- Python Web 渗透测试
- Python Web 渗透秘籍
- Python 高效渗透测试
 PDF电子书集合
PDF电子书集合
Python Web 头操作详解
在本章中,我们将介绍以下主题:
渗透测试 web 服务器的一个关键领域是深入关注服务器处理请求和提供响应的能力。如果您正在对标准 web 服务器部署(例如 Apache 或 Nginx)进行渗透测试,那么您将希望集中精力破坏已部署的配置,并枚举/操作站点内容。如果您正在进行渗透测试的是一个定制的 web 服务器,那么最好随身携带一份 HTTP RFC 副本(可在获得)http://tools.ietf.org/html/rfc7231 ),并额外测试 web 服务器如何处理损坏的数据包或意外请求。
本章将重点介绍如何创建操作请求的方法,以揭示底层 web 技术并解析响应,从而突出常见问题或关键领域以供进一步测试。
开始测试 web 服务器的一个好地方是在HTTP请求的开头,通过枚举HTTP方法。HTTP方法由客户端发送,并向 web 服务器指示客户端期望的操作类型。
按照 RFC 7231 中的规定,所有 web 服务器必须支持GET和HEAD方法,并且所有其他方法都是可选的。除了最初的GET和HEAD方法之外,还有很多常用方法,因此这是一个很好的测试重点,因为每台服务器都将以不同的方式处理请求和发送响应。
值得注意的一个有趣的HTTP方法是TRACE,因为它的可用性导致跨站点跟踪(XST)。TRACE 是一种回送测试,基本上将收到的请求回送给用户。这意味着它可以用于跨站点脚本攻击(在本例中称为跨站点跟踪)。为此,攻击者让受害者发送一个TRACE请求,并在主体中包含 JavaScript 负载,然后在返回时在本地执行该请求。现代浏览器现在内置了防御系统,通过阻止通过 JavaScript 发出的跟踪请求来保护用户免受这些攻击,因此这种技术现在只适用于旧浏览器或利用 Java 或 Flash 等其他技术。
怎么做…
在这个方法中,我们将连接到目标 web 服务器,并尝试枚举各种可用的HTTP方法。我们还将寻找TRACE方法的存在,并突出显示它(如果可用):
import requests
verbs = ['GET', 'POST', 'PUT', 'DELETE', 'OPTIONS', 'TRACE', 'TEST']
for verb in verbs:
req = requests.request(verb, 'http://packtpub.com')
print verb, req.status_code, req.reason
if verb == 'TRACE' and 'TRACE / HTTP/1.1' in req.text:
print 'Possible Cross Site Tracing vulnerability found'它是如何工作的…
第一行导入请求库;这将在本节中大量使用:
import requests下一行创建了我们将要发送的HTTP方法数组。请注意标准的方法-GET、POST、PUT、HEAD、DELETE,和OPTIONS-然后是非标准的TEST方法。添加此选项是为了检查服务器如何处理其不期望的输入。一些 web 框架将非标准动词视为GET请求并相应地响应。这是绕过防火墙的一个好方法,因为防火墙可能有一个严格的方法列表来匹配,而不是处理来自意外方法的请求:
verbs = ['GET', 'POST', 'PUT', 'HEAD', 'DELETE', 'OPTIONS', 'TRACE', 'CONNECT', 'TEST']接下来是脚本的主循环。这部分发送 HTTP 数据包;在本例中,指向目标http://packtpub.comweb 服务器。它打印出方法和响应状态代码以及原因:
for verb in verbs:
req = requests.request(verb, 'http://packtpub.com')
print verb, req.status_code, req.reason最后,有一段代码专门测试 XST:
if verb == 'TRACE' and 'TRACE / HTTP/1.1' in req.text:
print 'Possible Cross Site Tracing vulnerability found'此代码在发送TRACE调用时检查服务器响应,检查响应是否包含请求文本。
运行脚本将提供以下输出:
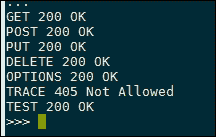
在这里,我们可以看到 web 服务器正确地处理了前五个请求,为所有这些方法返回了一个200 OK响应。TRACE响应返回405 Not Allowed,表明 web 服务器已明确拒绝该响应。目标服务器的一个有趣之处在于,它为TEST方法返回200 OK响应。这意味着服务器正在以不同的方法处理TEST请求;例如,它将其视为GET请求。如前所述,这是绕过某些防火墙的好方法,因为它们可能不会处理意外的TEST方法。
还有更多…
在这个方法中,我们展示了如何测试目标 web 服务器的 XST 漏洞,并测试它如何处理各种HTTP方法。该脚本可以通过扩展示例HTTP方法数组来进一步扩展,以包括各种其他有效和无效数据值;也许您可以尝试发送 Unicode 数据来测试 web 服务器如何处理意外的字符集,或者发送很长的 HTTP 方法,并测试自定义 web 服务器中的缓冲区溢出。这些数据的一个很好的来源是查看第 3 章、漏洞识别中的模糊脚本,例如,使用 Mozilla FuzzDB 的有效负载。
