- Python 物联网入门手册
 PDF电子书集合
PDF电子书集合
Python 划分文本数据并构建文本分类器详解
本章介绍以下主题:
本章介绍构建文本分类器的方法。这包括从数据库中提取重要特征、训练、测试和验证文本分类器。首先,使用常用词训练文本分类器。然后,使用训练好的文本分类器进行预测。构建文本分类器包括使用标记化对数据进行预处理、对文本数据进行词干分析、使用组块划分文本以及构建单词包模型。
分类器单元通常被认为是将数据库划分为不同的类。朴素贝叶斯分类器方案在文献中被广泛考虑用于基于训练模型的文本分离。本章的这一部分首先考虑一个包含关键字的文本数据库;特征提取从文本中提取关键短语并训练分类器系统。然后,执行项频率逆文档频率(tf idf转换来指定单词的重要性。最后,使用分类器系统对输出进行预测和打印。
- 在新的 Python 文件中包含以下行以添加数据集:
from sklearn.datasets import fetch_20newsgroups
category_mapping = {'misc.forsale': 'Sellings', 'rec.motorcycles': 'Motorbikes',
'rec.sport.baseball': 'Baseball', 'sci.crypt': 'Cryptography',
'sci.space': 'OuterSpace'}
training_content = fetch_20newsgroups(subset='train',
categories=category_mapping.keys(), shuffle=True, random_state=7) - 执行特征提取以从文本中提取主要单词:
from sklearn.feature_extraction.text import CountVectorizer
vectorizing = CountVectorizer()
train_counts = vectorizing.fit_transform(training_content.data)
print "nDimensions of training data:", train_counts.shape - 培训分类器:
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
input_content = [
"The curveballs of right handed pitchers tend to curve to the left",
"Caesar cipher is an ancient form of encryption",
"This two-wheeler is really good on slippery roads"
]
tfidf_transformer = TfidfTransformer()
train_tfidf = tfidf_transformer.fit_transform(train_counts) - 实现多项式朴素贝叶斯分类器:
classifier = MultinomialNB().fit(train_tfidf, training_content.target)
input_counts = vectorizing.transform(input_content)
input_tfidf = tfidf_transformer.transform(input_counts) - 预测产出类别:
categories_prediction = classifier.predict(input_tfidf) - 打印输出:
for sentence, category in zip(input_content, categories_prediction):
print 'nInput:', sentence, 'nPredicted category:',
category_mapping[training_content.target_names[category]] 以下屏幕截图提供了基于数据库输入预测对象的示例:
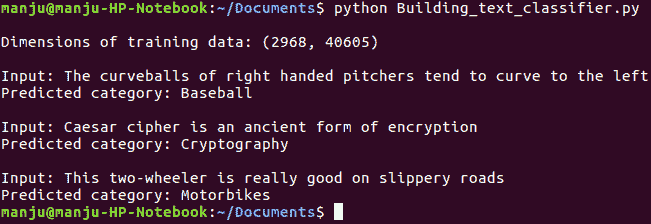
本章的前一节提供了有关实现的分类器部分和一些示例结果的见解。分类器部分基于训练的朴素贝叶斯中先前文本与测试序列中的关键测试之间的比较来工作。
请参阅以下文章:
-
情绪分析算法及应用:在的调查 https://www.sciencedirect.com/science/article/pii/S2090447914000550 。
-
S在线评论的实体分类:使用基于句子的语言模型学习情感预测在的工作原理 https://www.tandfonline.com/doi/abs/10.1080/0952813X.2013.782352?src=recsys &日志代码=teta20。
