- Python Web 渗透测试
- Python Web 渗透秘籍
- Python 高效渗透测试
 PDF电子书集合
PDF电子书集合
Python 使用 Scapy 分析网络流量详解
流量分析是截取和分析网络流量以从通信中推断信息的过程。两台主机之间交换的数据包大小、通信系统的详细信息、通信时间和持续时间对攻击者来说是一些有价值的信息。在本章中,我们将学习如何使用 Python 脚本分析网络流量:
网络套接字是使用标准 Unix 文件描述符与其他计算机通信的一种方式,它允许在同一台或不同机器上的两个不同进程之间进行通信。套接字几乎类似于低级文件描述符,因为像read()和write()这样的命令也可以像处理文件一样处理套接字。
Python 有两个基本套接字模块:
-
套接字:标准 BSD 套接字 API。
-
SocketServer:一个以服务器为中心的模块,定义用于处理同步网络请求的类,从而简化网络服务器的开发。
插座
socket模块几乎拥有构建套接字服务器或客户端所需的一切。对于 Python,socket返回一个可以应用套接字方法的对象。
插座模块中的方法
套接字模块具有以下类方法:
-
socket.socket(family, type):创建并返回一个新的套接字对象 -
socket.getfqdn(name):将字符串 IP 地址转换为完全限定的域名 -
socket.gethostbyname(hostname):将主机名解析为 IP 地址
实例方法需要从socket返回一个套接字实例。socket模块有以下实例方法:
-
sock.bind( (address, port) ):将套接字绑定到地址和端口 -
sock.accept():返回带有对等地址信息的客户端套接字 -
sock.listen(backlog):将插座置于监听状态 -
sock.connect( (address, port) ):将套接字连接到定义的主机和端口 -
sock.recv( bufferLength[, flags] ):从套接字接收数据,最多为buflen(接收的最大字节数)字节 -
sock.recvfrom( bufferLength[, flags] ):从套接字接收数据,最多为buflen字节,同时返回数据来自的远程主机和端口 -
sock.send( data[, flags] ):通过套接字发送数据 -
sock.sendall( data[, flags] ):通过套接字发送数据,并继续发送数据,直到发送完所有数据或出现错误 -
sock.close():关闭插座 -
sock.getsockopt( lvl, optname ):获取指定套接字选项的值 -
sock.setsockopt( lvl, optname, val ):设置指定套接字选项的值
创建套接字
可以通过调用socket模块中的类方法socket()来创建套接字。这将返回指定域中的套接字。该方法的参数如下所示:
-
Address family: Python supports three address families.
- AF_INET:用于 IP 版本 4 或 IPv4 互联网寻址。
- AF_INET6:用于 IPv6 互联网寻址。
- AF_UNIX:用于UNIX 域套接字(UDS)。
-
套接字类型:通常情况下,套接字类型可以是用户数据报协议(UDP)的
SOCK_DGRAM或传输控制协议(TCP的SOCK_STREAM。SOCK_RAW用于创建原始套接字。 -
协议:一般保留默认值。默认值为 0。
以下是创建套接字的示例:
import socket #Imported sockets module
import sys
try:
#Create an AF_INET (IPv4), STREAM socket (TCP)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error, e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
print 'Success!'
连接到服务器并发送数据
创建的套接字可用于服务器端或客户端。
socket 对象的connect()方法用于将客户端连接到主机。此实例方法接受主机名或元组,其中包含主机名/地址和端口号作为参数。
我们可以重写前面的代码,向服务器发送消息,如下所示:
import socket #Imported sockets module
import sys
TCP_IP = '127.0.0.1'
TCP_PORT = 8090 #Reserve a port
BUFFER_SIZE = 1024
MESSAGE_TO_SERVER = "Hello, World!"