我们将关注的 HTTP 协议的下一部分是 HTTP 头。在 web 服务器的请求和响应中都可以找到,它们在客户端和服务器之间传递额外的信息。任何有额外数据的区域都是解析服务器信息和查找潜在问题的好地方。
怎么做…
以下是一个简单的标头抓取脚本,它将解析响应标头,以尝试识别正在使用的 web 服务器技术:
import requests
req = requests.get('http://packtpub.com')
headers = ['Server', 'Date', 'Via', 'X-Powered-By', 'X-Country-Code']
for header in headers:
try:
result = req.headers[header]
print '%s: %s' % (header, result)
except Exception, error:
print '%s: Not found' % header它是如何工作的…
脚本的第一部分通过熟悉的requests库向目标 web 服务器发出一个简单的GET请求:
req = requests.get('http://packtpub.com')接下来,我们将生成一个要查找的标题数组:
headers = ['Server', 'Date', 'Via', 'X-Powered-By', 'X-Country- Code']在此脚本中,我们在主代码周围使用了 try/except 块:
try:
result = req.headers[header]
print '%s: %s' % (header, result)
except:
print '%s: Not found' % header我们需要处理这个错误,因为头不是必需的;因此,如果我们试图从数组中检索不存在的头的键,Python 将引发异常。为了克服这个问题,如果响应中没有指定的头,我们只需打印出Not found。
以下是本例中针对目标服务器运行脚本的输出截图:
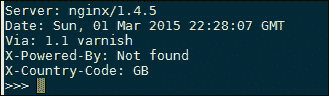
第一个输出行显示Server标题,该标题显示底层 web 服务器技术。这是一个查找易受攻击的 web 服务器版本的好地方,但请注意,可以禁用并欺骗此头,因此不要明确依赖此来猜测目标服务器平台。
Date标头包含有用的信息,可用于猜测服务器的位置。例如,您可以计算出相对于本地时区的时差,以粗略指示其位置。
Via头由传出和传入的代理使用,并将显示代理名称,在本例中为1.1 varnish。
X-Powered-By是 PHP 等常见 web 框架中使用的标准标头。默认的 PHP 安装将使用 PHP 和版本号进行响应,使其成为另一个很好的侦察目标。
最后一行打印X-Country-Code短代码,这是另一条有用的信息,可以识别服务器所在的位置。
请注意,所有这些头文件都可以在服务器端设置或覆盖,因此不要明确依赖这些信息,并且要小心直接解析来自远程服务器的数据;甚至这些头也可能包含恶意值。
还有更多…
此脚本当前包含服务器版本,但可以进一步扩展以查询在线 CVE 数据库,如https://cve.mitre.org/cve/ ,查找影响 web 服务器版本的漏洞。
另一种可以用来增加指纹识别可信度的技术是检查响应头的顺序。例如,Microsoft IIS 在Date头之前返回Server头,而 Apache 返回Date,然后返回Server。这种稍有不同的排序可用于验证您可能从该配方中的标头值推断出的任何服务器版本。
我们已经看到了 HTTP 响应如何成为枚举底层 web 框架的一个重要信息源。我们现在将通过使用HTTP头信息来测试不安全的 web 服务器配置,并标记任何可能导致漏洞的内容,从而将此提升到下一个级别。
准备好了吗
对于这个方法,您将需要一个 URL 列表,以测试不安全的头。将这些内容保存到一个名为urls.txt的文本文件中,每个 URL 都位于新的一行,与您的食谱一起。
怎么做…
以下代码将突出显示从每个目标 URL 的 HTTP 响应中接收到的任何易受攻击的头:
import requests
urls = open("urls.txt", "r")
for url in urls:
url = url.strip()
req = requests.get(url)
print url, 'report:'
try:
xssprotect = req.headers['X-XSS-Protection']
if xssprotect != '1; mode=block':
print 'X-XSS-Protection not set properly, XSS may be possible:', xssprotect
except:
print 'X-XSS-Protection not set, XSS may be possible'
try:
contenttype = req.headers['X-Content-Type-Options']
if contenttype != 'nosniff':
print 'X-Content-Type-Options not set properly:', contenttype
