- TCP/IP网络编程
 PDF电子书集合
PDF电子书集合
套接字的多种可选项详解
第 9 章 套接字的多种可选项
本章代码,在TCP-IP-NetworkNote中可以找到。
9.1 套接字可选项和 I/O 缓冲大小
我们进行套接字编程时往往只关注数据通信,而忽略了套接字具有的不同特性。但是,理解这些特性并根据实际需要进行更改也很重要
9.1.1 套接字多种可选项
我们之前写得程序都是创建好套接字之后直接使用的,此时通过默认的套接字特性进行数据通信,这里列出了一些套接字可选项。
| 协议层 | 选项名 | 读取 | 设置 |
|---|---|---|---|
| SOL_SOCKET | SO_SNDBUF | O | O |
| SOL_SOCKET | SO_RCVBUF | O | O |
| SOL_SOCKET | SO_REUSEADDR | O | O |
| SOL_SOCKET | SO_KEEPALIVE | O | O |
| SOL_SOCKET | SO_BROADCAST | O | O |
| SOL_SOCKET | SO_DONTROUTE | O | O |
| SOL_SOCKET | SO_OOBINLINE | O | O |
| SOL_SOCKET | SO_ERROR | O | X |
| SOL_SOCKET | SO_TYPE | O | X |
| IPPROTO_IP | IP_TOS | O | O |
| IPPROTO_IP | IP_TTL | O | O |
| IPPROTO_IP | IP_MULTICAST_TTL | O | O |
| IPPROTO_IP | IP_MULTICAST_LOOP | O | O |
| IPPROTO_IP | IP_MULTICAST_IF | O | O |
| IPPROTO_TCP | TCP_KEEPALIVE | O | O |
| IPPROTO_TCP | TCP_NODELAY | O | O |
| IPPROTO_TCP | TCP_MAXSEG | O | O |
从表中可以看出,套接字可选项是分层的。
9.1.2 getsockopt & setsockopt
可选项的读取和设置通过以下两个函数来完成
#include <sys/socket.h>
int getsockopt(int sock, int level, int optname, void *optval, socklen_t *optlen);
/*
成功时返回 0 ,失败时返回 -1
sock: 用于查看选项套接字文件描述符
level: 要查看的可选项协议层
optname: 要查看的可选项名
optval: 保存查看结果的缓冲地址值
optlen: 向第四个参数传递的缓冲大小。调用函数候,该变量中保存通过第四个参数返回的可选项信息的字节数。
*/上述函数可以用来读取套接字可选项,下面的函数可以更改可选项:d
#include <sys/socket.h>
int setsockopt(int sock, int level, int optname, const void *optval, socklen_t optlen);
/*
成功时返回 0 ,失败时返回 -1
sock: 用于更改选项套接字文件描述符
level: 要更改的可选项协议层
optname: 要更改的可选项名
optval: 保存更改结果的缓冲地址值
optlen: 向第四个参数传递的缓冲大小。调用函数候,该变量中保存通过第四个参数返回的可选项信息的字节数。
*/下面的代码可以看出 getsockopt 的使用方法。下面示例用协议层为 SOL_SOCKET 、名为 SO_TYPE 的可选项查看套接字类型(TCP 和 UDP )。
编译运行:
gcc sock_type.c -o sock_type
./sock_type结果:
SOCK_STREAM: 1
SOCK_DGRAM: 2
Socket type one: 1
Socket type two: 2首先创建了一个 TCP 套接字和一个 UDP 套接字。然后通过调用 getsockopt 函数来获得当前套接字的状态。