try:
#Create an AF_INET (IPv4), STREAM socket (TCP)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error, e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
tcp_socket.connect((TCP_IP, TCP_PORT))
try :
#Sending message
tcp_socket.send(MESSAGE_TO_SERVER)
except socket.error, e:
print 'Error occurred while sending data to server. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit()
print 'Message to the server send successfully'
接收数据
我们需要一台服务器来接收数据。要在服务器端使用套接字,socket对象的bind()方法将套接字绑定到地址。它使用一个元组作为输入参数,其中包含套接字的地址和侦听传入请求的端口。listen()方法将套接字置于监听模式,而accept()方法等待传入连接。listen()方法接受一个表示最大排队连接数的参数。因此,通过将此参数指定为3,这意味着如果有三个连接正在等待处理,则第四个连接将被拒绝:
import socket #Imported sockets module
TCP_IP = '127.0.0.1'
TCP_PORT = 8090
BUFFER_SIZE = 1024 #Normally use 1024, to get fast response from the server use small size
try:
#Create an AF_INET (IPv4), STREAM socket (TCP)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error, e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
tcp_socket.bind((TCP_IP, TCP_PORT))
# Listen for incoming connections (max queued connections: 2)
tcp_socket.listen(2)
print 'Listening..'
#Waits for incoming connection (blocking call)
connection, address = tcp_socket.accept()
print 'Connected with:', address
方法accept()将返回服务器和客户端之间的活动连接。数据可以通过recv()方式从连接中读取,也可以通过sendall()方式传输:
data = connection.recv(BUFFER_SIZE)
print "Message from client:", data
connection.sendall("Thanks for connecting") # response for the message from client
connection.close()
最好通过将socket_accept放入一个循环中来保持服务器活动,如下所示:
#keep server alive
while True:
connection, address = tcp_socket.accept()
print 'Client connected:', address
data = connection.recv(BUFFER_SIZE)
print "Message from client:", data
connection.sendall("Thanks for connecting") #Echo the message from client
保存到server.py并在终端中按如下方式启动服务器:
$ python server.py
服务器终端可能如下所示:

现在,我们可以修改客户端脚本以从服务器接收响应:
import socket #Imported sockets module
import sys
TCP_IP = '127.0.0.1'
TCP_PORT = 8090 # Reserve a port
BUFFER_SIZE = 1024
MESSAGE_TO_SERVER = "Hello, World!"
try:
#Create an AF_INET (IPv4), STREAM socket (TCP)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error, e:
print 'Error occured while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
tcp_socket.connect((TCP_IP, TCP_PORT))
try :
#Sending message
tcp_socket.send(MESSAGE_TO_SERVER)
except socket.error, e:
print 'Error occurred while sending data to server. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit()
print 'Message to the server send successfully'
data = tcp_socket.recv(BUFFER_SIZE)
tcp_socket.close() #Close the socket when done
print "Response from server:", data
将此保存到client.py并运行。请确保服务器脚本正在运行。客户端终端可能如下所示:

处理多个连接
在前面的示例中,我们使用 while 循环处理不同的客户机;这一次只能与一个客户端交互。为了使服务器与多个客户端交互,我们必须使用多线程。当main程序接受一个连接时,它会创建一个新线程来处理该连接的通信,然后返回以接受更多连接。
我们可以使用 threads 模块为服务器接受的每个连接创建线程处理程序。
start_new_thread()接受两个参数:
- 要运行的函数名
- 该函数的参数元组
让我们看看如何用线程重写前面的示例:
import socket #Imported sockets module
import sys
from thread import *
TCP_IP = '127.0.0.1'
TCP_PORT = 8090 # Reserve a port
try:
#create an AF_INET (IPv4), STREAM socket (TCP)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error, e:
print 'Error occured while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
#Bind socket to host and port
tcp_socket.bind((TCP_IP, TCP_PORT))
tcp_socket.listen(10)
print 'Listening..'
#Function for handling connections. Used to create threads
def ClientConnectionHandler(connection):
BUFFER_SIZE = 1024
#Sending message to client
connection.send('Welcome to the server')
#infinite loop to keep the thread alive.