except:
print 'X-Content-Type-Options not set'
try:
hsts = req.headers['Strict-Transport-Security']
except:
print 'HSTS header not set, MITM attacks may be possible'
try:
csp = req.headers['Content-Security-Policy']
print 'Content-Security-Policy set:', csp
except:
print 'Content-Security-Policy missing'
print '----'它是如何工作的…
此配方配置用于测试多个站点,因此第一部分从文本文件读入 URL 并打印出当前目标:
urls = open("urls.txt", "r")
for url in urls:
url = url.strip()
req = requests.get(url)
print url, 'report:'然后在 try/except 块内测试每个标头。这类似于上一个配方,其中需要此编码样式,因为标题不是必需的。如果我们试图为不存在的头引用一个键,Python 将引发一个异常。
第一个X-XSS-Protection头应设置为1; mode=block,以便在浏览器中启用 XSS 保护。如果标题与该格式不明确匹配或未设置,脚本将打印警告:
try:
xssprotect = req.headers['X-XSS-Protection']
if 'xssprotect' != '1; mode=block':
print 'X-XSS-Protection not set properly, XSS may be possible'
except:
print 'X-XSS-Protection not set, XSS may be possible'下一个X-Content-Type-Options头应该设置为nosniff,以防止 MIME 类型混淆。MIME 类型指定目标资源的内容,例如,text/plain 表示远程资源应该是文本文件。如果未指定资源的 MIME 类型,某些 web 浏览器会尝试猜测该类型。这可能导致跨站点脚本攻击;如果资源包含恶意脚本,但它仅指示为纯文本文件,则它可能会绕过内容筛选器并被执行。如果未设置标题或响应与nosniff不明确匹配,此检查将打印警告:
try:
contenttype = req.headers['X-Content-Type-Options']
if contenttype != 'nosniff':
print 'X-Content-Type-Options not set properly'
except:
print 'X-Content-Type-Options not set'下一个 Ty0T0-报头用于强制在 HTTPS 信道上进行通信,以防止 Apple T1。缺少此标头意味着 MITM 攻击可能会将通信通道降级为 HTTP:
try:
hsts = req.headers['Strict-Transport-Security']
except:
print 'HSTS header not set, MITM attacks may be possible'最后一个Content-Security-Policy标题用于限制可以加载到网页上的资源类型,例如,限制 JavaScript 可以运行的位置:
try:
csp = req.headers['Content-Security-Policy']
print 'Content-Security-Policy set:', csp
except:
print 'Content-Security-Policy missing'配方的输出显示在以下屏幕截图中:
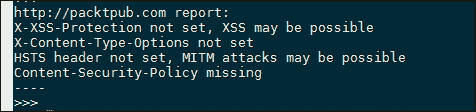
许多网站使用 HTTP 基本身份验证来限制对内容的访问。这在路由器等嵌入式设备中尤其普遍。Pythonrequests库内置了对基本身份验证的支持,为创建身份验证暴力脚本提供了一种简单的方法。
准备好了吗
在创建此配方之前,您需要一个密码列表来尝试进行身份验证。创建一个名为passwords.txt的本地文本文件,将每个密码放在新行上。查看第 2 章、枚举中的暴力强制密码,获取在线资源中的密码列表。此外,请花一些时间查看目标服务器,因为您需要知道它如何响应失败的登录请求,以便我们能够区分暴力何时起作用。
怎么做…
以下代码将尝试通过基本身份验证强行进入网站:
import requests
from requests.auth import HTTPBasicAuth
with open('passwords.txt') as passwords:
for password in passwords.readlines():
password = password.strip()
req = requests.get('http://packtpub.com/admin_login.html', auth=HTTPBasicAuth('admin', password))
if req.status_code == 401:
print password, 'failed.'