-
使用产品评论数据和在存在模式的情况下进行句子级情感分析,以了解更多关于推荐系统中使用的各种指标的信息 https://journalofbigdata.springeropen.com/articles/10.1186/s40537-015-0015-2 和;https://link.springer.com/chapter/10.1007/978-3-642-54903-8_1 。
数据预处理包括将现有文本转换为学习算法可接受的信息。
标记化是将文本划分为一组有意义的片段的过程。这些东西叫做代币。
- 引入句子标记化:
from nltk.tokenize import sent_tokenize- 形成新的文本标记器:
tokenize_list_sent = sent_tokenize(text)
print "nSentence tokenizer:"
print tokenize_list_sent - 形成一个新词标记器:
from nltk.tokenize import word_tokenize
print "nWord tokenizer:"
print word_tokenize(text) - 引入一个新的 WordPunct 标记器:
from nltk.tokenize import WordPunctTokenizer
word_punct_tokenizer = WordPunctTokenizer()
print "nWord punct tokenizer:"
print word_punct_tokenizer.tokenize(text) 标记器获得的结果如下所示。它把一个句子分成几个词组:
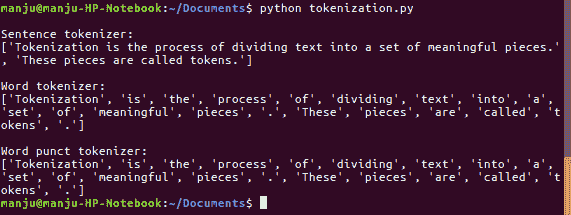
词干分析过程包括为标记器的单词创建一个适当的单词,并减少字母。
- 使用新的 Python 文件初始化词干分析过程:
from nltk.stem.porter import PorterStemmer
from nltk.stem.lancaster import LancasterStemmer
from nltk.stem.snowball import SnowballStemmer - 让我们来描述一些要考虑的词,如下:
words = ['ability', 'baby', 'college', 'playing', 'is', 'dream', 'election', 'beaches', 'image', 'group', 'happy'] - 确定要使用的一组
stemmers:
stemmers = ['PORTER', 'LANCASTER', 'SNOWBALL'] - 为所选的
stemmers初始化必要的任务:
stem_porter = PorterStemmer()
stem_lancaster = LancasterStemmer()
stem_snowball = SnowballStemmer('english') - 设置表格格式以打印结果:
formatted_row = '{:>16}' * (len(stemmers) + 1)
print 'n', formatted_row.format('WORD', *stemmers), 'n' - 反复检查单词列表,并使用所选的
stemmers进行排列:
for word in words:
stem_words = [stem_porter.stem(word),
stem_lancaster.stem(word),
stem_snowball.stem(word)]
print formatted_row.format(word, *stem_words) 从堵塞过程中获得的结果显示在以下屏幕截图中:

分块过程可用于将大文本划分为小的、有意义的单词。
- 使用 Python 开发和导入以下包:
import numpy as np
from nltk.corpus import brown - 描述一个将文本分成块的函数:
# Split a text into chunks
def splitter(content, num_of_words):
words = content.split(' ')
result = [] - 初始化以下编程行以获取分配的变量:
current_count = 0
current_words = []- 使用以下文字开始迭代:
for word in words:
current_words.append(word)
current_count += 1 - 在获得基本字数后,重新组织变量:
if current_count == num_of_words:
result.append(' '.join(current_words))
current_words = []
current_count = 0 - 将块附加到输出变量:
result.append(' '.join(current_words))
return result - 导入 AutoT0 的数据,考虑第一个词:
if __name__=='__main__':
# Read the data from the Brown corpus
content = ' '.join(brown.words()[:10000]) - 描述每个块中的单词大小:
# Number of words in each chunk
num_of_words = 1600 - 启动一对重要变量:
chunks = []
counter = 0 - 调用
splitter函数打印结果:
num_text_chunks = splitter(content, num_of_words)
print "Number of text chunks =", len(num_text_chunks) - 分块后获得的结果显示在以下屏幕截图中:

当处理包含大词的文本文档时,我们需要将它们切换到几种类型的算术描述。我们需要将它们表述为适合机器学习算法。这些算法需要算术信息,以便能够检查数据并提供重要的细节。单词袋程序帮助我们实现这一点。单词包创建一个文本模型,该模型使用文档中的所有单词来发现词汇。之后,它通过构建文本中所有单词的直方图来为每个文本创建模型。
- 通过导入以下文件初始化新的 Python 文件:
import numpy as np
from nltk.corpus import brown
from chunking import splitter - 定义
main功能,从Brown corpus读取输入数据:
if __name__=='__main__':
content = ' '.join(brown.words()[:10000]) - 将文本内容拆分为块:
num_of_words = 2000
num_chunks = []
count = 0
texts_chunk = splitter(content, num_of_words) - 基于这些
text块构建词汇表:
for text in texts_chunk:
num_chunk = {'index': count, 'text': text}
num_chunks.append(num_chunk)
count += 1- 提取文档单词矩阵,有效统计文档中每个单词的发生率:
from sklearn.feature_extraction.text
import CountVectorizer- 提取文档术语
matrix:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=5, max_df=.95)
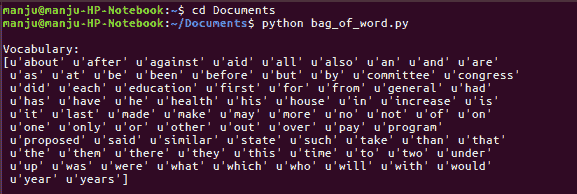
matrix = vectorizer.fit_transform([num_chunk['text'] for num_chunk in num_chunks]) - 提取词汇表并打印:
vocabulary = np.array(vectorizer.get_feature_names())
print "nVocabulary:"
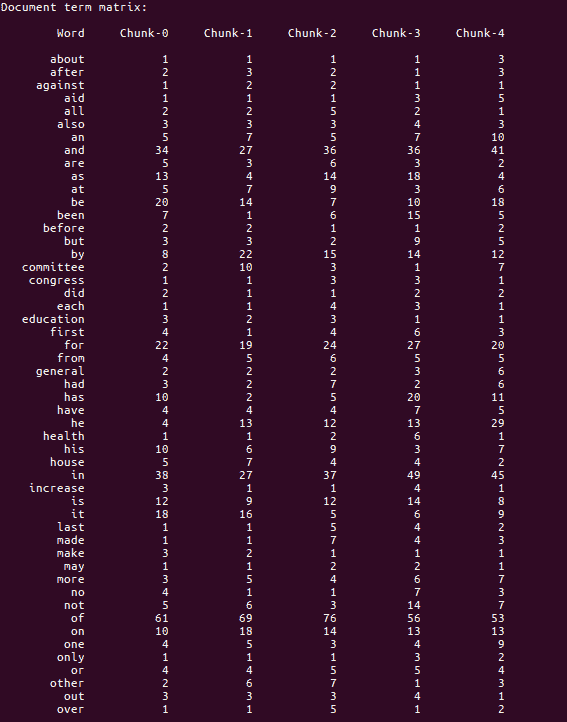
print vocabulary - 打印文档术语
matrix:
print "nDocument term matrix:"
chunks_name = ['Chunk-0', 'Chunk-1', 'Chunk-2', 'Chunk-3', 'Chunk-4']
formatted_row = '{:>12}' * (len(chunks_name) + 1)
print 'n', formatted_row.format('Word', *chunks_name), 'n' - 在整个单词中迭代,并在不同的块中打印每个单词的再现:
for word, item in zip(vocabulary, matrix.T):
# 'item' is a 'csr_matrix' data structure
result = [str(x) for x in item.data]
print formatted_row.format(word, *result)- 执行单词包模型后得到的结果如下所示:
为了了解它在给定句子中的作用,请参考以下内容:
文本分类器用于分析客户情绪,在产品评论中,在互联网上搜索查询时,在社交标签中,预测研究文章的新颖性,等等。