while True:
#Receiving data from client
data = connection.recv(BUFFER_SIZE)
reply = 'Data received:' + data
if not data:
break
connection.sendall(reply)
#Exiting loop
connection.close()
#keep server alive always (infinite loop)
while True:
connection, address = tcp_socket.accept()
print 'Client connected:', address
start_new_thread(ClientConnectionHandler ,(connection,))
tcp_socket.close()
提示
有关插座模块的更多详细信息,请转至https://docs.python.org/2.7/library/socket.html 。
SocketServer
SocketServer是一个有趣的模块,它是一个创建网络服务器的框架。它有预定义的类,用于使用 TCP、UDP、UNIX 流和 UNIX 数据报处理同步请求。我们还可以使用 mix-in 类为每种类型的服务器创建分叉和线程版本。在许多情况下,您可以简单地使用一个现有的服务器类。SocketServer模块中定义的五种不同的服务器类如下:
-
BaseServer:定义 API,不直接使用 -
TCPServer:使用 TCP/IP 套接字 -
UDPServer:使用数据报套接字 -
UnixStreamServer:Unix 域流套接字 -
UnixDatagramServer:Unix 域数据报套接字
要使用此模块构建服务器,我们必须传递要侦听的地址(由地址和端口号组成的元组)和请求处理程序类。请求处理程序将接收传入的请求并决定要采取的操作。此类必须有一个方法,该方法重写以下任何RequestHandler方法;大多数情况下,我们可以简单地重写一个handle()方法。将为每个请求创建此类的新实例:
-
setup():在handle()方法之前调用,为请求准备请求处理程序 -
handle():解析传入请求,处理数据,响应请求 -
finish():在handle()方法后调用,用于清理setup()期间创建的任何内容
带 SocketServer 模块的简单服务器
下面的脚本展示了如何使用SocketServer创建一个简单的 echo 服务器:
import SocketServer #Imported SocketServer module
#The RequestHandler class for our server.
class TCPRequestHandler( SocketServer.StreamRequestHandler ):
def handle( self ):
self.data = self.request.recv(1024).strip()
print "{} wrote:".format(self.client_address[0])
print self.data
#Sending the same data
self.request.sendall(self.data)
#Create the server, binding to localhost on port 8090
server = SocketServer.TCPServer( ("", 8090), TCPRequestHandler )
#Activate the server; this will keep running untile we interrupt
server.serve_forever()
脚本的第一行导入SocketServer模块:
import SocketServer
然后,我们创建了一个请求处理程序,该处理程序继承SocketServer.StreamRequestHandler类并重写handle()方法来处理服务器的请求。方法handle()接收数据并打印,然后向客户端响应:
class TCPRequestHandler( SocketServer.StreamRequestHandler ):
def handle( self ):
self.data = self.request.recv(1024).strip()
print "{} wrote:".format(self.client_address[0])
print self.data
# sending the same data
self.request.sendall(self.data)
对于服务器的每个请求,都会实例化此请求处理程序类。此服务器是使用SocketServer.TCPServer类创建的,在该类中,我们提供服务器将绑定到的地址,并请求处理程序类。它将返回一个TCPServer对象。最后,我们调用了serve_forever()方法来启动服务器并处理请求,直到我们发送一个明确的shutdown()请求(键盘中断):
tcp_server = SocketServer.TCPServer( ("", 8090), TCPRequestHandler )
tcp_server.serve_forever()
提示