elif req.status_code == 200:
print 'Login successful, password:', password
break
else:
print 'Error occurred with', password
break它是如何工作的…
此脚本的第一部分逐行读取密码列表。然后向登录页面发送 HTTPGET请求:
req = requests.get('http://packtpub.com/admin_login.html', auth=HTTPBasicAuth('admin', password))此请求有一个额外的auth参数,其中包含用户名admin和从passwords.txt文件读取的password。发送带有基本Authorization头的 HTTP 请求时,原始数据如下所示:
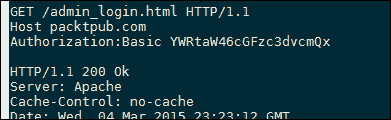
注意,在Authorization报头中,数据以编码格式发送,例如YWRtaW46cGFzc3dvcmQx。这是username:password的base64编码形式的用户名和密码;requests.auth.HTTPBasicAuth类只是为我们做这个转换。这可以通过使用base64库进行验证,如以下屏幕截图所示:

了解这些信息意味着您仍然可以在没有外部请求库的情况下运行脚本;相反,它使用base64默认库手动创建Authorization头。
以下是暴力脚本的屏幕截图:
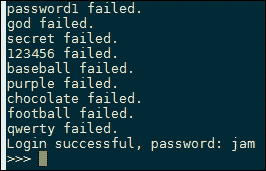
还有更多…
在这个示例中,我们在授权请求中使用了一个固定的 admin 用户名,这是众所周知的。如果这是未知的,您可以创建一个username.txt文本文件,并循环遍历其中的每一行,就像我们对密码文本文件所做的那样。请注意,这是一个慢得多的过程,会向目标站点创建大量 HTTP 请求,这很可能会将您列入黑名单,除非您实施速率限制。
另见
查看第 2 章、枚举中的检查用户名有效性和强制用户名配方,了解有关用户名和密码组合的更多想法。
点击劫持是一种欺骗用户在目标站点上执行操作而不被他们察觉的技术。这是由恶意用户在合法网站的顶部放置一个隐藏的覆盖层来完成的,因此当受害者认为他们正在与合法网站交互时,他们实际上是在单击隐藏的顶部覆盖层上的隐藏项。这种攻击可以通过这样一种方式进行精心设计,即它会导致受害者键入凭据或单击并拖动项目,而不会意识到它们正在受到攻击。这些攻击可以用来攻击银行网站,诱骗受害者转移资金,在社交网站中也很常见,目的是获得更多的关注者或喜欢者,尽管大多数网站现在已经采取了防御措施。
怎么做…
网站可以通过两种主要方式防止点击劫持:一种是设置X-FRAME-OPTIONS标题,告诉浏览器如果网站在一个框架内,就不要呈现该网站;另一种是使用 JavaScript 跳出框架(通常称为框架破坏)。此配方将向您展示如何检测这两种防御,以便您能够识别既没有:
import requests
from ghost import Ghost
import logging
import os
URL = 'http://packtpub.com'
req = requests.get(URL)
try:
xframe = req.headers['x-frame-options']
print 'X-FRAME-OPTIONS:', xframe , 'present, clickjacking not likely possible'
except:
print 'X-FRAME-OPTIONS missing'
print 'Attempting clickjacking...'
