- Python Web 渗透测试
- Python Web 渗透秘籍
- Python 高效渗透测试

Python 收集开源情报详解
在本章中,我们将介绍以下主题:
开源情报**OSIT**是从公开(公开)来源收集信息的过程。在测试 web 应用程序时,这似乎是一件奇怪的事情。然而,在接触某个特定网站之前,就可以了解该网站的大量信息。您可能能够找到网站使用的服务器端语言、基础框架,甚至其凭据。学习使用 API 和编写这些任务的脚本可以使收集阶段的大部分工作变得更加容易。
在本章中,我们将介绍使用 Python 利用 API 的强大功能来深入了解目标的几种方法。
Shodan 本质上是一个漏洞搜索引擎。通过向其提供名称、IP 地址甚至端口,它将返回其数据库中匹配的所有系统。这使得它成为基础设施方面最有效的情报来源之一。这就像谷歌搜索互联网连接设备一样。Shodan 不断扫描互联网,并将结果保存到公共数据库中。而该数据库可从 Shodan 网站(网站)进行搜索 https://www.shodan.io ),报告的结果和服务是有限的,除非您通过应用程序编程接口(API访问)。
本节的任务是通过使用 Shodan API 获取关于 Packt 发布网站的信息。
准备好了吗
在撰写本文时,Shodan 的会员费是 49 美元,这是获得 API 密钥所必需的。如果你对安全问题很认真,访问 Shodan 是无价的。
如果您还没有 Shodan 的 API 密钥,请访问www.Shodan.io/store/member并注册。Shodan 有一个非常好的 Python 库,在中也有很好的文档记录 https://shodan.readthedocs.org/en/latest/ 。
要将 Python 环境设置为与 Shodan 一起使用,只需使用cheeseshop安装库即可:
$ easy_install shodan
怎么做…
下面是我们将用于此任务的脚本:
import shodan
import requests
SHODAN_API_KEY = "{Insert your Shodan API key}"
api = shodan.Shodan(SHODAN_API_KEY)
target = 'www.packtpub.com'
dnsResolve = 'https://api.shodan.io/dns/resolve?hostnames=' + target + '&key=' + SHODAN_API_KEY
try:
# First we need to resolve our targets domain to an IP
resolved = requests.get(dnsResolve)
hostIP = resolved.json()[target]
# Then we need to do a Shodan search on that IP
host = api.host(hostIP)
print "IP: %s" % host['ip_str']
print "Organization: %s" % host.get('org', 'n/a')
print "Operating System: %s" % host.get('os', 'n/a')
# Print all banners
for item in host['data']:
print "Port: %s" % item['port']
print "Banner: %s" % item['data']
# Print vuln information
for item in host['vulns']:
CVE = item.replace('!','')
print 'Vulns: %s' % item
exploits = api.exploits.search(CVE)
for item in exploits['matches']:
if item.get('cve')[0] == CVE:
print item.get('description')
except:
'An error occured'前面的脚本应产生类似于以下内容的输出:
IP: 83.166.169.231
Organization: Node4 Limited
Operating System: None
Port: 443
Banner: HTTP/1.0 200 OK
Server: nginx/1.4.5
Date: Thu, 05 Feb 2015 15:29:35 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Expires: Sun, 19 Nov 1978 05:00:00 GMT
Cache-Control: public, s-maxage=172800
Age: 1765
Via: 1.1 varnish
X-Country-Code: US
Port: 80
Banner: HTTP/1.0 301 https://www.packtpub.com/
Location: https://www.packtpub.com/
Accept-Ranges: bytes
Date: Fri, 09 Jan 2015 12:08:05 GMT
Age: 0
Via: 1.1 varnish
Connection: close
X-Country-Code: US
Server: packt
Vulns: !CVE-2014-0160
The (1) TLS and (2) DTLS implementations in OpenSSL 1.0.1 before 1.0.1g do not properly handle Heartbeat Extension packets, which allows remote attackers to obtain sensitive information from process memory via crafted packets that trigger a buffer over-read, as demonstrated by reading private keys, related to d1_both.c and t1_lib.c, aka the Heartbleed bug.