验证套接类型的 SO_TYPE 是只读可选项,因为套接字类型只能在创建时决定,以后不能再更改。
9.1.3 SO_SNDBUF & SO_RCVBUF
创建套接字的同时会生成 I/O 缓冲。关于 I/O 缓冲,可以去看第五章。
SO_RCVBUF 是输入缓冲大小相关可选项,SO_SNDBUF 是输出缓冲大小相关可选项。用这 2 个可选项既可以读取当前 I/O 大小,也可以进行更改。通过下列示例读取创建套接字时默认的 I/O 缓冲大小。
编译运行:
gcc get_buf.c -o getbuf
./getbuf运行结果:
Input buffer size: 87380
Output buffer size: 16384可以看出本机的输入缓冲和输出缓冲大小。
下面的代码演示了,通过程序设置 I/O 缓冲区的大小
编译运行:
gcc get_buf.c -o setbuf
./setbuf结果:
Input buffer size: 6144
Output buffer size: 6144输出结果和我们预想的不是很相同,缓冲大小的设置需谨慎处理,因此不会完全按照我们的要求进行。
9.2 SO_REUSEADDR
9.2.1 发生地址分配错误(Binding Error)
在学习 SO_REUSEADDR 可选项之前,应该好好理解 Time-wait 状态。看以下代码的示例:
这是一个回声服务器的服务端代码,可以配合第四章的 echo_client.c 使用,在这个代码中,客户端通知服务器终止程序。在客户端控制台输入 Q 可以结束程序,向服务器发送 FIN 消息并经过四次握手过程。当然,输入 CTRL+C 也会向服务器传递 FIN 信息。强制终止程序时,由操作系统关闭文件套接字,此过程相当于调用 close 函数,也会向服务器发送 FIN 消息。
这样看不到是什么特殊现象,考虑以下情况:
服务器端和客户端都已经建立连接的状态下,向服务器控制台输入 CTRL+C ,强制关闭服务端
如果用这种方式终止程序,如果用同一端口号再次运行服务端,就会输出「bind() error」消息,并且无法再次运行。但是在这种情况下,再过大约 3 分钟就可以重新运行服务端。
9.2.2 Time-wait 状态
观察以下过程:
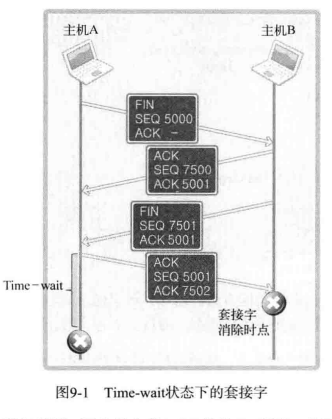
假设图中主机 A 是服务器,因为是主机 A 向 B 发送 FIN 消息,故可想象成服务器端在控制台中输入 CTRL+C 。但是问题是,套接字经过四次握手后并没有立即消除,而是要经过一段时间的 Time-wait 状态。当然,只有先断开连接的(先发送 FIN 消息的)主机才经过 Time-wait 状态。因此,若服务器端先断开连接,则无法立即重新运行。套接字处在 Time-wait 过程时,相应端口是正在使用的状态。因此,就像之前验证过的,bind 函数调用过程中会发生错误。
实际上,不论是服务端还是客户端,都要经过一段时间的 Time-wait 过程。先断开连接的套接字必然会经过 Time-wait 过程,但是由于客户端套接字的端口是任意制定的,所以无需过多关注 Time-wait 状态。
那到底为什么会有 Time-wait 状态呢,在图中假设,主机 A 向主机 B 传输 ACK 消息(SEQ 5001 , ACK 7502 )后立刻消除套接字。但是最后这条 ACK 消息在传递过程中丢失,没有传递主机 B ,这时主机 B 就会试图重传。但是此时主机 A 已经是完全终止状态,因为主机 B 永远无法收到从主机 A 最后传来的 ACK 消息。基于这些问题的考虑,所以要设计 Time-wait 状态。
9.2.3 地址再分配
Time-wait 状态看似重要,但是不一定讨人喜欢。如果系统发生故障紧急停止,这时需要尽快重启服务起以提供服务,但因处于 Time-wait 状态而必须等待几分钟。因此,Time-wait 并非只有优点,这些情况下容易引发大问题。下图中展示了四次握手时不得不延长 Time-wait 过程的情况。
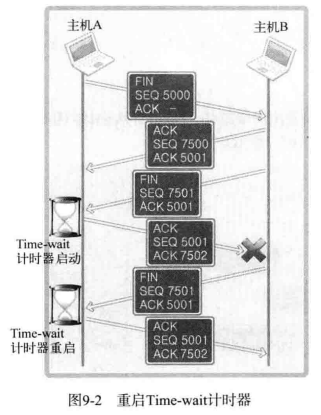