html = '''
<html>
<body>
<iframe src="'''+URL+'''" height='600px' width='800px'></iframe>
</body>
</html>'''
html_filename = 'clickjack.html'
f = open(html_filename, 'w+')
f.write(html)
f.close()
log_filename = 'test.log'
fh = logging.FileHandler(log_filename)
ghost = Ghost(log_level=logging.INFO, log_handler=fh)
page, resources = ghost.open(html_filename)
l = open(log_filename, 'r')
if 'forbidden by X-Frame-Options.' in l.read():
print 'Clickjacking mitigated via X-FRAME-OPTIONS'
else:
href = ghost.evaluate('document.location.href')[0]
if html_filename not in href:
print 'Frame busting detected'
else:
print 'Frame busting not detected, page is likely vulnerable to clickjacking'
l.close()
logging.getLogger('ghost').handlers[0].close()
os.unlink(log_filename)
os.unlink(html_filename)它是如何工作的…
这个脚本的第一部分检查第一个点击劫持防御,X-FRAME-OPTIONS标题,就像我们在前面的配方中看到的一样。X-FRAME-OPTIONS取三个值:DENY、SAMEORIGIN或ALLOW-FROM <url>。这些值中的每一个都提供了不同级别的防止点击劫持的保护,因此,在本配方中,我们试图检测是否存在以下缺陷:
try:
xframe = req.headers['x-frame-options']
print 'X-FRAME-OPTIONS:', xframe , 'present, clickjacking not likely possible'
except:
print 'X-FRAME-OPTIONS missing'代码的下一部分创建一个本地 htmlclickjack.html文件,其中包含一些非常简单的 html 代码行,并将它们保存到本地clickjack.html文件中:
html = '''
<html>
<body>
<iframe src="'''+URL+'''" height='600px' width='800px'></iframe>
</body>
</html>'''
html_filename = 'clickjack.html'
f = open(html_filename, 'w+')
f.write(html)
f.close()此 HTML 代码创建一个 iframe,将源设置为目标网站。HTML 文件将加载到 ghost 中,以尝试呈现网站并检测目标网站是否加载到 iframe 中。Ghost 是一个 WebKit 渲染引擎,因此它应该类似于在 Chrome 浏览器中加载站点时会发生的情况。
下一部分设置重影日志以重定向到本地日志文件(默认为打印到stdout:
log_filename = 'test.log'
fh = logging.FileHandler(log_filename)
ghost = Ghost(log_level=logging.INFO, log_handler=fh)下一行在 ghost 中呈现本地 HTML 页面,并包含目标页面请求的任何额外资源:
page, resources = ghost.open(html_filename)然后,我们打开日志文件并检查X-FRAME-OPTIONS错误:
l = open(log_filename, 'r')
if 'forbidden by X-Frame-Options.' in l.read():
print 'Clickjacking mitigated via X-FRAME-OPTIONS'脚本的下一部分检查框架破坏;如果 iframe 有 JavaScript 代码来检测它被加载到 iframe 中,它将跳出框架,导致页面重定向到目标网站。我们可以通过使用ghost.evaluate在 ghost 中执行 JavaScript 并读取当前位置来检测:
href = ghost.evaluate('document.location.href')[0]代码的最后一部分用于清理、关闭任何打开的文件或任何打开的日志处理程序,以及删除临时 HTML 和日志文件:
l.close()
logging.getLogger('ghost').handlers[0].close()
os.unlink(log_filename)
os.unlink(html_filename)如果脚本输出Frame busting not detected, page is likely vulnerable to clickjacking,则目标网站可以在隐藏的 iframe 中呈现,并用于点击劫持攻击。以下屏幕截图显示了来自易受攻击站点的日志示例:
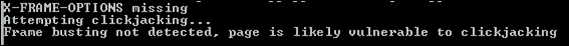
如果在 web 浏览器中查看生成的 clickjack.html 文件,它将确认目标 web 服务器可以加载到 iframe 中,因此容易受到 clickjack 的影响,如以下屏幕截图所示:
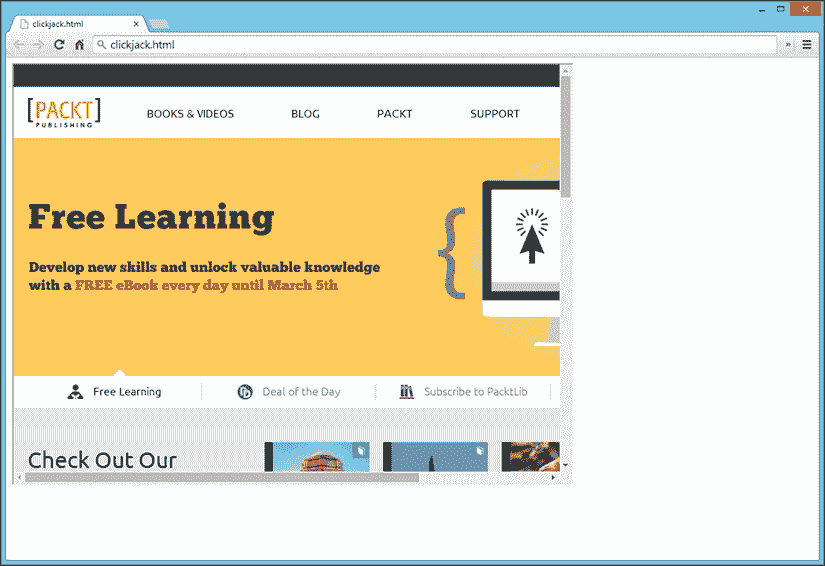
一些网站根据您用来查看内容的浏览器或设备限制访问或显示不同的内容。例如,网站可能会为从 iPhone 浏览的用户显示面向移动的主题,或者向使用旧版本易受攻击的 Internet Explorer 的用户显示警告。这是一个发现漏洞的好地方,因为这些漏洞可能没有经过严格的测试,甚至被开发人员遗忘。
怎么做…
在本食谱中,我们将向您展示如何欺骗您的用户代理,使您在网站上看起来好像在使用不同的设备试图发现替代内容:
import requests
import hashlib
user_agents = { 'Chrome on Windows 8.1' : 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36',
'Safari on iOS' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 8_1_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B466 Safari/600.1.4',
'IE6 on Windows XP' : 'Mozilla/5.0 (Windows; U; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)',
'Googlebot' : 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' }
responses = {}
for name, agent in user_agents.items():
headers = {'User-Agent' : agent}
req = requests.get('http://packtpub.com', headers=headers)
responses[name] = req
md5s = {}
for name, response in responses.items():
md5s[name] = hashlib.md5(response.text.encode('utf- 8')).hexdigest()
for name,md5 in md5s.iteritems():
if name != 'Chrome on Windows 8.1':
if md5 != md5s['Chrome on Windows 8.1']:
print name, 'differs from baseline'
else:
print 'No alternative site found via User-Agent spoofing:', md5它是如何工作的…
我们首先设置一组用户代理,每个密钥都有一个友好的名称:
user_agents = { 'Chrome on Windows 8.1' : 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36',
'Safari on iOS' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 8_1_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B466 Safari/600.1.4',
'IE6 on Windows XP' : 'Mozilla/5.0 (Windows; U; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)',
'Googlebot' : 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' }这里有四个用户代理:Windows8.1 上的 Chrome,iOS 上的 Safari,WindowsXP 上的 InternetExplorer6,最后是 Googlebot。这提供了广泛的浏览器和示例,您希望在每个请求后面找到不同的内容。列表中的最后一个用户代理 Googlebot 是 Google 为其搜索引擎检索数据时发送的爬虫程序。