我刚刚选择了 Shodan 返回的一些可用数据项,但您可以看到我们得到了相当多的信息。在这个特定的例子中,我们可以看到存在一个潜在的漏洞。我们还看到该服务器正在侦听端口80和443,根据横幅信息,它似乎正在运行nginx作为 HTTP 服务器。
它是如何工作的…
-
首先,我们在代码中设置静态字符串;这包括我们的 API 密钥:
SHODAN_API_KEY = "{Insert your Shodan API key}" target = 'www.packtpub.com' dnsResolve = 'https://api.shodan.io/dns/resolve?hostnames=' + target + '&key=' + SHODAN_API_KEY -
下一步是创建我们的 API 对象:
api = shodan.Shodan(SHODAN_API_KEY) -
为了使用 API 搜索主机信息,我们需要知道主机的 IP 地址。Shodan 有一个 DNS 解析器,但它不包含在 Python 库中。要使用 Shodan 的 DNS 解析程序,我们只需向 Shodan DNS 解析程序 URL 发出 GET 请求,并将其传递给我们感兴趣的域:
resolved = requests.get(dnsResolve) hostIP = resolved.json()[target] -
返回的 JSON 数据将是域到 IP 地址的字典;因为在我们的例子中只有一个目标,所以我们可以简单地使用
target字符串作为字典的密钥来提取主机的 IP 地址。如果您在多个域上搜索,您可能希望遍历此列表以获取所有 IP 地址。 -
现在,我们有了主机的 IP 地址,我们可以使用 Shodan libraries
host函数获取关于我们主机的信息。返回的 JSON 数据包含大量关于主机的信息,不过在我们的示例中,我们将只提取 IP 地址、组织以及正在运行的操作系统(如果可能)。然后,我们将遍历所有被发现开放的端口及其各自的横幅:host = api.host(hostIP) print "IP: %s" % host['ip_str'] print "Organization: %s" % host.get('org', 'n/a') print "Operating System: %s" % host.get('os', 'n/a') # Print all banners for item in host['data']: print "Port: %s" % item['port'] print "Banner: %s" % item['data'] -
The returned data may also contain potential Common Vulnerabilities and Exposures (CVE) numbers for vulnerabilities that Shodan thinks the server may be susceptible to. This could be really beneficial to us, so we will iterate over the list of these (if there are any) and use another function from the Shodan library to get information on the exploit:
for item in host['vulns']: CVE = item.replace('!','') print 'Vulns: %s' % item exploits = api.exploits.search(CVE) for item in exploits['matches']: if item.get('cve')[0] == CVE: print item.get('description')这就是我们的剧本。尝试在您自己的服务器上运行它。
还有更多…
我们用我们的脚本只触及了 Shodan Python 库的表面。阅读 Shodan API 参考文档并使用其他搜索选项是非常值得的。您可以根据“方面”筛选结果以缩小搜索范围。您甚至可以使用其他用户使用“标记”搜索保存的搜索。
提示
下载示例代码
您可以从您的账户下载示例代码文件 http://www.packtpub.com 对于您购买的所有 Packt 出版书籍。如果您在其他地方购买了本书,您可以访问http://www.packtpub.com/support 并注册,将文件直接通过电子邮件发送给您。
社交媒体是收集目标公司或个人信息的好方法。在这里,我们将向您展示如何编写 Google+API 搜索脚本,以便在 Google+社交网站中查找公司的联系信息。
准备好了吗
一些 Google API 需要授权才能访问它们,但是如果你有 Google 帐户,获取 API 密钥很容易。只需转到https://console.developers.google.com 并创建一个新项目。点击API&认证**凭证。点击创建新密钥和服务器密钥。可选择输入您的 IP 或点击创建**。将显示您的 API 密钥,并准备复制和粘贴到以下配方中。
怎么做…
下面是一个查询 Google+API 的简单脚本:
import urllib2
