- 入门教程
- ANN教程
- CNN教程
- RNN教程
 《TensorFlow入门教程》
《TensorFlow入门教程》 
CNN - Mnist数据集

MNIST(改良的美国国家标准技术研究院)数据库是一个大型的手写数字或数字数据库,用于训练各种图像处理系统。该数据集还广泛用于机器学习领域的培训和测试。 MNIST数据库中的图像集是NIST的两个数据库的组合:特殊数据库1和特殊数据库3。
MNIST数据集具有 60,000 个训练图像和 10,000 个测试图像。
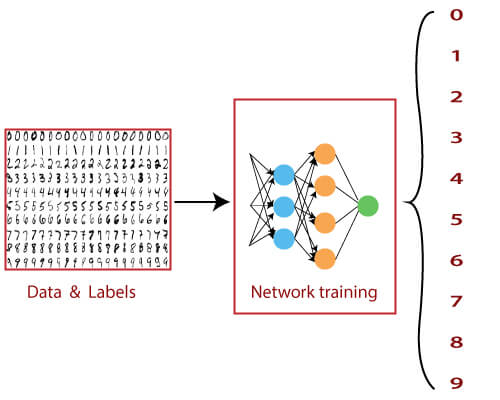
MNIST 数据集可以在线,并且实质上是一个包含各种手写数字的数据库。 MNIST数据集包含大量数据,通常用于证明深度神经网络的真正函数。大脑和眼睛协同工作以识别任何编号的图像。思维是一种强大的工具,并且能够快速对任何图像进行分类。数字的形状太多了,大脑可以轻松识别这些形状并确定数字是多少,但是对于计算机而言,完成相同的任务并不简单。只有一种方法可以做到这一点,那就是使用深度神经网络,它使无涯教程可以训练计算机来有效地对手写数字进行分类。
因此,只处理了在笛卡尔坐标系上包含简单数据点的数据。从开始到现在一直在分发二进制类数据集。而且,当使用多类数据集时,将使用 Softmax activation函数对分类二进制数据集非常有用。并且在0到1之间的值排列中非常有效。sigmoid函数对于多因果数据集无效,为此,使用了能够处理它的softmax activation函数。
MNIST数据集是一个包含10个类的多级数据集,无涯教程可以在其中分类0到9之间的数字。之前使用的数据集与MNIST数据集之间的主要区别是在神经网络中输入MNIST数据的方法。
在感知模型和线性回归模型中,每个数据点均由简单的x和y坐标定义。这意味着输入层需要两个节点才能输入单个数据点。
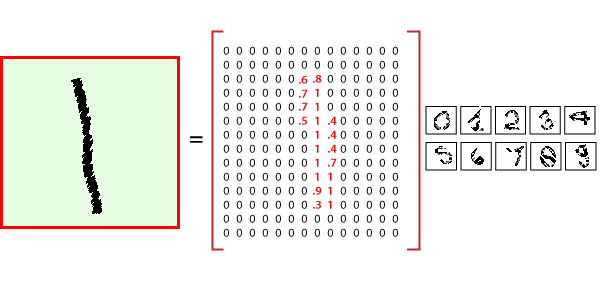
在Mnist DataSet中,单个数据点以图像的形式出现。这些图像包括在 mnist 数据集中是 28 * 28 像素的典型形式,例如穿过水平轴的28像素,28像素交叉垂直轴。这意味着来自Mnist数据库的单个图像总共必须分析784像素。神经网络的输入层具有784个节点来解释这些图像之一。
在这里,将看到如何创建一个函数,该函数是通过查看图像中的每个像素来识别手写数字的模型。然后使用TensorFlow训练模型,以通过查看已标记的数千个示例来预测图像。然后将使用测试数据集检查模型的准确性。
TensorFlow中的MNIST数据集,包含分为三部分的手写数字信息:
- 训练数据(mnist.train) - 55000个数据点
- 验证数据(mnist.validate) - 5000个数据点
- 测试数据(mnist.test) - 10000个数据点
在开始之前,请务必注意,每个数据点都有两个部分:一个图像(x)和一个描述实际图像的相应标签(y),并且每个图像都是28x28的数组,即784个数字。图像的标签是与TensorFlow MNIST图像相对应的0到9之间的数字。要下载和使用MNIST数据集,请使用以下命令:
from tensorflow.examples.Learnfk.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
Softmax回归
TensorFlow MNIST的十种可能性是从0到9。目的是查看图像,并以特定的可能性说给定的图像是特定数字。如果有可能,可以使用Softmax,因为回归可以使得出0到1之间的值,这些值的总和为1。因此方法应该很简单。
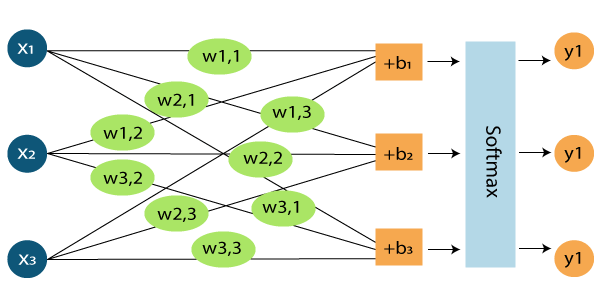
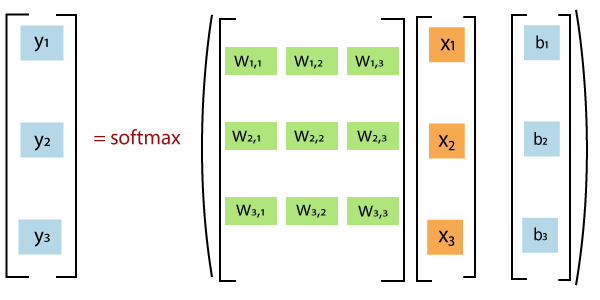