下一部分循环遍历每个用户代理,并在请求中设置User-Agent头:
responses = {}
for name, agent in user_agents.items():
headers = {'User-Agent' : agent}下一节使用熟悉的请求库发送 HTTP 请求,并使用用户友好的名称作为键将每个响应存储在响应数组中:
req = requests.get('http://www.google.com', headers=headers)
responses[name] = req代码的下一部分创建一个md5s数组,然后遍历响应,获取response.text文件。由此,它生成响应内容的md5散列,并将其存储到md5s数组中:
md5s = {}
for name, response in responses.items():
md5s[name] = hashlib.md5(response.text.encode('utf- 8')).hexdigest()代码的最后一部分遍历md5s数组,并将每个项目与原始基线请求进行比较,在本配方Chrome on Windows 8.1中:
for name,md5 in md5s.iteritems():
if name != 'Chrome on Windows 8.1':
if md5 != md5s['Chrome on Windows 8.1']:
print name, 'differs from baseline'
else:
print 'No alternative site found via User-Agent spoofing:', md5我们对响应文本进行了散列处理,以使生成的数组保持较小,从而减少内存占用。您可以通过内容直接比较每个响应,但这样会比较慢,并且需要使用更多内存来处理。
如果 web 服务器的响应与 Windows 8.1 上的 Chrome 基线响应不同,此脚本将打印出用户代理友好名称,如以下屏幕截图所示:

另见
此配方基于能够操作 HTTP 请求中的头。查看第 3 章、漏洞识别中的基于标头的跨站点脚本编制和Shellshock checking部分,了解更多可传递到标头的数据示例。
HTTP 协议下一个感兴趣的主题是 cookies。由于 HTTP 是一种无状态协议,Cookie 提供了一种在客户端存储持久数据的方法。这允许 web 服务器通过在会话长度内将数据持久化到 cookie 来进行会话管理。
Cookie 是在 HTTP 响应中使用Set-Cookie头从 web 服务器设置的。然后通过Cookie头将它们发送回服务器。本食谱将介绍如何审核网站设置的 cookies,以验证它们是否具有安全属性。
怎么做…
以下是枚举目标站点上设置的每个 cookie 并标记存在的任何不安全设置的方法:
import requests
req = requests.get('http://www.packtpub.com')
for cookie in req.cookies:
print 'Name:', cookie.name
print 'Value:', cookie.value
if not cookie.secure:
cookie.secure = '\x1b[31mFalse\x1b[39;49m'
print 'Secure:', cookie.secure
if 'httponly' in cookie._rest.keys():
cookie.httponly = 'True'
else:
cookie.httponly = '\x1b[31mFalse\x1b[39;49m'
print 'HTTPOnly:', cookie.httponly
if cookie.domain_initial_dot:
cookie.domain_initial_dot = '\x1b[31mTrue\x1b[39;49m'
print 'Loosly defined domain:', cookie.domain_initial_dot, '\n'它是如何工作的…
我们枚举从 web 服务器发送的每个 cookie 并检查它们的属性。前两个属性是 cookie 的name和value:
print 'Name:', cookie.name
print 'Value:', cookie.value然后检查 cookie 上的secure标志:
if not cookie.secure:
cookie.secure = '\x1b[31mFalse\x1b[39;49m'
print 'Secure:', cookie.securecookies 上的Secure标志表示它仅通过 HTTPS 发送。这对于用于身份验证的 cookie 是很好的,因为这意味着,例如,如果有人正在监视开放的网络流量,就不能通过网络嗅探 cookie。