GOOGLE_API_KEY = "{Insert your Google API key}"
target = "packtpub.com"
api_response = urllib2.urlopen("https://www.googleapis.com/plus/v1/people? query="+target+"&key="+GOOGLE_API_KEY).read()
api_response = api_response.split("\n")
for line in api_response:
if "displayName" in line:
print line它是如何工作的…
前面的代码向 Google+搜索 API 发出请求(使用 API 密钥进行身份验证),并搜索中与目标匹配的帐户;packtpub.com。与前面的 Shodan 脚本类似,我们设置了静态字符串,包括 API 键和目标:
GOOGLE_API_KEY = "{Insert your Google API key}"
target = "packtpub.com"下一步做两件事:首先,它向 API 服务器发送 HTTPGET请求,然后读取响应并将输出存储到api_response变量中:
api_response = urllib2.urlopen("https://www.googleapis.com/plus/v1/people? query="+target+"&key="+GOOGLE_API_KEY).read()此请求返回 JSON 格式的响应;结果的示例片段如下所示:
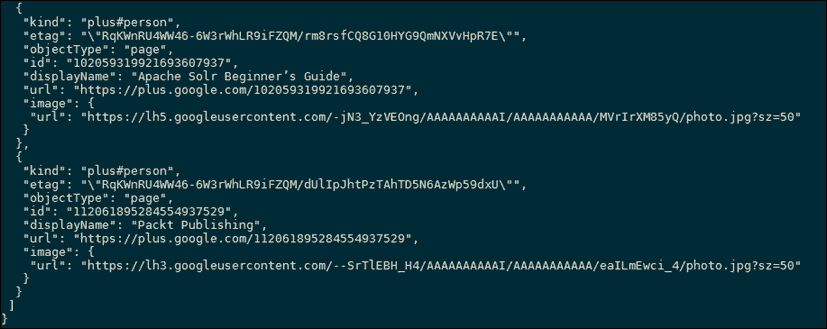
在我们的脚本中,我们将响应转换为列表,以便更容易解析:
api_response = api_response.split("\n")代码的最后一部分在列表中循环并仅打印包含displayName的行,如下所示:
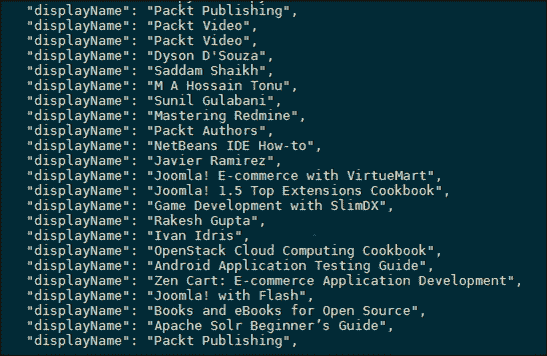
另见…
在下一个配方中,使用 Google+API下载个人资料图片,我们将研究如何改进这些结果的格式。
还有更多…
通过从一个简单的脚本开始查询 Google+API,我们可以将其扩展为更高效,并使用更多返回的数据。Google+平台的另一个关键方面是,用户也可能在另一个 Google 服务上拥有匹配的帐户,这意味着您可以交叉引用帐户。大多数谷歌产品都有一个 API 供开发者使用,所以一个好的起点是https://developers.google.com/products/ 。抓取一个 API 密钥并将上一个脚本的输出插入其中。
既然我们已经确定了如何使用 Google+API,我们可以设计一个脚本来下拉图片。这里的目的是将面孔与取自网页的名字对应起来。我们将通过 URL 向 API 发送请求,通过 JSON 处理响应,并在脚本的工作目录中创建图片文件。
怎么做
下面是一个使用 Google+API 下载个人资料图片的简单脚本:
import urllib2
import json
GOOGLE_API_KEY = "{Insert your Google API key}"
target = "packtpub.com"
api_response = urllib2.urlopen("https://www.googleapis.com/plus/v1/people? query="+target+"&key="+GOOGLE_API_KEY).read()
json_response = json.loads(api_response)
for result in json_response['items']:
name = result['displayName']
print name
image = result['image']['url'].split('?')[0]
f = open(name+'.jpg','wb+')
f.write(urllib2.urlopen(image).read())
f.close()它是如何工作的
第一个更改是将显示名称存储到变量中,因为这将在以后重新使用:
name = result['displayName']
print name接下来,我们从 JSON 响应中获取图像 URL:
image = result['image']['url'].split('?')[0]代码的最后一部分用三行简单的代码完成了很多事情:首先,它在本地磁盘上打开一个文件,文件名设置为name变量。此处的wb+标志指示操作系统,如果文件不存在,则应创建该文件,并以原始二进制格式写入数据。第二行向图像 URL 发出 HTTPGET请求(存储在image变量中),并将响应写入文件。最后,关闭文件以释放用于存储文件内容的系统内存:
f = open(name+'.jpg','wb+')
f.write(urllib2.urlopen(image).read())
f.close()脚本运行后,控制台输出与之前相同,显示名称。但是,您的本地目录现在也将包含所有配置文件图像,并保存为 JPEG 文件。
默认情况下,Google+API 最多返回 25 个结果,但我们可以通过增加最大值并通过分页获取更多结果来扩展以前的脚本。与之前一样,我们将通过 URL 和urllib库与 Google+API 进行通信。我们将创建任意数字,随着请求的进行,这些数字会增加,因此我们可以跨页面移动并收集更多结果。
