。
替换之后搜索性能
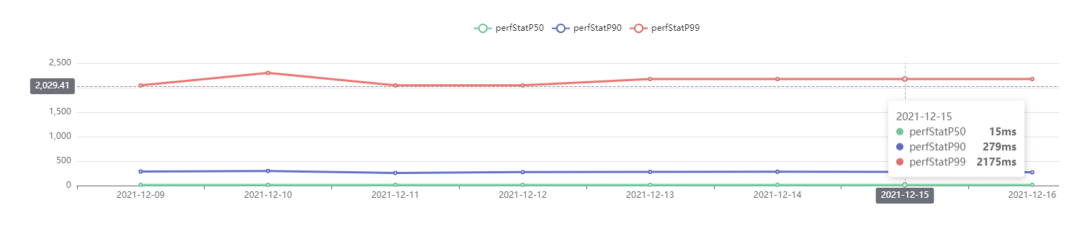
上图展示了 BIGO 用 Nebula Graph 替换 JanusGraph 之后的搜索性能。上图 P99 需要耗时 2s 多的原因是搜索总存在大搜索,会拖慢搜索速度。替换之后,搜索速度提升 5 倍以上,从原先的 5s 返回结果降低到了 1s 以内;而且再也不会出现偶尔搜索不到数据的问题,系统维护也无需额外维护索引,还支持了高并发和超大数据量存储。
数据资产平台应用
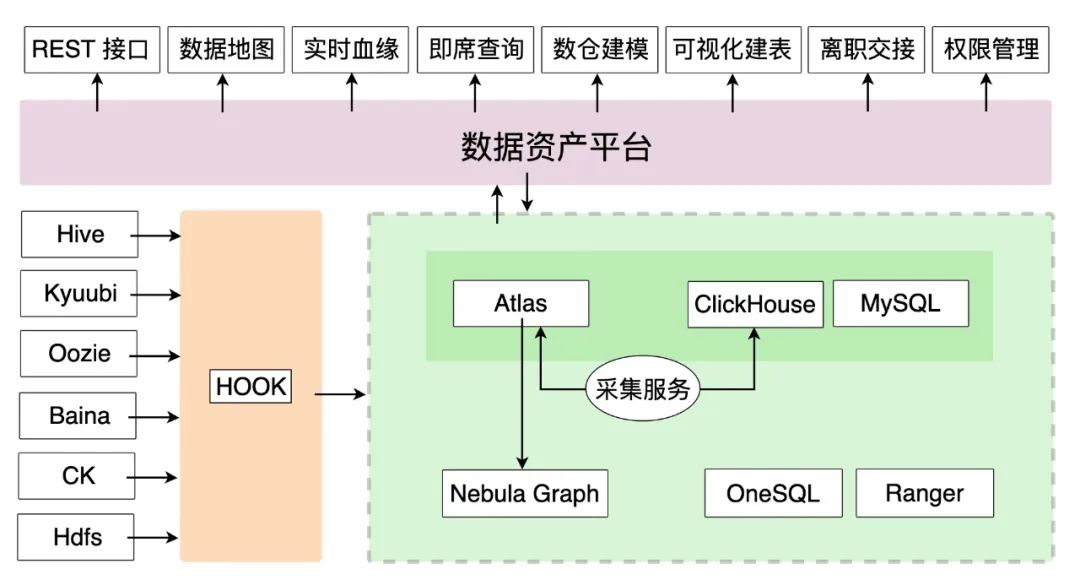
之前有分享过下层的统一元数据平台架构,这里再来详细讲解下。如上图所示,下层主要为统一元数据平台,上层则为产品应用层。左下部分为实时元数据入库模块,包括 Hive、Kyuubi、Oozie、Baina、CK(ClickHouse)、HDFS 等等数据源,经过 Hook 通过 Kafka 消息队列写入到统一元数据库平台。统一元数据库平台核心组件是 Atlas,其依赖 ClickHouse 和 Nebula Graph。此外,统一元数据平台还依赖 BIGO 内部的 OneSQL 平台,主要是统一 SQL 查询引擎,以及 Ranger 主要负责权限管控。
而数据资产平台上层则对接了应用层,包括:REST 接口、数据地图、实时血缘、即席查询、数仓建模、可视化建表、离职交接、权限管理等应用。