有关插座模块的更多详细信息,请转至http://xahlee.info/python_doc_2.7.6/library/socketserver.html 。
我们在互联网上发送和接收的所有信息都涉及数据包;我们收到的每个网页和电子邮件都是一系列的数据包,我们发送的所有东西都是一系列的数据包。数据分成以字节为单位的特定大小的数据包。每个数据包携带信息,以识别其目的地、来源和互联网使用的协议的其他详细信息,以及我们数据体的一部分。网络数据包分为三部分:
- 头:包含包携带数据的说明
- 有效载荷:这是一个包的数据
- 拖车:这是拖车,通知接收设备封包结束
TCP/IP 等协议的头由内核或操作系统堆栈提供,但我们可以使用原始套接字为此协议提供自定义头。Linux 中的原生套接字 API 支持原始套接字,但 Windows 中不支持原始套接字。尽管原始套接字很少在应用程序中使用,但它们在网络安全应用程序中被广泛使用。
所有数据包的结构都是相同的,包括 IP 头和一个可变长度的数据字段。首先,我们有固定大小为 14 字节的以太网报头,然后是 IP 报头(如果是 IP 数据包),或者 TCP 报头(如果是 TCP 数据包),基于以太网报头最后两个字节中指定的以太网类型:

在以太网报头中,前六个字节是目标主机,后面是六个字节的源主机。最后两个字节是以太网类型:

IP 报头的长度为 20 字节;前 12 个字节包括版本、IHL、总计**长度、标志**等,后 4 个字节代表源地址。最后,最后四个字节是目标地址:

提示
有关 IP 数据包结构的更多详细信息,请转至http://www.freesoft.org/CIE/Course/Section3/7.htm 。
创建原始套接字
要使用 Python 创建原始套接字,应用程序必须在系统上具有 root 权限。以下示例创建了一个IPPROTO_RAW套接字,它是一个原始 IP 数据包:
import socket #Imported sockets module
try:
#create an INET, raw socket
raw_socket = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_RAW)
except socket.error as e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit()
创建raw套接字后,我们必须构造要发送的数据包。这些数据包类似于 C 中的结构,在 Python 中是不可用的,因此我们必须使用 Pythonstruct模块在前面指定的结构中打包和解包数据包。
基本原始套接字嗅探器
raw套接字嗅探器的最基本形式如下:
import socket #Imported sockets module
try:
#create an raw socket
raw_socket = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, socket.htons(0x0800))
except socket.error, e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
while True:
packet = raw_socket.recvfrom(2048)
print packet
像往常一样,我们在第一行导入了套接字模块。后来,我们创建了一个具有以下内容的套接字:
raw_socket = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, socket.htons(0x0800))第一个参数表示数据包接口为PF_PACKET(Linux specific, we have to use AF_INET for Windows),第二个参数指定为原始套接字。第三个参数表示我们感兴趣的协议。值0x0800表示我们对 IP 协议感兴趣。之后,我们调用recvfrom方法以无限循环方式接收数据包:
while True:
packet = raw_socket.recvfrom(2048)
print packet
现在我们可以解析packet,因为前 14 个字节是以太网报头,其中前 6 个字节是目标主机,接下来 6 个字节是源主机。让我们重写无限循环并添加代码,以从 Ethernet 头解析目标主机和源主机。首先,我们可以按如下方式剥离以太网报头:
ethernet_header = packet[0][0:14]
然后我们可以使用struct解析并解包头,如下所示:
eth_header = struct.unpack("!6s6s2s", ethernet_header)
这将返回一个包含三个十六进制值的元组。我们可以通过binascii模块中的hexlify将其转换为十六进制值:
print "destination:" + binascii.hexlify(eth_header[0]) + " Source:" + binascii.hexlify(eth_header[1]) + " Type:" + binascii.hexlify(eth_header[2]
类似地,我们可以得到 IP 报头,它是数据包中接下来的 20 个字节。前 12 个字节包括版本、IHL、长度、标志等,我们对此不感兴趣,但接下来的 8 个字节是源和目标 IP 地址,如图所示:
ip_header = packet[0][14:34]