怎么做
以下脚本显示了如何从 Google+API 获取其他结果:
import urllib2
import json
GOOGLE_API_KEY = "{Insert your Google API key}"
target = "packtpub.com"
token = ""
loops = 0
while loops < 10:
api_response = urllib2.urlopen("https://www.googleapis.com/plus/v1/people? query="+target+"&key="+GOOGLE_API_KEY+"&maxResults=50& pageToken="+token).read()
json_response = json.loads(api_response)
token = json_response['nextPageToken']
if len(json_response['items']) == 0:
break
for result in json_response['items']:
name = result['displayName']
print name
image = result['image']['url'].split('?')[0]
f = open(name+'.jpg','wb+')
f.write(urllib2.urlopen(image).read())
loops+=1它是如何工作的
此脚本中的第一个大的更改,即主代码,已移动到while循环中:
token = ""
loops = 0
while loops < 10:在这里,循环数被设置为最多 10 个,以避免向 API 服务器发送太多请求。当然,该值可以更改为任何正整数。下一个更改是请求 URL 本身;它现在包含两个附加的尾部参数maxResults和pageToken。来自 Google+API 的每个响应都包含一个pageToken值,它是指向下一组结果的指针。请注意,如果没有更多结果,仍然会返回一个pageToken值。maxResults参数不言自明,但最多只能增加到 50:
api_response = urllib2.urlopen("https://www.googleapis.com/plus/v1/people? query="+target+"&key="+GOOGLE_API_KEY+"&maxResults=50& pageToken="+token).read()下一部分在 JSON 响应中读取的内容与前面相同,但这次它还提取了nextPageToken值:
json_response = json.loads(api_response)
token = json_response['nextPageToken']如果loops变量增加到 10,主while循环可以停止,但有时您可能只得到一页结果。代码的下一部分检查返回了多少结果;如果没有,则会过早退出循环:
if len(json_response['items']) == 0:
break最后,我们确保每次增加loops整数的值。一个常见的编码错误是忽略了这一点,这意味着循环将永远继续:
loops+=1他们说一幅画胜过千言万语。有时候,在情报收集阶段获取网站截图是件好事。我们可能想扫描一个 IP 范围,了解哪些 IP 在为网页提供服务,更重要的是它们看起来是什么样子。这有助于我们挑选感兴趣的站点进行关注,出于同样的原因,我们还可能希望快速扫描特定 IP 地址上的端口。我们将看看如何使用QtWebKitPython 库实现这一点。
准备好了吗
安装 QtWebKit 有点麻烦。最简单的方法是从获取二进制文件 http://www.riverbankcomputing.com/software/pyqt/download 。对于 Windows 用户,请确保选择符合python/arch路径的二进制文件。例如,我将使用PyQt4-4.11.3-gpl-Py2.7-Qt4.8.6-x32.exe二进制文件在安装了 Python 版本 2.7 的 Windows 32 位虚拟机上安装 Qt4。如果您计划从源文件编译 Qt4,请确保您已经安装了SIP。
怎么做…
一旦安装了 PyQt4,就可以开始了。下面的脚本是我们将用作 screenshot 类的基础的脚本:
import sys
import time
from PyQt4.QtCore import *
from PyQt4.QtGui import *
from PyQt4.QtWebKit import *
class Screenshot(QWebView):
def __init__(self):
self.app = QApplication(sys.argv)
QWebView.__init__(self)
self._loaded = False
self.loadFinished.connect(self._loadFinished)
def wait_load(self, delay=0):
while not self._loaded:
self.app.processEvents()