下面着重来介绍下相关应用。
数据地图
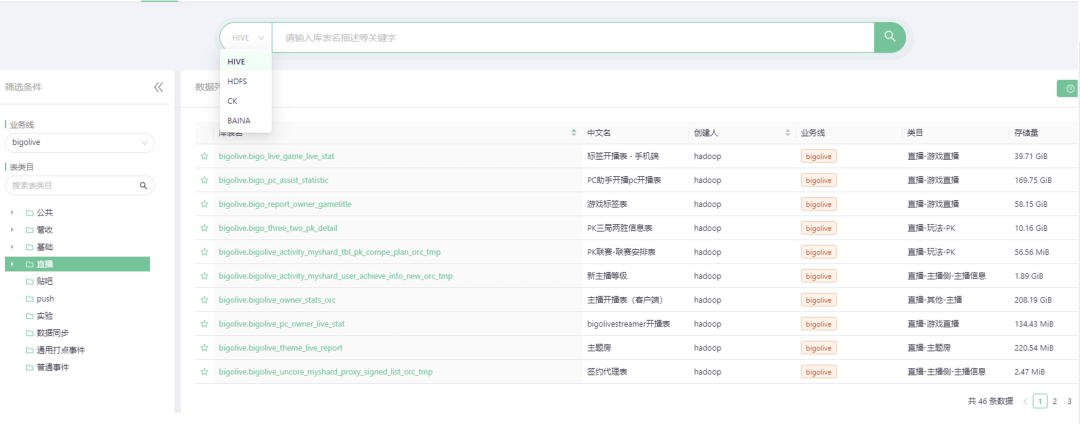
上图为数据地图-搜索(部分),支持全域元数据(HIVE、HDFS、CK、BAINA)搜索与发现(数据源还在增加中)、结果排序和下载、支持筛选、支持高级搜索等功能。在搜索界面,左侧为筛选条件,顶部为搜索框入口,下方为搜索结果展示数据。
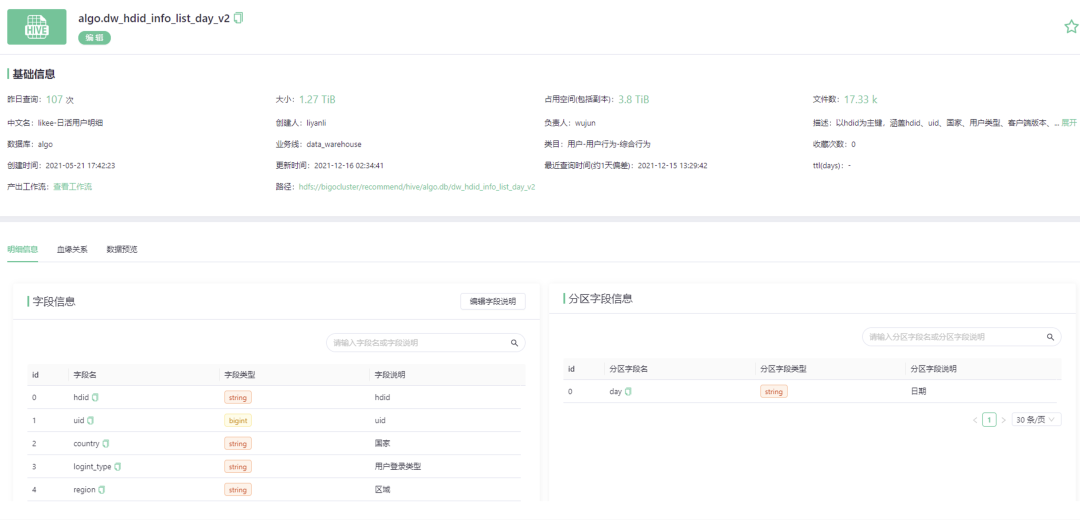
上图为数据地图-详情(部分),通过搜索找到特定的元数据之后,可点击查看技术明细、数据计量、业务归属、生命周期、历史趋势等元数据基础信息。在详情界面,以上图 HIVE 元数据的详情为例,主要分为上方的基本信息和下方的明细信息、血缘关系、数据预览展示。
基本信息罗列了昨日查询次数 107 次,数据大小 1.27 TiB,占用空间为 3.8 TiB…此外,通过【编辑】操作可对数据生命周期、业务线进行管理。
明细信息(下方左侧)罗列字段信息:HIVE 表的字段、字段类型、字段相关描述,供产品、运营使用。下方右侧为分区字段信息,如果某个数据是分区表的话,该模块会展示分区字段的信息;如果是个全量表的话,则不会展示分区字段信息。此外,数据血缘关系、数据预览功能这里不作详细介绍。
实时血缘