还要注意,\x1b[31m代码是一种特殊的 ANSI 转义代码,用于更改终端字体的颜色。这里,我们用红色突出显示了不安全的标题。\x1b[39;49m代码将颜色重置回默认值。更多信息,请参见 ANSI 上的维基百科页面http://en.wikipedia.org/wiki/ANSI_escape_code 。
下一步检查的是httponly属性:
if 'httponly' in cookie._rest.keys():
cookie.httponly = 'True'
else:
cookie.httponly = '\x1b[31mFalse\x1b[39;49m'
print 'HTTPOnly:', cookie.httponly如果设置为True,则表示 JavaScript 无法访问 cookie 的内容,并将其发送到浏览器,只能由浏览器读取。这是用来抵御 XSS 尝试的,因此在进行渗透测试时,缺少此 cookie 属性是一件好事。
我们最后检查 cookie 中的域,看看它是否以点开头:
if cookie.domain_initial_dot:
cookie.domain_initial_dot = '\x1b[31mTrue\x1b[39;49m'
print 'Loosly defined domain:', cookie.domain_initial_dot, '\n'如果 cookie 的domain属性以点开头,则表示 cookie 跨所有子域使用,因此可能超出预期范围。
以下屏幕截图显示了目标网站的不安全标志如何以红色突出显示:
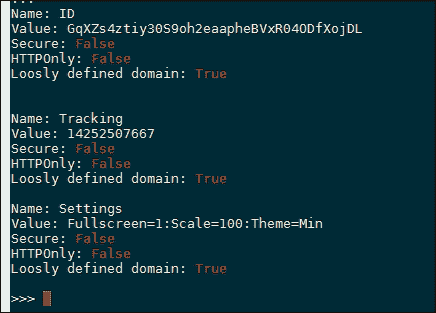
还有更多…
我们之前已经看到了如何通过提取标题来枚举用于服务网站的技术。某些框架也在 cookie 中存储信息,例如,PHP 创建了一个名为PHPSESSION的 cookie,用于存储会话数据。因此,此数据的存在表明使用了 PHP,然后可以进一步枚举服务器,以测试其是否存在已知的 PHP 漏洞。
会话固定是一个依赖于会话 ID 重复使用的漏洞。首先,攻击者必须能够通过在其客户端上设置 cookie 或已经知道受害者会话 ID 的值来强制受害者使用特定会话 ID。然后,当受害者进行身份验证时,客户端上的 cookie 保持不变。因此,攻击者知道会话 ID,现在可以访问受害者的会话。
准备好了吗
此方法需要对目标站点进行一些初始侦察,以确定其如何执行身份验证,例如通过POST请求中的数据或通过基本auth进行验证。它还需要一个有效的用户帐户进行身份验证。
怎么做…
此配方将通过 cookie 注入测试会话固定:
import requests
url = 'http://www.packtpub.com/'
req = requests.get(url)
if req.cookies:
print 'Initial cookie state:', req.cookies
cookie_req = requests.post(url, cookies=req.cookies, auth=('user1', 'supersecretpasswordhere'))
print 'Authenticated cookie state:', cookie_req.cookies
if req.cookies == cookie_req.cookies:
print 'Session fixation vulnerability identified'它是如何工作的…
这个剧本有两个阶段;第一步是向目标网站发送初始get请求,然后显示收到的 cookies:
req = requests.get(url)
print 'Initial cookie state:', req.cookies脚本的第二阶段向目标站点发送另一个请求,这次使用有效的用户凭据进行身份验证:
cookie_req = requests.post(url, cookies=req.cookies, auth=('user1', 'supersecretpasswordhere'))请注意,我们将请求 cookie 设置为我们在前面的初始GET请求中收到的 cookie。
脚本结束时,打印出最终 cookie 状态,并在经过身份验证的 cookie 与初始请求中发送的 cookie 匹配时打印警告:
print 'Authenticated cookie state:', cookie_req.cookies
if req.cookies == cookie_req.cookies:
print 'Session fixation vulnerability identified'还有更多…
Cookie 是另一个由用户控制并由 web 服务器解析的数据源。与标头类似,这使它成为测试 XSS 漏洞的好地方。尝试将 XSS 有效负载添加到 cookie 数据并将其发送到目标服务器,以查看它如何处理数据。请记住,Cookie 可以从 web 服务器后端读入,也可以打印到日志中,因此可以针对日志读取器使用 XSS(例如,如果管理员稍后读取)。