- 入门教程
- 分类教程
- 回归教程
- 聚类教程
- KNN教程
 《Python机器学习入门教程》
《Python机器学习入门教程》 
KNN算法 - 性能指标

无涯教程可以使用各种指标来判断ML算法,分类以及回归算法的性能。必须谨慎选择判断ML性能的指标,因为-
如何测量和比较ML算法的性能完全取决于您选择的指标。
您如何权衡输出中各种特征的重要性将完全受到所选指标的影响。
在前面的章节中,讨论了分类及其算法,在这里,将讨论各种性能指标,这些指标可用于判断分类问题的预测。
混淆矩阵
这是衡量分类问题性能的最简单方法,其中输出可以是两种或多种类型的类。混淆矩阵不过是具有二维的表。 "Actual"和"Predicted",此外,这两个维度均具有"True Positives(TP)","True Negatives(TN)","False Positives(FP)","False Negatives(FN)",如下所示-
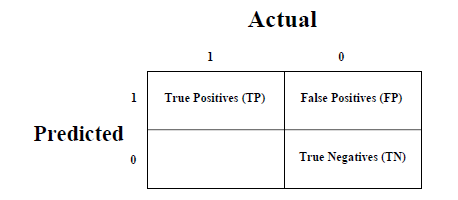
与混淆矩阵相关的术语的解释如下-
True Positives (TP) - 数据点的实际类别和预测类别均为1的情况。
True Negatives (TN) - 数据点的实际类别和预测类别均为0时就是这种情况。
False Positives (FP) - 数据点的实际类别为0,数据点的预测类别为1的情况。
False Negatives (FN) - 数据点的实际类别为1,数据点的预测类别为0的情况。
可以使用sklearn.metrics的confusion_matrix函数来计算分类模型的Confusion Matrix。
分类精度
它是分类算法最常见的性能指标。可以将其定义为做出的正确预测的数量,以其作为所有预测的比率。
Accuracy=TP+TNTP+FP+FN+TN
可以使用 sklearn.metrics 的 accuracy_score 函数来计算分类模型的准确性。
分类报告
该报告由“精确度”,“召回率”,“F1”得分组成。它们解释如下-
精度度
用于文档检索的精度可以定义为ML模型返回的正确文档数,可以借助以下公式轻松地通过混淆矩阵进行计算-
Precision=TPTP+FN
召回率
召回率可以定义为无涯教程的ML模型返回的肯定数,通过以下公式,可以很容易地通过混淆矩阵进行计算。
Recall=TPTP+FN
特异性
与召回相反,特异性可以定义为ML模型返回的阴性数,可以借助以下公式轻松地通过混淆矩阵进行计算-
Specificity=TNTN+FP
F1分数
该分数将提供精确度和查全率的调和平均值,在数学上,F1分数是精度和召回率的加权平均值, F1的最佳值为1,最差的为0。无涯教程可以使用以下公式来计算F1得分-
F1=2∗(precision∗recall)/(precision+recall)
F1分数在准确性和召回率上具有相等的相对贡献。
可以使用sklearn.metrics的category_report函数来获取分类模型的分类报告。
AUC(ROC曲线下的面积)
AUC(曲线下面积)-ROC(reader工作特性)是一种性能指标,基于变化的阈值,用于分类问题。顾名思义,ROC是一条概率曲线,而AUC则测量可分离性。简而言之,AUC-ROC度量标准将告诉有关模型区分类的能力, AUC越高,模型越好。
从数学上讲,它可以通过在各种阈值下绘制TPR(真正率)即灵敏度或召回率与FPR(假正率)即1-Specific来创建。下图显示了ROC,在y轴上具有TPR且在x轴上具有FPR的AUC-
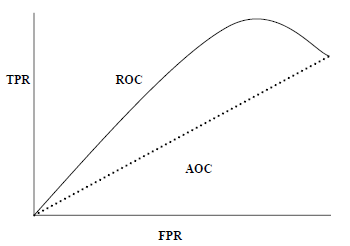
可以使用sklearn.metrics的roc_auc_score函数来计算AUC-ROC。
LOGLOSS(对数损失)
也称为逻辑回归损失或交叉熵损失。它基本上是根据概率估计定义的,并测量分类模型的性能,其中输入是介于0和1之间的概率值。通过精确区分它可以更清楚地理解。
以下是Python中的一个简单示例,它将使无涯教程了解如何在二进制分类模型上使用上述解释的性能指标-
from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.metrics import roc_auc_score from sklearn.metrics import log_loss X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0] Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0] results = confusion_matrix(X_actual, Y_predic) print ('混淆矩阵 :') print(results) print ('Accuracy Score is',accuracy_score(X_actual, Y_predic)) print ('分类报告 : ') print (classification_report(X_actual, Y_predic)) print('AUC-ROC:',roc_auc_score(X_actual, Y_predic)) print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
输出
混淆矩阵 : [[3 3] [1 3]] Accuracy Score is 0.6 分类报告 : precision recall f1-score support 0 0.75 0.50 0.60 6 1 0.50 0.75 0.60 4 micro avg 0.60 0.60 0.60 10 macro avg 0.62 0.62 0.60 10 weighted avg 0.65 0.60 0.60 10 AUC-ROC: 0.625 LOGLOSS Value is 13.815750437193334
回归绩效指标
在前面的章节中,讨论了回归及其算法。在这里,将讨论各种性能指标,这些指标可用于判断回归问题的预测。
平均绝对误差(MAE)
它是用于回归问题的最简单的误差度量,它基本上是预测值与实际值之间的绝对差的平均值之和,简而言之,借助MAE,可以了解预测的错误程度。 MAE不指示模型的方向,即不指示模型的性能不足或性能过高。以下是计算MAE的公式-
MAE=1n∑∣Y-Ŷ ∣
Here,y=Actual 输出 Values
可以使用sklearn.metrics的mean_absolute_error函数来计算MAE。
均方误差(MSE)
MSE就像MAE,但是唯一的区别是,它在对所有实际值和预测值进行求和之前将它们平方和,而不是使用绝对值。可以在以下公式中注意到差异-
MSE=1n∑(Y-Ŷ )
Here,Y=Actual 输出 Values
And = Predicted输出 Values.
可以使用sklearn.metrics的mean_squared_error函数来计算MSE。
R Squared (R2)
R平方度量通常用于说明目的,并提供一组预测输出值与实际输出值之间的优劣程度的指示。
R2=1-1n∑ni=1(Yi-Ŷ i)21n∑ni=1(Yi-Ŷ i)2
在上式中,分子为MSE,分母为Y值的方差。
可以使用sklearn.metrics的r2_score函数来计算R平方值。
以下是Python中的一个简单配方,它将使无涯教程了解如何在回归模型上使用上述解释的性能指标-
来源:LearnFk无涯教程网
from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error X_actual = [5, -1, 2, 10] Y_predic = [3.5, -0.9, 2, 9.9] print ('R Squared =',r2_score(X_actual, Y_predic)) print ('MAE =',mean_absolute_error(X_actual, Y_predic)) print ('MSE =',mean_squared_error(X_actual, Y_predic))
R Squared=0.9656060606060606 MAE=0.42499999999999993 MSE=0.5674999999999999
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)