大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
以下是正文!
先看问题
首先上一串代码
public String buy(Long goodsId, Integer goodsNum) {
//查询商品库存
Goods goods = goodsMapper.selectById(goodsId);
//如果当前库存为0,提示商品已经卖光了
if (goods.getGoodsInventory() <= 0) {
return "商品已经卖光了!";
}
//如果当前购买数量大于库存,提示库存不足
if (goodsNum > goods.getGoodsInventory()) {
return "库存不足!";
}
//更新库存
goods.setGoodsInventory(goods.getGoodsInventory() - goodsNum);
goodsMapper.updateById(goods);
return "购买成功!";
}
我们看一下这串代码,逻辑用流程图表示如下:
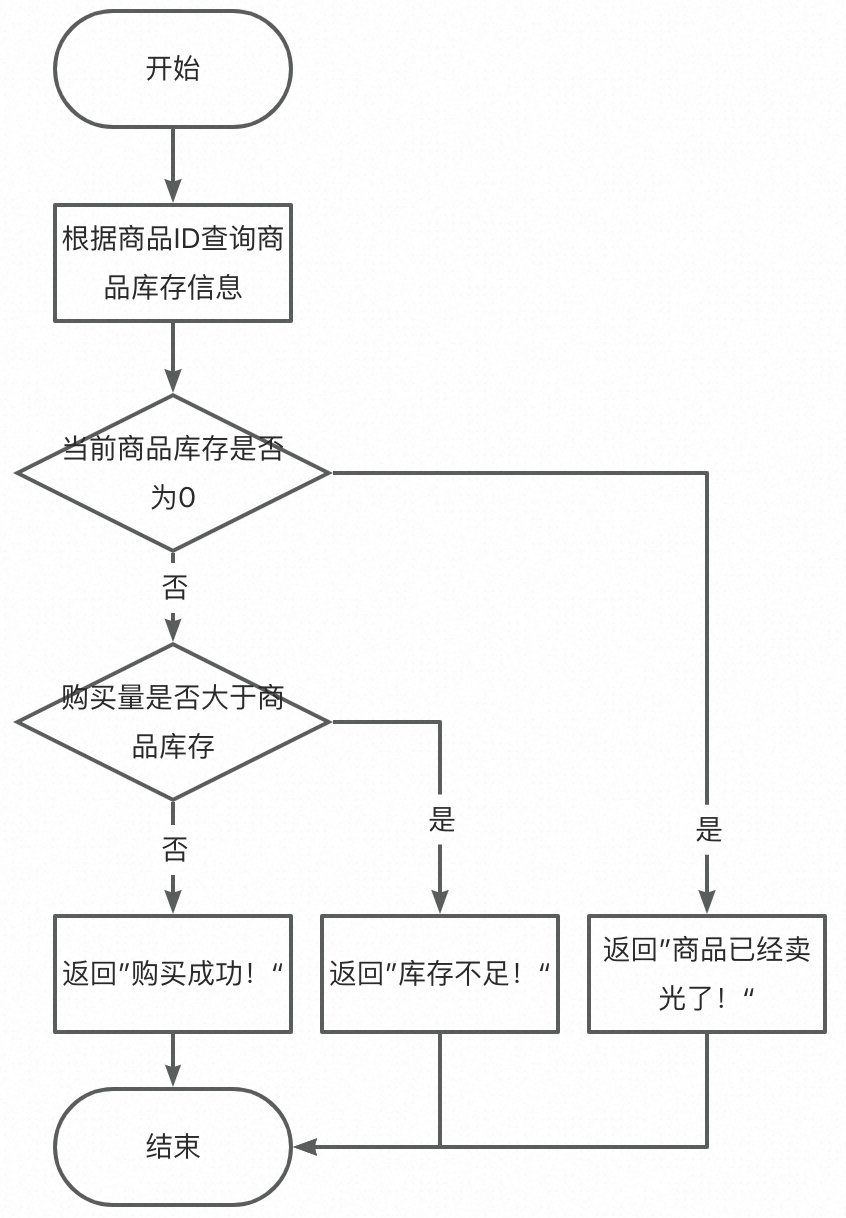 从图上看,逻辑还是很清晰明了的,而且单测的话,也测试不出来什么bug。但是在秒杀场景下,问题可就大发了,100件商品可能卖出1000单,出现超卖问题,这下就真的需要杀个程序员祭天了。
从图上看,逻辑还是很清晰明了的,而且单测的话,也测试不出来什么bug。但是在秒杀场景下,问题可就大发了,100件商品可能卖出1000单,出现超卖问题,这下就真的需要杀个程序员祭天了。
问题分析
正常情况下,如果请求是一个一个接着来的话,这串代码也不会有问题,如下图:
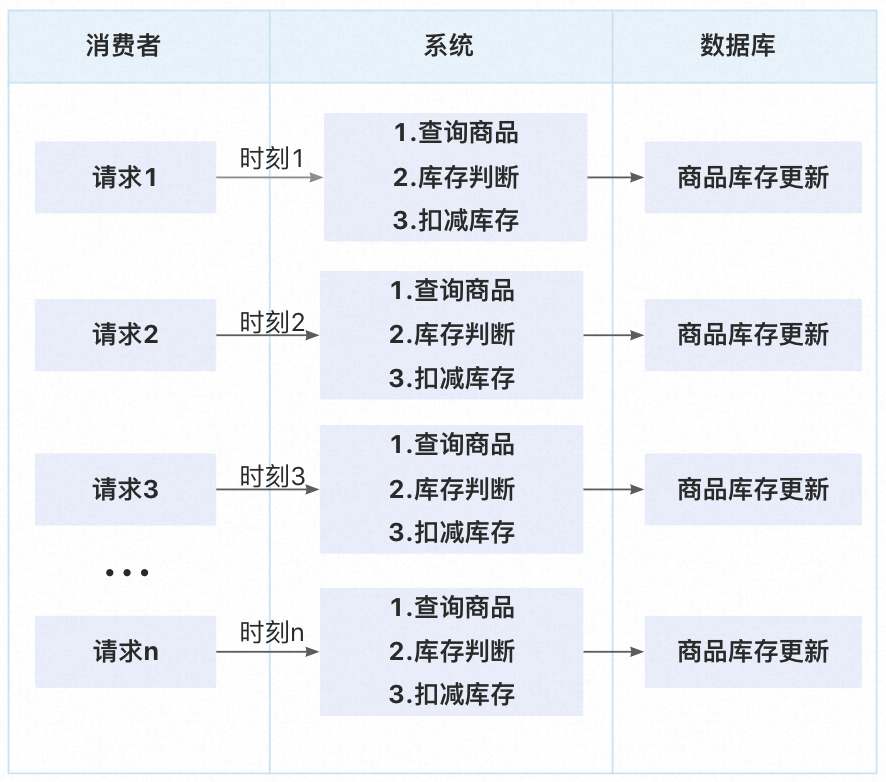
不同的时刻不同的请求,每次拿到的商品库存都是更新过之后的,逻辑是ok的。
那为啥会出现超卖问题呢? 首先我们给这串代码增加一个场景:商品秒杀(非秒杀场景难以复现超卖问题)。 秒杀场景的特点如下:
- 高并发处理:秒杀场景下,可能会有大量的购物者同时涌入系统,因此需要具备高并发处理能力,保证系统能够承受高并发访问,并提供快速的响应。
- 快速响应:秒杀场景下,由于时间限制和竞争激烈,需要系统能够快速响应购物者的请求,否则可能会导致购买失败,影响购物者的购物体验。
- 分布式系统: 秒杀场景下,单台服务器扛不住请求高峰,分布式系统可以提高系统的容错能力和抗压能力,非常适合秒杀场景。
在这种场景下,请求不可能是一个接一个这种,而是成千上万个请求同时打过来,那么就会出现多个请求在同一时刻查询库存,如下图:
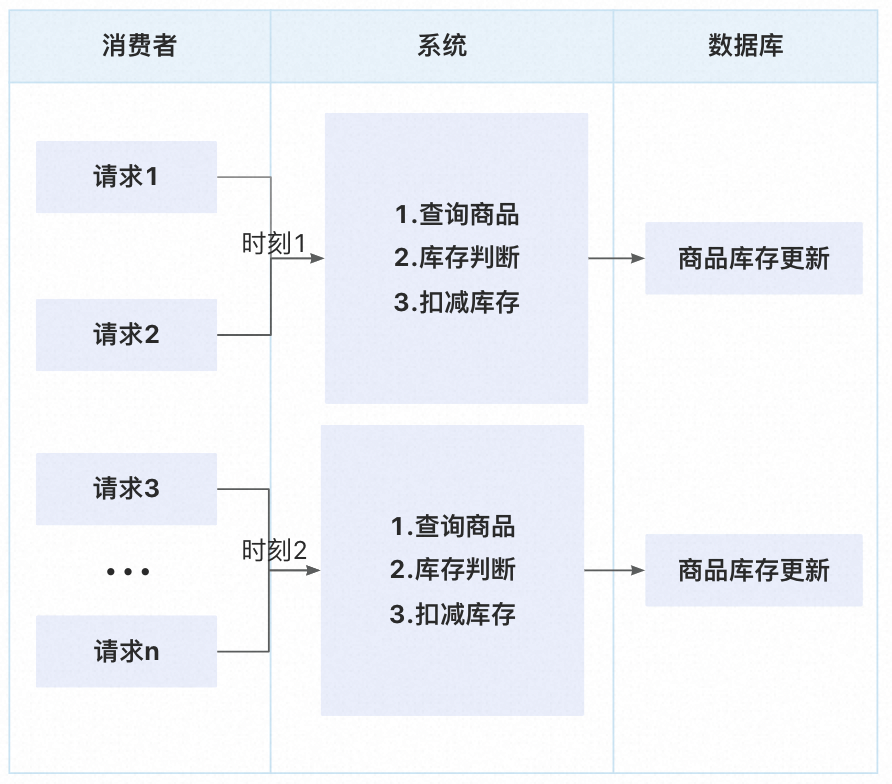
如果在同一时刻查询商品库存表,那么得到的商品库存也肯定是相同的,判断的逻辑也是相同的。
举个例子,现在商品的库存是10件,请求1买6件,请求2买5件,由于两次请求查询到的库存都是10,肯定是可以卖的。 但是真实情况是5+6=11>10,明显有问题好吧!这两笔请求必然有一笔失败才是对的!
那么,这种问题怎么解决呢?
问题解决
从上面例子来看,问题好像是由于我们每次拿到的库存都是一样的,才导致库存超卖问题,那是不是只要保证每次拿到的库存都是最新的话,这个问题不就迎刃而解了吗!
在说方案前,先把我的测试表结构贴出来:
CREATE TABLE `t_goods` (
`id` bigint NOT NULL COMMENT '物理主键',
`goods_name` varchar(64) DEFAULT NULL COMMENT '商品名称',
`goods_pic` varchar(255) DEFAULT NULL COMMENT '商品图片',
`goods_desc` varchar(255) DEFAULT NULL COMMENT '商品描述信息',
`goods_inventory` int DEFAULT NULL COMMENT '商品库存',
`goods_price` decimal(10,2) DEFAULT NULL COMMENT '商品价格',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
方法一、redis分布式锁
Redisson介绍
官方介绍:Redisson是一个基于Redis的Java驻留内存数据网格(In-Memory Data Grid)。它封装了Redis客户端API,并提供了一个分布式锁、分布式集合、分布式对象、分布式Map等常用的数据结构和服务。Redisson支持Java 6以上版本和Redis 2.6以上版本,并且采用编解码器和序列化器来支持任何对象类型。 Redisson还提供了一些高级功能,比如异步API和响应式流式API。它可以在分布式系统中被用来实现高可用性、高性能、高可扩展性的数据处理。
Redisson使用
引入
<!--使用redisson作为分布式锁-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.8</version>
</dependency>
注入对象
RedissonConfig.java
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
/**
* 所有对Redisson的使用都是通过RedissonClient对象
*
* @return
*/
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient() {
// 创建配置 指定redis地址及节点信息
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("123456");
// 根据config创建出RedissonClient实例
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}
代码优化
public String buyRedisLock(Long goodsId, Integer goodsNum) {
RLock lock = redissonClient.getLock("goods_buy");
try {
//加分布式锁
lock.lock();
//查询商品库存
Goods goods = goodsMapper.selectById(goodsId);
//如果当前库存为0,提示商品已经卖光了
if (goods.getGoodsInventory() <= 0) {
return "商品已经卖光了!";
}
//如果当前购买数量大于库存,提示库存不足