time.sleep(delay)
self._loaded = False
def _loadFinished(self, result):
self._loaded = True
def get_image(self, url):
self.load(QUrl(url))
self.wait_load()
frame = self.page().mainFrame()
self.page().setViewportSize(frame.contentsSize())
image = QImage(self.page().viewportSize(), QImage.Format_ARGB32)
painter = QPainter(image)
frame.render(painter)
painter.end()
return image创建前面的脚本并将其保存在 PythonLib文件夹中。然后,我们可以在脚本中将其作为导入引用。
它是如何工作的…
脚本使用加载 URL,然后使用 QPaint 创建图像。get_image函数只接受一个参数:我们的目标。知道了这一点,我们可以简单地将其导入另一个脚本并扩展功能。
让我们把脚本分解一下,看看它是如何工作的。
首先,我们建立了我们的进口:
import sys
import time
from PyQt4.QtCore import *
from PyQt4.QtGui import *
from PyQt4.QtWebKit import *然后,我们创建类定义;我们正在创建的类通过继承从QWebView扩展:
class Screenshot(QWebView):接下来,我们创建初始化方法:
def __init__(self):
self.app = QApplication(sys.argv)
QWebView.__init__(self)
self._loaded = False
self.loadFinished.connect(self._loadFinished)
def wait_load(self, delay=0):
while not self._loaded:
self.app.processEvents()
time.sleep(delay)
self._loaded = False
def _loadFinished(self, result):
self._loaded = True初始化方法设置self.__loaded属性。它与__loadFinished和wait_load函数一起用于检查应用程序运行时的状态。它等待站点加载后再截图。实际屏幕截图代码包含在get_image功能中:
def get_image(self, url):
self.load(QUrl(url))
self.wait_load()
frame = self.page().mainFrame()
self.page().setViewportSize(frame.contentsSize())
image = QImage(self.page().viewportSize(), QImage.Format_ARGB32)
painter = QPainter(image)
frame.render(painter)
painter.end()
return image在这个get_image函数中,我们将视口的大小设置为主框架内内容的大小。然后设置图像格式,将图像指定给画家对象,然后使用画家渲染帧。最后,我们返回处理后的图像。
还有更多…
要使用我们刚刚创建的类,我们只需将其导入另一个脚本。例如,如果我们只想保存返回的图像,我们可以执行以下操作:
import screenshot
s = screenshot.Screenshot()
image = s.get_image('http://www.packtpub.com')
image.save('website.png')就这些。在下一个脚本中,我们将创建一些更有用的内容。
在前面的脚本中,我们创建了基本函数,用于返回 URL 的图像。现在,我们将在此基础上进行扩展,以循环浏览通常与基于 web 的管理门户关联的端口列表。这将允许我们将脚本指向 IP,并自动通过可能与 web 服务器关联的端口运行。当我们不知道服务器上打开了哪些端口时,而不是在指定端口和域的位置时,可以使用此选项。
准备好了吗
为了让这个脚本正常工作,我们需要在使用 QtWeb 工具包配方的网站的截图中创建脚本。这应该保存在Pythonxx/Lib文件夹中,并命名为清晰、难忘的内容。在这里,我们将该脚本命名为screenshot.py。脚本的命名尤其重要,因为我们用一个重要的声明引用它。
怎么做…
这是我们将使用的脚本:
import screenshot
import requests
portList = [80,443,2082,2083,2086,2087,2095,2096,8080,8880,8443,9998,4643, 9001,4489]
IP = '127.0.0.1'
http = 'http://'
https = 'https://'
def testAndSave(protocol, portNumber):
url = protocol + IP + ':' + str(portNumber)