在实时血缘模块,BIGO 重构了有向无环图 DAG 图,新增数据表格展示,实现了数据懒加载、关联和搜索工作流,在业务层的血缘关系图里实时地展示工作流的执行状态。
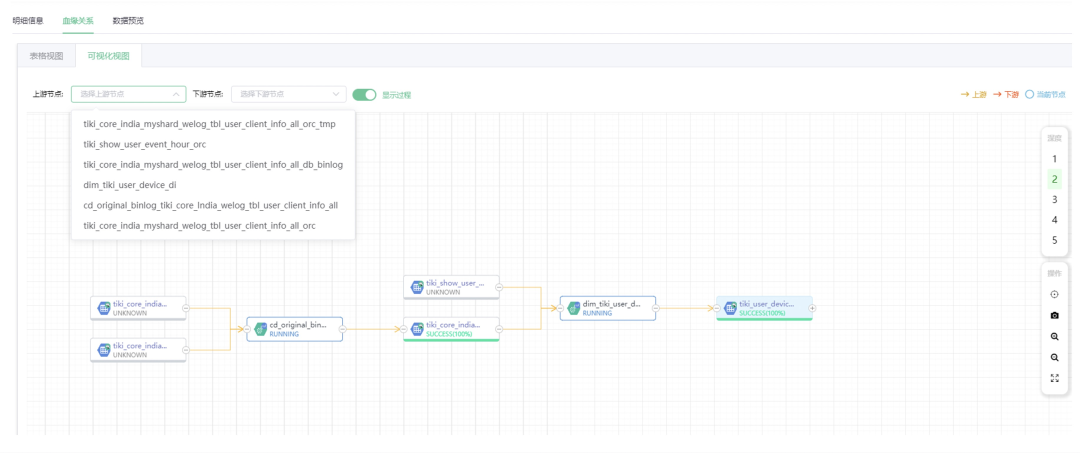
血缘模块支持图表和可视化两类视图,上图选择了可视化视图模式。可视化视图部分可在上、下游节点中选择对应节点,配有【显示过程】按钮用来显示或者隐藏过程工作流。举个例子,a 表和 b 表,b 表是由 a 表通过一个工作流生成,打开【显示过程】按钮则会展示该生成过程,关闭【显示过程】则会屏蔽这个过程数据。

上图为数据血缘核心模块,展示了某个元数据的上下游。左侧浮动深度和过滤选项,可选择以某个元数据为中心的上下游层数(深度),比如,上图就选择了 tiki_core_india… 数据的 2 层上游和下游节点。
数据治理
数据治理这块,主要展示 TTL 管理,用于管理通用打点表各个事件的生命周期。
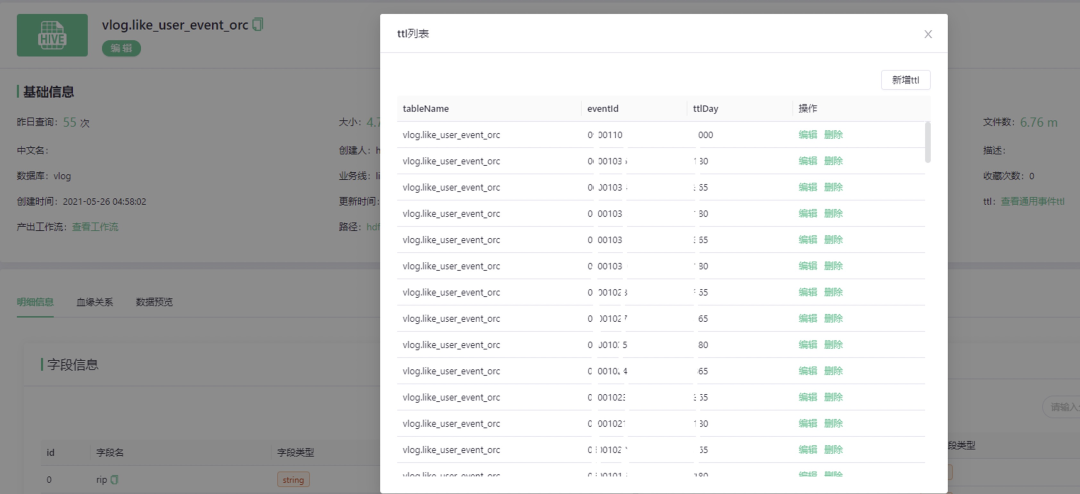
上图为数据治理 TTL 管理部分截图,从上文提到的数据地图详情部分点击【编辑】按钮即可对数据进行 TTL 生命周期管理。当然,BIGO 数据治理除了生命周期管理之外,还有别的功能这里不做详细介绍。
数据建模
在数据建模方面,元数据统一平台提供 SQL 脚本方式用来创建表模型,供数仓开发者和数据分析师交互使用。