if (goodsNum > goods.getGoodsInventory()) {
return "库存不足!";
}
//更新库存
goods.setGoodsInventory(goods.getGoodsInventory() - goodsNum);
goodsMapper.updateById(goods);
return "购买成功!";
} catch (Exception e) {
log.error("秒杀失败");
} finally {
lock.unlock();
}
return "购买失败";
}
加上Redisson分布式锁之后,使得请求由异步变为同步,让购买操作一个一个进行,解决了库存超卖问题,但是会让用户等待的时间加长,影响了用户体验。
方法二、MySQL的行锁
行锁介绍
那么回到库存超卖这个问题上来,我们可以在一开始查询商品库存的时候增加一个行锁,实现非常简单,也就是将
//查询商品库存
Goods goods = goodsMapper.selectById(goodsId);
原始查询SQL
SELECT *
FROM t_goods
WHERE id = #{goodsId}
改写为
SELECT *
FROM t_goods
WHERE id = #{goodsId} for update
那么被查询到的这行商品库存信息就会被锁住,其他请求想要读取这行数据时就需要等待当前请求结束了,这样就做到了每次查询库存都是最新的。不过同Redisson分布式锁一样,会让用户等待的时间加长,影响用户体验。
方法三、乐观锁
乐观锁机制类似java中的cas机制,在查询数据的时候不加锁,只有更新数据的时候才比对数据是否已经发生过改变,没有改变则执行更新操作,已经改变了则进行重试。
商品表增加version字段并初始化数据为0
`version` int(11) DEFAULT NULL COMMENT '版本'
将更新SQL修改如下
update t_goods
set goods_inventory = goods_inventory - #{goodsNum},
version = version + 1
where id = #{goodsId}
and version = #{version}
Java代码修改如下
public String buyVersion(Long goodsId, Integer goodsNum) {
//查询商品库存(该语句使用了行锁)
Goods goods = goodsMapper.selectById(goodsId);
//如果当前库存为0,提示商品已经卖光了
if (goods.getGoodsInventory() <= 0) {
return "商品已经卖光了!";
}
if (goodsMapper.updateInventoryAndVersion(goodsId, goodsNum, goods.getVersion()) > 0) {
return "购买成功!";
}
return "库存不足!";
}
通过增加了版本号的控制,在扣减库存的时候在where条件进行版本号的比对。实现查询的是哪一条记录,那么就要求更新的是哪一条记录,在查询到更新的过程中版本号不能变动,否则更新失败。
方法四、where条件和unsigned 非负字段限制