try:
r = requests.get(url,timeout=1)
if r.status_code == 200:
print 'Found site on ' + url
s = screenshot.Screenshot()
image = s.get_image(url)
image.save(str(portNumber) + '.png')
except:
pass
for port in portList:
testAndSave(http, port)
testAndSave(https, port)它是如何工作的…
我们首先创建我们的进口报关单。在这个脚本中,我们使用之前创建的screenshot脚本和requests库。使用requests库是为了在尝试将请求转换为图像之前检查请求的状态。我们不想浪费时间试图转换不存在的网站。
接下来,我们导入我们的库:
import screenshot
import requests下一步将设置我们将迭代的公共端口号数组。我们还使用将要使用的 IP 地址设置了一个字符串:
portList = [80,443,2082,2083,2086,2087,2095,2096,8080,8880,8443,9998,4643, 9001,4489]
IP = '127.0.0.1'接下来,我们创建字符串来保存我们稍后将构建的 URL 的协议部分;这只会使代码稍后更整洁一些:
http = 'http://'
https = 'https://'接下来,我们创建我们的方法,该方法将完成构建 URL 字符串的工作。在我们创建了 URL 之后,我们检查是否为我们的get请求返回了200响应代码。如果请求成功,我们将返回的网页转换为图像并保存,文件名为成功的端口号。代码被包装在一个try块中,因为当我们发出请求时,如果站点不存在,它将抛出一个错误:
def testAndSave(protocol, portNumber):
url = protocol + IP + ':' + str(portNumber)
try:
r = requests.get(url,timeout=1)
if r.status_code == 200:
print 'Found site on ' + url
s = screenshot.Screenshot()
image = s.get_image(url)
image.save(str(portNumber) + '.png')
except:
pass现在我们的方法准备好了,我们只需迭代端口列表中的每个端口并调用我们的方法。我们对 HTTP 协议执行一次,然后对 HTTPS 执行一次:
for port in portList:
testAndSave(http, port)
testAndSave(https, port)就这样。只需运行脚本,它就会将图像保存到与脚本相同的位置。
还有更多…
您可能会注意到脚本需要一段时间才能运行。这是因为它必须依次检查每个端口。实际上,您可能希望将其设置为多线程脚本,以便它可以同时检查多个 URL。让我们来看看如何修改代码来实现这个目标。
首先,我们需要更多的导入声明:
import Queue
import threading接下来,我们需要创建一个新函数,我们将调用它threader。此新函数将处理将我们的testAndSave函数放入队列的操作:
def threader(q, port):
q.put(testAndSave(http, port))
q.put(testAndSave(https, port))现在我们有了新的函数,我们只需要设置一个新的Queue对象并进行一些线程调用。我们将通过portList变量从FOR循环中取出testAndSave调用,并将其替换为以下代码:
q = Queue.Queue()
for port in portList:
t = threading.Thread(target=threader, args=(q, port))
t.deamon = True
t.start()
s = q.get()因此,我们的新脚本总体上如下所示:
import Queue
import threading
import screenshot
import requests
portList = [80,443,2082,2083,2086,2087,2095,2096,8080,8880,8443,9998,4643, 9001,4489]
IP = '127.0.0.1'
http = 'http://'
https = 'https://'
def testAndSave(protocol, portNumber):
url = protocol + IP + ':' + str(portNumber)
try:
r = requests.get(url,timeout=1)
if r.status_code == 200:
print 'Found site on ' + url
s = screenshot.Screenshot()
image = s.get_image(url)
image.save(str(portNumber) + '.png')
except:
pass
def threader(q, port):