从图上可以看出,在主机 A 四次握手的过程中,如果最后的数据丢失,则主机 B 会认为主机 A 未能收到自己发送的 FIN 信息,因此重传。这时,收到的 FIN 消息的主机 A 将重启 Time-wait 计时器。因此,如果网络状况不理想, Time-wait 将持续。
解决方案就是在套接字的可选项中更改 SO_REUSEADDR 的状态。适当调整该参数,可将 Time-wait 状态下的套接字端口号重新分配给新的套接字。SO_REUSEADDR 的默认值为 0.这就意味着无法分配 Time-wait 状态下的套接字端口号。因此需要将这个值改成 1 。具体作法已在示例 reuseadr_eserver.c 给出,只需要把注释掉的东西接解除注释即可。
optlen = sizeof(option);
option = TRUE;
setsockopt(serv_sock, SOL_SOCKET, SO_REUSEADDR, (void *)&option, optlen);此时,已经解决了上述问题。
9.3 TCP_NODELAY
9.3.1 Nagle 算法
为了防止因数据包过多而发生网络过载,Nagle 算法诞生了。它应用于 TCP 层。它是否使用会导致如图所示的差异:
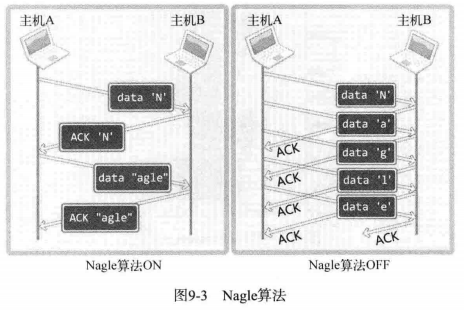
图中展示了通过 Nagle 算法发送字符串 Nagle 和未使用 Nagle 算法的差别。可以得到一个结论。
只有接收到前一数据的 ACK 消息, Nagle 算法才发送下一数据。
TCP 套接字默认使用 Nagle 算法交换数据,因此最大限度的进行缓冲,直到收到 ACK 。左图也就是说一共传递 4 个数据包以传输一个字符串。从右图可以看出,发送数据包一共使用了 10 个数据包。由此可知,不使用 Nagle 算法将对网络流量产生负面影响。即使只传输一个字节的数据,其头信息都可能是几十个字节。因此,为了提高网络传输效率,必须使用 Nagle 算法。
Nagle 算法并不是什么情况下都适用,网络流量未受太大影响时,不使用 Nagle 算法要比使用它时传输速度快。最典型的就是「传输大文数据」。将文件数据传入输出缓冲不会花太多时间,因此,不使用 Nagle 算法,也会在装满输出缓冲时传输数据包。这不仅不会增加数据包的数量,反而在无需等待 ACK 的前提下连续传输,因此可以大大提高传输速度。
所以,未准确判断数据性质时不应禁用 Nagle 算法。
9.3.2 禁用 Nagle 算法
禁用 Nagle 算法应该使用:
int opt_val = 1;
setsockopt(sock, IPPROTO_TCP, TCP_NODELAY, (void *)&opt_val, sizeof(opt_val));通过 TCP_NODELAY 的值来查看Nagle 算法的设置状态。
opt_len = sizeof(opt_val);
getsockopt(sock, IPPROTO_TCP, TCP_NODELAY, (void *)&opt_val, opt_len);如果正在使用Nagle 算法,那么 opt_val 值为 0,如果禁用则为 1.
关于这个算法,可以参考这个回答:TCP连接中启用和禁用TCP_NODELAY有什么影响?
9.4 基于 Windows 的实现
暂略
9.5 习题
以下答案仅代表本人个人观点,可能不是正确答案。
-
下列关于 Time-wait 状态的说法错误的是?
答:以下字体加粗的代表正确。
- Time-wait 状态只在服务器的套接字中发生
- 断开连接的四次握手过程中,先传输 FIN 消息的套接字将进入 Time-wait 状态。
- Time-wait 状态与断开连接的过程无关,而与请求连接过程中 SYN 消息的传输顺序有关
- Time-wait 状态通常并非必要,应尽可能通过更改套接字可选项来防止其发生
-
TCP_NODELAY 可选项与 Nagle 算法有关,可通过它禁用 Nagle 算法。请问何时应考虑禁用 Nagle 算法?结合收发数据的特性给出说明。
答:当网络流量未受太大影响时,不使用 Nagle 算法要比使用它时传输速度快,比如说在传输大文件时。