前面的两种办法是通过每次都拿到最新的库存从而解决超卖问题,那换一种思路:保证在扣除库存的时候,库存一定大于购买量是不是也可以解决这个问题呢?
答案是可以的。回到上面的代码:
//更新库存
goods.setGoodsInventory(goods.getGoodsInventory() - goodsNum);
goodsMapper.updateById(goods);
我们把库存的扣减写在了代码中,这样肯定是不行的,因为在分布式系统中我们获取到的库存可能都是一样的,应该把库存的扣减逻辑放到SQL中,即:
update t_goods
set goods_inventory = goods_inventory - #{goodsNum}
where id = #{goodsId}
上面的SQL保证了每次获取的库存都是取数据库的库存,不过我们还需要加一个判断:保证库存大于购买量,即:
update t_goods
set goods_inventory = goods_inventory - #{goodsNum}
where id = #{goodsId}
AND (goods_inventory - #{goodsNum}) >= 0
那么上面那段Java代码也需修改一下:
public String buySqlUpdate(Long goodsId, Integer goodsNum) {
//查询商品库存(该语句使用了行锁)
Goods goods = goodsMapper.queryById(goodsId);
//如果当前库存为0,提示商品已经卖光了
if (goods.getGoodsInventory() <= 0) {
return "商品已经卖光了!";
}
//此处需要判断更新操作是否成功
if (goodsMapper.updateInventory(goodsId, goodsNum) > 0) {
return "购买成功!";
}
return "库存不足!";
}
还有一种办法和where条件一样,就是unsigned 非负字段限制,把库存字段设置为unsigned 非负字段类型,那么在扣减时也不会出现扣成负数的情况。
总结一下
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| redis分布式锁 | Redis分布式锁可以解决分布式场景下的锁问题,保证多个节点对同一资源的访问顺序和安全性,性能较高。 | 单点故障问题,如果Redis节点宕机,会导致锁失效。 |
| MySQL的行锁 | 可以保证事务的隔离性,能够避免并发情况下的数据冲突问题。 | 性能较低,对数据库的性能影响较大,同时也存在死锁问题。 |
| 乐观锁 | 相对于悲观锁,乐观锁不会阻塞线程,性能较高。 | 需要额外的版本控制字段,且在高并发情况下容易出现并发冲突问题。 |
| where条件和unsigned 非负字段限制 | 可以通过where条件和unsigned非负字段限制来保证库存不会超卖,简单易实现。 | 可能存在一定的安全隐患,如果某些操作没有正确限制,仍有可能导致库存超卖问题。同时,如果某些场景需要对库存进行多次更新操作,限制条件可能会导致操作失败,需要再次查询数据,对性能会产生影响。 |
方案有很多,用法结合实际业务来看,没有最优,只有更优。
全文至此结束,再会!