无涯教程将TensorFlow MNIST图像分类为特定类别,然后将其表示为正确与否的概率。现在,它完全取决于特定类中的所有对象,并且可以对像素强度进行加权求和。还需要增加一个误差,以使某些事情更可能独立于输入而已。 Softmax对权重进行归一化并添加假设为负或零的权重。
MNIST数据集
使用TensorFlow MNIST数据集分类的好处是,它使能够描述完全在Python外运行的交互操作的图形。
链接:https://www.learnfk.comhttps://www.learnfk.com/tensorflow/tensorflow-mnist-dataset-in-cnn.html
来源:LearnFk无涯教程网
首先,使用
Import tensorflow as tf
然后,创建一个占位符,当要求库使用以下命令运行计算时将输入该值
x = tf.placeholder (tf.float32, [None, 784])
然后,应该在模型中增加权重和偏差。使用变量,这是一个可修改的张量,在交互操作图中具有作用域。
W= tf.Variable (tf.zeros([784,10])) b= tf.Variable(tf.zeros([10]))
请注意,W的形状为[784,10],因为要通过将784维图像矢量乘以10维证据矢量来生成不同类别的证据可以将b添加到输出中,因为它的形状为[10]。
MNIST练习
通过将特征矩阵乘以权重并向其添加偏差,然后通过softmax函数运行来定义模型。
y = tf.nn.softmax(tf.matmul(x,W) +b)
使用成本函数或均方误差函数来找到结果与实际数据的偏差。误差越小,模型越好。另一个非常常见的函数是在衡量预测效率如何时的交叉熵。该函数如下所述,其中y表示预测,y'是实际分布。通过添加一个占位符来实现它。
y_ =tf.placeholder(tf.float32, [None, 10])
然后定义交叉熵
cross_entropy= tf.reduce_mean(-tf.reduce_sum(y_ *tf.log(y), reduction_indices=[1]))
现在已经成功定义了模型,是时候训练它了。可以借助梯度下降和反向传播来做到这一点。还有许多其他优化算法可用,例如逻辑回归,动态松弛等。无可以将学习速度为0.5的梯度下降用于成本函数优化。
train_step= tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
在训练之前,需要开始一个会话并初始化前创建的变量。
sess= tf.InteractiveSession()
这将启动一个交互式会话,并通过以下方式初始化变量
tf.global_variables_initializer().run()
现在,必须训练网络。应该更改时期数以适合模型。
for _in range (1000): batch_xs, batch_ys =mnist.train.next_batch(100) sess.run(train_step, feed_dict={x:batch_xs, y_:batch_ys})
使用测试数据集检查准确性
通过将结果与测试数据集进行比较来检查准确性。在这里,可以使用tf.argmax函数,该函数使无涯教程知道沿着特定轴的张量中最大值的索引。
correct_prediction = tf.equal (tf.argmax (y, 1), tf.argmax(y_,1))
这给出了布尔值列表,然后在转换为浮点数后取平均值。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
然后,无涯教程可以通过
print (sess.run (accuracy, feed_dict= {x: mnist.test.images, y_:mnist.test.labels}))
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)
Python实战 · 从0到1搭建直播视频平台 -〔Barry〕