图注:一条 SQL 模型数据
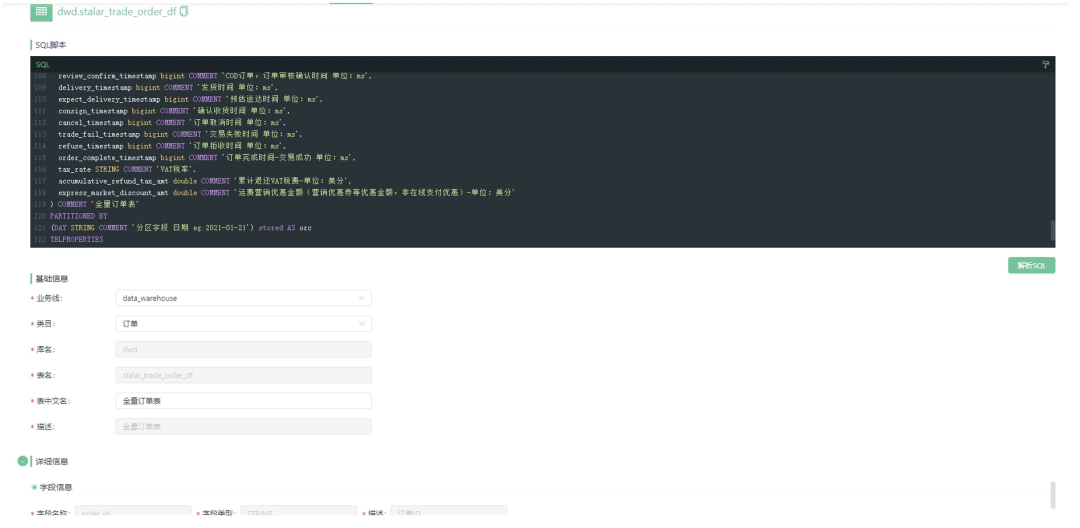
图注:数据建模入口
监控大盘
BIGO 内部的监控大盘实时展示公司数据,包括资源总量、各业务线资源占比、变化趋势和热门资源等,从而推动团队、业务线进行成本优化。
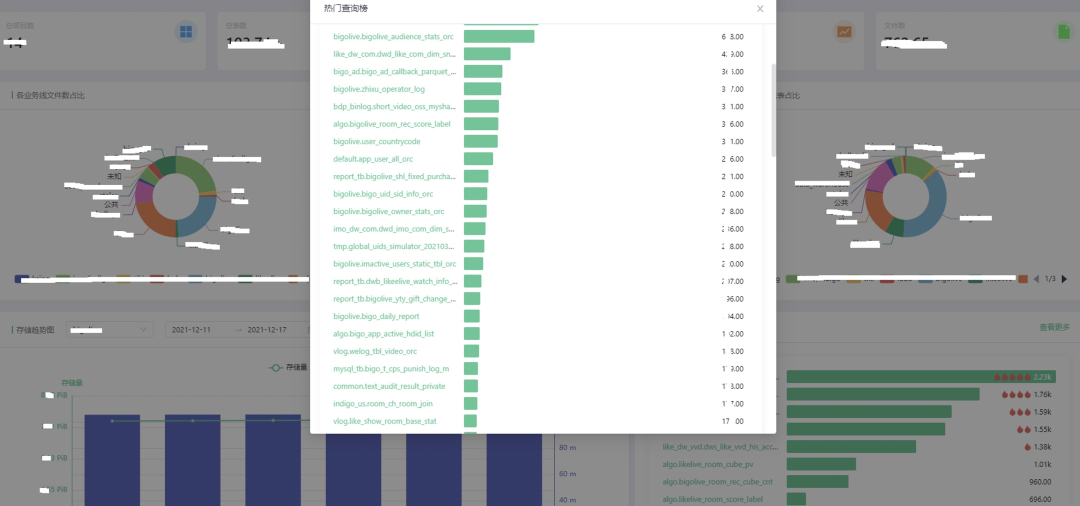
图注:脱敏的大盘截图
除了上述的应用之外,数据资产管理平台还有模板取数、权限管理、离职交接、群组管理、数据预览,以及收藏下载等应用。
Adhoc 即席查询
业务背景
BIGO 原来使用 Cloudera HUE 作为即席查询平台,但由于多种原因,HUE 早已无法适配内部查询需求,经常被用户投诉难用且不稳定。主要原因有:
- 代码陈旧,基本处于被开源放弃状态;
- BIGO 历史原因经历至少六位员工接手 HUE,堆积大量内部代码;
- HUE 运维非常繁琐;
- 编辑窗口不符合用户实际需求;
- BIGO 已内部建设统一 SQL 路由器,无需让用户选择执行引擎。
基于上述原因,决定自研一套全新 SQL 查询平台,解决上述问题,统一元数据管理和数据查询到资产管理平台,并加入以下特性:第一点,建设统一 SQL 路由器(onesql),根据语法规则自动路由 SQL 到后端 sparksql/hive/presto/flinksql 引擎执行;第二点,提供全新查询入口给用户执行 