ip_hdr = struct.unpack("!12s4s4s", ip_header)
print "Source IP:" + socket.inet_ntoa(ip_hdr[1]) + " Destination IP:" + socket.inet_ntoa(ip_hdr[2]))
最后的脚本如下:
import socket #Imported sockets module
import struct
import binascii
try:
#Create an raw socket
raw_socket = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, socket.htons(0x0800))
except socket.error, e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
while True:
packet = raw_socket.recvfrom(2048)
ethernet_header = packet[0][0:14]
eth_header = struct.unpack("!6s6s2s", ethernet_header)
print "destination:" + binascii.hexlify(eth_header[0]) + " Source:" + binascii.hexlify(eth_header[1]) + " Type:" + binascii.hexlify(eth_header[2])
ip_header = packet[0][14:34]
ip_hdr = struct.unpack("!12s4s4s", ip_header)
print "Source IP:" + socket.inet_ntoa(ip_hdr[1]) + " Destination IP:" + socket.inet_ntoa(ip_hdr[2])
这将输出网卡的源和目标 MAC 地址,以及数据包的源和目标 IP。确保数据包接口设置正确。PF_PACKE是 Linux 专用的,我们必须在 Windows 上使用AF_INET。类似地,我们可以解析 TCP 头。
提示
有关struct模块的更多详细信息,请阅读https://docs.python.org/3/library/struct.html 。
原始套接字包注入
我们可以使用原始套接字发送定制的数据包。如前所述,我们可以使用套接字模块创建原始套接字,如下所示:
import socket #Imported sockets module
try:
#create an INET, raw socket
raw_socket = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, socket.htons(0x0800))
except socket.error, e:
print ('Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1])
sys.exit()
要注入数据包,我们需要将套接字绑定到接口:
raw_socket.bind(("wlan0", socket.htons(0x0800)))
现在我们可以使用struct中的 pack 方法创建一个以太网数据包,其中包含源地址、目标地址和以太网类型。此外,我们可以向数据包中添加一些数据并发送:
packet = struct.pack("!6s6s2s", '\xb8v?\x8b\xf5\xfe', 'l\x19\x8f\xe1J\x8c', '\x08\x00')
raw_socket.send(packet + "Hello")
注入 IP 数据包的整个脚本如下所示:
import socket #Imported sockets module
import struct
try:
#Create an raw socket
raw_socket = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, socket.htons(0x0800))
except socket.error as e:
print 'Error occurred while creating socket. Error code: ' + str(e[0]) + ' , Error message : ' + e[1]
sys.exit();
raw_socket.bind(("wlan0", socket.htons(0x0800)))
packet = struct.pack("!6s6s2s", '\xb8v?\x8b\xf5\xfe', 'l\x19\x8f\xe1J\x8c', '\x08\x00')
raw_socket.send(packet + "Hello")
在前面的部分中,我们用原始套接字嗅探并注入数据包,在这里我们必须自己解析、解码、创建和注入数据包。此外,原始套接字并不与所有操作系统兼容。有许多第三方库可以帮助我们处理数据包。Scapy 是一个非常强大的交互式数据包处理库和工具,从所有这些库中脱颖而出。Scapy 为我们提供了不同的命令,从初级到高级,用于调查网络。我们可以在两种不同的模式下使用 Scapy:在终端窗口中以交互方式使用,以及通过将 Python 脚本作为库导入以编程方式使用。