q.put(testAndSave(http, port))
q.put(testAndSave(https, port))
q = Queue.Queue()
for port in portList:
t = threading.Thread(target=threader, args=(q, port))
t.deamon = True
t.start()
s = q.get()如果我们现在运行它,我们将得到更快的代码执行,因为 web 请求现在是并行执行的。
您可以尝试进一步扩展脚本,以处理一系列 IP 地址;这在测试内部网络范围时非常方便。
许多工具提供了绘制网站地图的能力,但通常您仅限于输出样式或提供结果的位置。这个用于爬行脚本的底板允许您在短时间内绘制出网站,并能够根据您的意愿对其进行更改。
准备好了吗
为了让这个脚本正常工作,您需要BeautifulSoup库,它可以通过apt命令与apt-get install python-bs4或pip install beautifulsoup4一起安装。就这么简单。
怎么做…
这是我们将使用的脚本:
import urllib2
from bs4 import BeautifulSoup
import sys
urls = []
urls2 = []
tarurl = sys.argv[1]
url = urllib2.urlopen(tarurl).read()
soup = BeautifulSoup(url)
for line in soup.find_all('a'):
newline = line.get('href')
try:
if newline[:4] == "http":
if tarurl in newline:
urls.append(str(newline))
elif newline[:1] == "/":
combline = tarurl+newline urls.append(str(combline)) except:
pass
for uurl in urls:
url = urllib2.urlopen(uurl).read()
soup = BeautifulSoup(url)
for line in soup.find_all('a'):
newline = line.get('href')
try:
if newline[:4] == "http":
if tarurl in newline:
urls2.append(str(newline))
elif newline[:1] == "/":
combline = tarurl+newline
urls2.append(str(combline))
except:
pass
urls3 = set(urls2)
for value in urls3:
print value它是如何工作的…
我们首先导入必要的库,并创建两个空列表,称为urls和urls2。这将使我们能够运行两次爬行过程。接下来,我们设置要添加的输入,作为从命令行运行的脚本的附录。它的运行方式如下:
$ python spider.py http://www.packtpub.com
然后我们打开提供的url变量并将其传递给beautifulsoup工具:
url = urllib2.urlopen(tarurl).read()
soup = BeautifulSoup(url) beautifulsoup工具将内容拆分为多个部分,只允许我们拉取想要的部分:
for line in soup.find_all('a'):
newline = line.get('href') 然后,我们提取 HTML 中标记为标记的所有内容,并获取标记中指定为href的元素。这允许我们获取页面中列出的所有 URL。
下一节将处理相对链接和绝对链接。如果链接是相对的,则以斜线开头,表示它是 web 服务器本地托管的页面。如果链接是绝对链接,则它包含包括域在内的完整地址。我们使用以下代码所做的是确保我们可以作为外部用户打开找到的所有链接,并将它们列为绝对链接:
if newline[:4] == "http":
if tarurl in newline:
urls.append(str(newline))
elif newline[:1] == "/":
combline = tarurl+newline urls.append(str(combline))然后,我们通过迭代原始url列表中的每个元素,再次使用该页面中标识的urls列表重复该过程:
for uurl in urls:除了参考列表和变量中的更改外,代码保持不变。
我们将两个列表合并,最后,为了便于输出,我们将urls列表的完整列表转换为一个集合。这将从列表中删除重复项,并允许我们整齐地输出它。我们遍历集合中的值并逐个输出它们。
还有更多…
此工具可以与本书前面和后面介绍的任何功能相结合。它可以绑定到使用 QtWeb 工具包获取网站截图,从而允许您获取每个页面的截图。您可以将其绑定到第 2 章、枚举中的电子邮件地址查找器,以从每个页面获取电子邮件地址,或者您也可以使用此简单技术来映射网页。
脚本可以很容易地更改为添加深度级别,从当前的 2 个链接深度级别更改为系统参数设置的任何值。可以将输出更改为在每个页面上添加 URL,或将其转换为 CSV,以允许您将漏洞映射到页面以便于标记。