SQL,并规范化 DDL 语句,为数据治理、权限管理及成本控制提供便利;第三点,根据产品调研设计全新多 TAG 交互操作的编辑窗口;第四点,提供通过 SQL 建表 / LOAD 数据或通过可视化建表 / LOAD 数据的功能;第五点,自动兼容 pad / phone 等移动设备端查询,方便国内外同事使用;第六点,增加日常用户访问审计 / 全面监控告警;最后一点,支持在统一入口查询 ClickHouse 数据(规划中)。
未来展望
数据平台未来规划的话,主要围绕:元数据建设、产品增加、业务赋能三方面。
在元数据建设方面,将会覆盖接入层、计算层、调度层、存储层所有平台的元数据。此外,我们还在规划计算资源治理以及一站式任务开发(Python / Jar / Shell / SQL)等。
在产品增强方面主要分为治理、成本、效率、应用四块内容,在治理方面,加强数据治理能力,自动治理不健康的数据;在成本方面,帮助公司各团队实现成本分析闭环,为成本优化提供工具;在效率方面,通过规范建表、精准计量、查询优化、血缘建设等提升用户工作效率;在应用方面,进一步完善集成即席查询和分布式调度系统功能,增强用户使用体验。
在业务赋能方面,将会进行智能归因诊断,赋能业务团队自动分析问题能力。此外,还会迭代优化模板取数,赋能业务团队简单挖掘更多数据价值。
以上,为本次 BIGO 数据平台实践分享。