让我们使用交互模式开始 Scapy。交互模式类似于 pythonshell;要激活此功能,只需在终端中以 root 权限运行 Scapy:
$ sudo scapy
这将在 Scapy 中返回一个交互式终端:

以下是一些用于交互使用的基本命令:
-
ls():显示 Scapy 支持的所有协议 -
lsc():显示 Scapy 支持的命令列表 -
conf:显示所有配置选项 -
help():显示特定命令的帮助,例如help(sniff) -
show():显示特定数据包的详细信息,如Newpacket.show()
Scapy 帮助创建基于其支持的大量协议集的自定义数据包。现在,我们可以在交互式 Scapy shell 中使用 Scapy 创建简单的数据包:
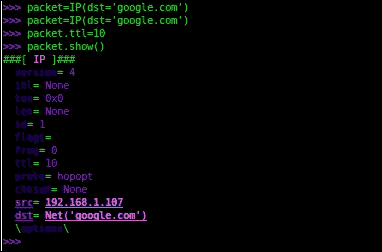
>>> packet=IP(dst='google.com')
>>> packet.ttl=10
这将创建一个数据包;现在我们可以使用以下方法查看数据包:
>>> packet.show()
以下屏幕截图显示了该数据包的使用情况:
Scapy 通过每个数据包中的层和每个层中的字段创建和解析数据包。每个层都封装在父层内。Scapy 中的数据包是 Python 字典,因此每个数据包都是一组嵌套字典,每一层都是父层的子字典。summary()方法将提供数据包层的详细信息:
>>> packet[0].summary()
'Ether / IP / UDP 192.168.1.35:20084 > 117.206.55.151:43108 / Raw'
通过括号的嵌套(<和>可以更好地看到数据包的层结构:
>>> packet[0]
<Ether dst=6c:19:8f:e1:4a:8c src=b8:76:3f:8b:f5:fe type=0x800 |<IP version=4L ihl=5L tos=0x0 len=140 id=30417 flags=DF frag=0L ttl=64 proto=udp chksum=0x545f src=192.168.1.35 dst=117.206.55.151 options=[] |<UDP sport=20084 dport=43108 len=120 chksum=0xd750 |<Raw load='\x90\x87]{\xa1\x9c\xe7$4\x07\r\x7f\x10\x83\x84\xb5\x1d\xae\xa1\x9eWgX@\xf1\xab~?\x7f\x84x3\xee\x98\xca\xf1\xbdtu\x93P\x8f\xc9\xdf\xb70-D\x82\xf6I\xe0\x84\x0e\xcaH\xd0\xbd\xf7\xed\xf3y\x8e>\x11}\x84T\x05\x98\x02h|\xed\t\xb1\x85\x9f\x8a\xbc\xdd\x98\x07\x14\x10\no\x00\xda\xbf9\xd9\x8d\xecZ\x9a2\x93\x04CyG\x0c\xbd\xf2V\xc6<"\x82\x1e\xeb' |>>>>
我们可以通过列表索引中的名称或索引号来挖掘特定层。例如,我们可以通过以下方式获得前面数据包的 UDP 层:
>>> packet[0]
.[UDP].summary()
或者,您可以使用以下方法获取 UDP 层:
>>> packet[0]
.[2].summary()
使用 Scapy,我们可以解析每个层中字段的值。例如,我们可以通过以下方式获得以太网层中的源字段:
>>> packet[0]
[Ether].src
使用 Scapy 进行数据包嗅探
使用 Scapy,使用sniff方法sniff数据包非常简单。我们可以在 Scapy shell 中运行以下命令到接口eth0中的sniff:
>>>packet = sniff(iface="eth0", count=3)
这将从eth0接口获得三个数据包。通过hexdump(),我们可以在hex中转储数据包:
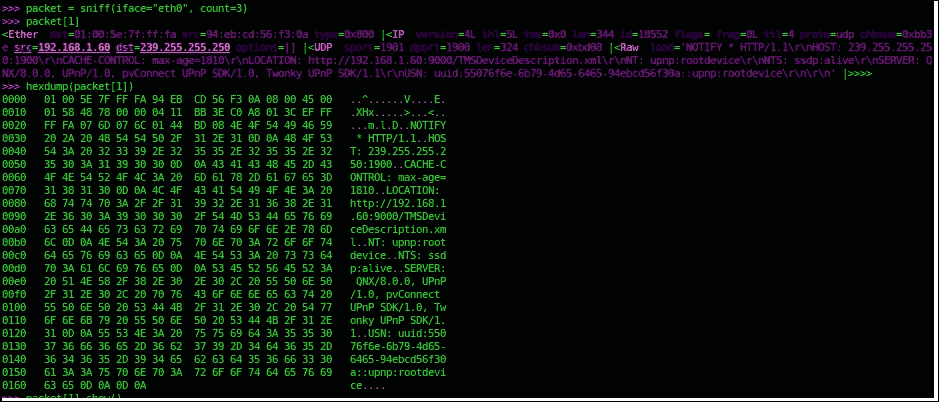
sniff()方法的参数如下:
-
count:要捕获的数据包数,但 0 表示无限 -
iface:嗅探接口;仅在此接口上嗅探数据包 -
prn:在每个数据包上运行的函数 -
store:是否保存或丢弃嗅探到的数据包;当我们只需要监视时设置为 0 -
timeout:一段时间后停止嗅探;默认值为“无” -
filter:使用 BPF 语法过滤器过滤嗅探
如果我们想看到更多的数据包内容,show()方法是好的。它将在清洁器中显示数据包,并生成格式化打印输出,如下所示:
>>>packet[1].show()
此命令将提供以下输出:

要实时查看嗅探到的数据包,我们必须使用 lambda 函数以及summary()或show()方法:
>>> packet=sniff(filter="icmp", iface="eth0″, count=3, prn=lambda x:x.summary())
此外,还可以使用 Scapy 将数据包写入pcap文件。要将数据包写入pcap文件,我们可以使用wrpcap()方法:
>>>wrpcap("pkt-output.cap" packets)
这将把数据包写入一个pkt-output.cap文件。我们可以通过rdpcap()从pcap文件中读取:
>>> packets = rdpcap("pkt-output.cap")
