- 入门教程
- 分类教程
- 回归教程
- 聚类教程
- KNN教程
 《Python机器学习入门教程》
《Python机器学习入门教程》 关注我们

分类算法 - 随机森林

随机森林是一种监督学习算法,可用于分类和回归,但是,它主要用于分类问题,众所周知,森林由树木组成,更多树木意味着更坚固的森林。同样,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。它是一种集成方法,比单个决策树要好,因为它可以通过对输出求平均值来减少过度拟合。
随机森林算法
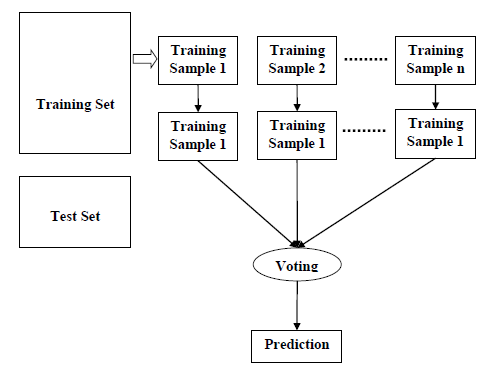
无涯教程可以通过以下步骤来了解随机森林算法的工作原理-
步骤1 - 首先,从给定的数据集中选择随机样本。
步骤2 - 接下来,该算法将为每个样本构造一个决策树。然后它将从每个决策树中获得预测输出。
步骤3 - 在此步骤中,将对每个预测输出进行投票。
步骤4 - 最后,选择投票最多的预测输出作为最终预测输出。
下图将说明其工作方式-
代码实现
首先,从导入必要的Python包开始-
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下来,如下所示从其网络链接下载iris数据集:
path="https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下来,需要为数据集分配列名称,如下所示:
headernames=['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
现在,需要将数据集读取为pandas数据框,如下所示:
dataset=pd.read_csv(path, names=headernames) dataset.head()
| 分隔长度 | 分隔宽度 | 花瓣长度 | 花瓣宽度 | 类 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
数据预处理将在以下脚本行的帮助下完成。
X=dataset.iloc[:, :-1].values y=dataset.iloc[:, 4].values
接下来,无涯教程将数据分为训练和测试拆分。以下代码将数据集分为70%的训练数据和30%的测试数据-
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.30)
接下来,借助sklearn的 RandomForestClassifier 类训练模型,如下所示:
from sklearn.ensemble import RandomForestClassifier classifier=RandomForestClassifier(n_estimators=50) classifier.fit(X_train, y_train)
最后,需要进行预测。可以在以下脚本的帮助下完成-
y_pred=classifier.predict(X_test)
接下来,按如下所示打印输出-
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
运行上面代码输出
Confusion Matrix: [[14 0 0] [ 0 18 1] [ 0 0 12]] Classification Report: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 14 Iris-versicolor 1.00 0.95 0.97 19 Iris-virginica 0.92 1.00 0.96 12 micro avg 0.98 0.98 0.98 45 macro avg 0.97 0.98 0.98 45 weighted avg 0.98 0.98 0.98 45 Accuracy: 0.9777777777777777
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)
好记忆不如烂笔头。留下您的足迹吧 :)