用 Scapy 进行包封注射
在注入之前,我们必须创建一个伪造的数据包。使用 Scapy,如果我们知道数据包的分层结构,那么创建数据包就非常简单。要创建 IP 数据包,我们使用以下语法:
>>> packet = IP (dst="packtpub.com")
要向该数据包添加更多子层,我们只需添加以下内容:
>>> packet = IP (dst="packtpub.com")/ICMP()/"Hello Packt"
这将创建一个包含 IP 层、ICMP层和原始有效负载的数据包,如"Hello Packt"。show()方法将显示此数据包,如下所示:
>>> packet.show()
###[ IP ]###
version= 4
ihl= None
tos= 0x0
len= None
id= 1
flags=
frag= 0
ttl= 64
proto= icmp
chksum= None
src= 192.168.1.35
dst= Net('packtpub.com')
\options\
###[ ICMP ]###
type= echo-request
code= 0
chksum= None
id= 0x0
seq= 0x0
###[ Raw ]###
load= 'Hello world'
要发送数据包,我们有两种方法:
-
sendp():第二层发送;发送第二层数据包 -
send():三层发送;仅发送第 3 层数据包,如 IPv4 和 Ipv6
send 命令的主要参数如下所示:
-
iface:发送数据包的接口 -
inter:两个数据包之间的时间(秒) -
loop:为了不停地发送数据包,将其设置为1 -
packet:数据包或数据包列表
如果我们使用第二层发送,我们必须添加一个以太网层,并提供正确的接口来发送数据包。但对于第三层,发送所有这些路由信息将由 Scapy 自己处理。因此,让我们使用第 3 层发送发送之前创建的数据包:
>>> send(packet)
我们发送的数据包可以使用另一个 Scapy 交互终端进行嗅探。输出如下,第二个数据包是我们从packtpub.com收到的响应:

类似地,要发送第 2 层数据包,我们必须添加以太网报头和接口,如下所示:
>>> sendp(Ether()/IP(dst="packtpub.com")/ICMP()/"Layer 2 packet", iface="eth0")
选择发送和接收方式
当我们期望得到响应时,这些方法用于发送一个或一组数据包。有四种不同类型的发送和接收方法。详情如下:
-
sr():第三层发送和接收,返回应答和未应答数据包 -
sr1():第三层发送和接收,仅返回应答或发送的数据包 -
srp():第二层发送和接收,返回应答和未应答数据包 -
srp1():第二层发送和接收,仅返回应答或发送的数据包
这些方法几乎与send()方法相似。要发送数据包并接收其响应,请使用以下命令:
>>> packet = IP (dst="packtpub.com")/ICMP()/"Hello Packt"
>>> sr(packet)
Begin emission:
.Finished to send 1 packets.
.*
Received 3 packets, got 1 answers, remaining 0 packets
(<Results: TCP:0 UDP:0 ICMP:1 Other:0>, <Unanswered: TCP:0 UDP:0 ICMP:0 Other:0>)
在这里,当等待响应时,Scapy 收到三个数据包,并在收到响应时退出。如果我们使用sr1(),这将只等待一个响应并打印响应包。类似地,我们可以使用srp()和srp1()方法发送第二层数据包。
用 Scapy 编程
早些时候,我们在交互模式下使用 Scapy。但在某些情况下,我们可能需要在脚本中使用 Scapy。如果在我们的程序中导入 Scapy,它可以用作库。我们可以按如下方式导入所有 Scapy 功能:
from scapy.all import*
或者,如果我们只需要几个函数,我们可以导入特定的包,如下所示:
from scapy.all Ether, IP, TCP, sr1
例如,我们可以创建一个 DNS 请求。通过sr1()方法,我们可以创建并获取 DNS 请求的响应。由于 DNS 数据包是从 IP 和 UDP 数据包构建的,因此我们可以创建一个包含 IP 和 UDP 层的 DNS 数据包:
from scapy.all import * #Import Scapy
# Create a DNS request Packet to 8.8.8.8
dns_packet = IP(dst="8.8.8.8")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="packtpub.com"))
# Send packet and get the response
dns_request = sr1(dns_packet,verbose=1)
# Print the response
print dns_request[DNS].summary()
我们必须以 root 权限运行此脚本。如果详细选项为1,则输出如下:
$ sudo python dns_scapy.py
WARNING: No route found for IPv6 destination :: (no default route?)
Begin emission:
Finished to send 1 packets
Received 18 packets, got 1 answers, remaining 0 packets
DNS Ans "83.166.169.231"
要解析 DNS 数据包,我们可以使用sniff()方法。sniff()中的prn参数可用于通过 Scapy 更改每个数据包的输出。它有助于用我们自己的函数替换默认的 Scapy 打印输出,因此我们可以决定 Scapy 如何打印每个数据包的输出。这里,在下面的示例中,每当过滤器识别匹配的数据包并使用 Scapy 嗅探时,我们都使用select_DNS()函数:
from scapy.all import * #Import Scapy
from datetime import datetime
interface = 'eth0' #Interface to sniff
filter_bpf = 'udp and port 53' #BPF filter to filter udp packets in port 53
#Runs this for each packet
def select_DNS(packet):
packet_time = packet.sprintf('%sent.time%')
try:
if DNSQR in packet and packet.dport == 53:
#Print queries
print 'DNS queries Message from '+ packet[IP].src + '
to ' + packet[IP].dst +' at ' + packet_time
elif DNSRR in packet and packet.sport == 53:
#Print responses
print 'DNS responses Message from '+ packet[IP].src + '
to ' + packet[IP].dst +' at ' + packet_time
except:
pass
#Sniff the packets
sniff(iface=interface, filter=filter_bpf, store=0, prn=select_DNS)
像往常一样,我们在前两行中导入了必要的模块 Scapy 和 datetime;之后,我们声明了 sniff 接口和过滤器,以使用Berkeley 数据包过滤器(BPF语法从端口53获取udp数据包:
from scapy.all import * #Import Scapy
from datetime import datetime
interface = 'eth0' #Interface to sniff
filter_bpf = 'udp and port 53' #BPF filter to filter udp packets in port 53
然后我们声明了当使用sniff()方法嗅探每个数据包时要调用的函数。这将修改sniff()中的默认打印输出摘要,并提供自定义输出。在这里,它将检查 DNS 数据包并输出其源目的地和时间。prn参数用于将此函数绑定到sniff()方法:
def select_DNS(packet):
packet_time = packet.sprintf('%sent.time%')
try:
if DNSQR in packet and packet.dport == 53:
#Print queries
print 'DNS queries Message from '+ packet[IP].src + '
to ' + packet[IP].dst +' at ' + packet_time
elif DNSRR in packet and packet.sport == 53:
#Print responses
print 'DNS responses Message from '+ packet[IP].src + '
to ' + packet[IP].dst +' at ' + packet_time
except:
pass
最后,我们将使用一个select_DNS()函数作为prn参数来调用sniff()方法。
sniff(iface=interface, filter=filter_bpf, store=0, prn=select_DNS)
提示
有关 Berkeley 数据包过滤器(BPF)语法的更多详细信息,请阅读http://biot.com/capstats/bpf.html 。
让我们看看操作系统指纹识别中的另一个例子;我们可以通过两种方法来实现这一点:
- Nmap 指纹
- p0f
如果您的系统上安装了 Nmap,我们可以使用 Scapy 使用其活动 OS 指纹数据库。确保签名数据库位于conf.nmap_base中指定的路径。如果您使用的是默认安装目录,Scapy 将自动检测指纹文件。
我们可以在nmap模块中加载以下内容:
load_module("nmap")
然后我们可以使用nmap_fp()功能开始对操作系统进行指纹识别。
nmap_fp("192.168.1.1",oport=443,cport=1)
如果我们安装了p0f,我们可以使用它来识别操作系统。确保配置conf.p0f_base正确无误。我们可以从一个捕获的数据包中猜测操作系统,如下所示:
sniff(prn=prnp0f)
提示
有关 Scapy 的更多详细信息,请阅读http://www.secdev.org/projects/scapy/doc/usage.html 。
我们已经通过各种 Python 模块了解了数据包制作和嗅探的基础知识,并看到 Scapy 非常强大且易于使用。现在我们已经学习了套接字编程和 Scapy 的基础知识。在我们的安全评估过程中,我们可能需要原始输出和访问数据包拓扑的基本级别,以便我们能够自己分析和做出决策。Scapy 最吸引人的部分是,它可以导入并用于创建网络工具,而无需从头开始创建数据包。
在下一章中,我们将更详细地讨论 Python 中的应用程序指纹。