- 入门教程
- 基础教程
- 条件语句
- 循环语句
- 函数声明
- 数据结构
- 高级教程
- 数据结构
- 数据结构
- 回归分析
- 数据统计
 《R入门教程》
《R入门教程》 
R 随机森林

随机森林也称为决策树森林。它是流行的基于决策树的集成模型之一。这些模型的准确性高于其他决策树。该算法可用于分类和回归应用。
R允许我们通过提供randomForest包来创建随机森林。 randomForest包提供了randomForest()函数,可帮助我们创建和分析随机森林。 R中的随机森林有以下语法:
randomForest(formula, data)
例子:
让我们开始了解如何使用randomForest包及其函数。为此,我们举一个使用心脏疾病数据集的示例。让我们逐步开始编码部分。
1)第一步,我们必须加载三个必需的库,即ggplot2,cowplot和randomForest。
# 导入 ggplot2, cowplot, and randomForest 库 library(ggplot2) library(cowplot) library(randomForest)
2)现在,我们将使用 http://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data 。然后,我们从该数据集中读取CSV格式的数据,并将其存储在变量中。
#Fetching heart-disease dataset url<-"http://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data" data <- read.csv(url,header=FALSE)
3)现在,我们在head()函数的帮助下打印数据,该函数仅将开始的六行打印为:
# 头部打印六行数据。 head(data)
当我们运行上面的代码时,它将生成以下输出。
链接:https://www.learnfk.comhttps://www.learnfk.com/R/r-random-forest.html
来源:LearnFk无涯教程网
输出:

4)从上面的输出中,很明显没有任何列被标记。现在,我们命名这些列,并使用以下方式标记这些列:
colnames(data) <-c("age","sex","cp","trestbps","chol","fbs","restecg","thalach","exang","oldpeak","slope","ca","thal","hd")
head(data) 输出:
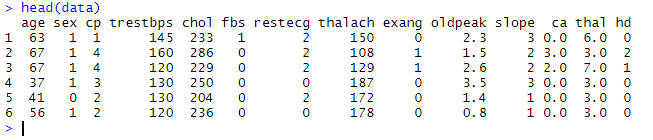
5)让我们借助str()函数检查数据结构以更好地分析数据。
str(data)
输出:

6)在上面的输出中,我们突出显示将在分析中使用的那些列。从输出中很明显,有些列被弄乱了。性别被认为是一个因素,其中0代表"女性",而1代表"男性"。
# 将 ? 赋值为NA data[data=="?"] <- NA # 将性别中的 0 转换为 F,将 1 转换为 M data[data$sex==0,]$sex <-"F" data[data$sex==1,]$sex <-"M" # 将列 tn 转换为因子 data$sex<- as.factor(data$sex) data$cp<- as.factor(data$cp) data$fbs<- as.factor(data$fbs) data$restecg<- as.factor(data$restecg) data$exang<- as.factor(data$exang) data$slope<- as.factor(data$slope) # ca 和 thal 列包含? 而不是 NA。 R 将其视为一列字符串,我们通过以下方式更正此假设telling R that is a column of integers. data$ca<- as.integer(data$ca) data$ca<- as.factor(data$ca) data$thal<- as.integer(data$thal) data$thal<- as.factor(data$thal) # 其中 0 代表健康,1 代表不健康。 data$hd<- ifelse(test=data$hd==0,yes="healthy",no="Unhealthy") data$hd<- as.factor(data$hd) # 检查数据结构 str(data)
输出:

7)现在,我们通过为随机数生成器设置种子来随机采样事物,以便我们可以再现结果。
set.seed(42)
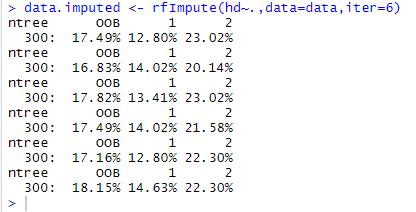
8)NWxt,我们使用rfImput()函数为数据集中的NA赋值。通过以下方式:
data.imputed<- rfImpute(hd~.,datadata=data,iter=6)
输出:
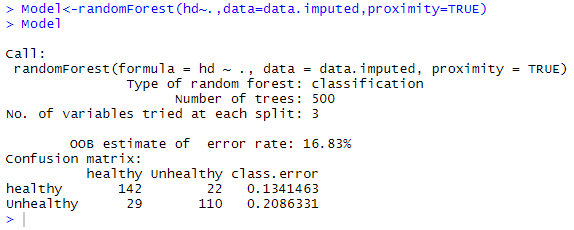
9)现在,我们以下列方式借助randomForest()函数构建适当的随机森林:
Model<-randomForest(hd~.,datadata=data.imputed,ntree=1000,proximity=TRUE)
Model 输出:
10)现在,如果500棵树足以进行最佳分类,我们将绘制错误率。我们创建一个数据帧,它将以以下方式格式化错误率信息:
oob_error_data<- data.frame(Trees=rep(1:nrow(Model$err.rate),times=3),Type=rep(c("OOB","Healthy","Unhealthy"),each=nrow(Model$err.rate)),Error=c(Model$err.rate[,"OOB"],Model$err.rate[,"healthy"],Model$err.rate[,"Unhealthy"])) 11)我们通过以下方式调用ggplot绘制错误率:
ggplot(data=oob_error_data,aes(x=Trees,y=Error))+geom_line(aes(color=Type))
输出:
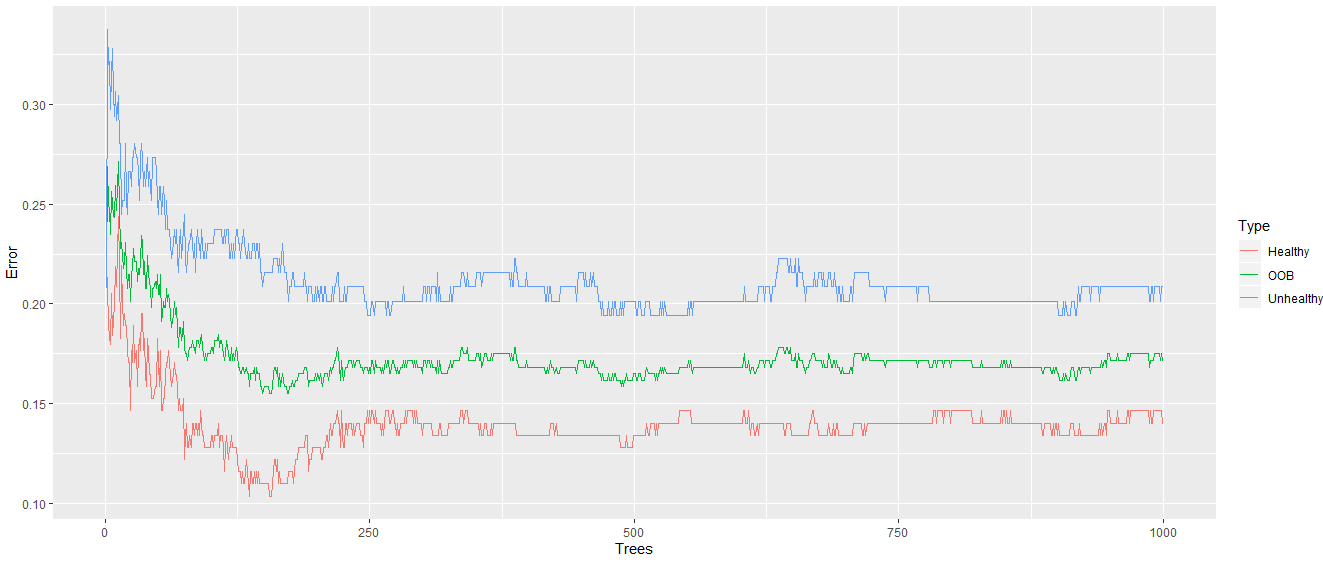
从上面的输出中可以明显看出,当我们的随机森林中有更多的树时,错误率会降低。
12)现在,我们添加1000棵树,并检查错误率会进一步下降吗?因此,我们创建了一个包含1000棵树的随机森林,并像以前一样找到了错误率。
Model<-randomForest(hd~.,datadata=data.imputed,ntree=1000,proximity=TRUE)
Model 输出:
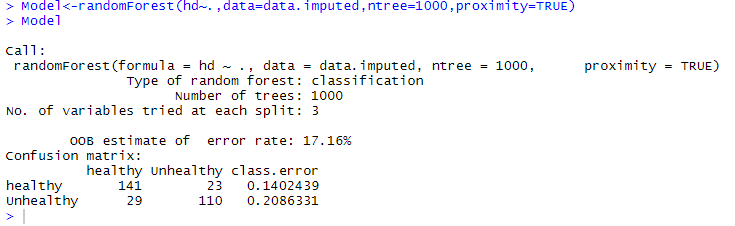
oob_error_data<- data.frame(Trees=rep(1:nrow(Model$err.rate),times=3),Type=rep(c("OOB","Healthy","Unhealthy"),each=nrow(Model$err.rate)),Error=c(Model$err.rate[,"OOB"],Model$err.rate[,"healthy"],Model$err.rate[,"Unhealthy"]))
ggplot(data=oob_error_data,aes(x=Trees,y=Error))+geom_line(aes(color=Type)) 输出:
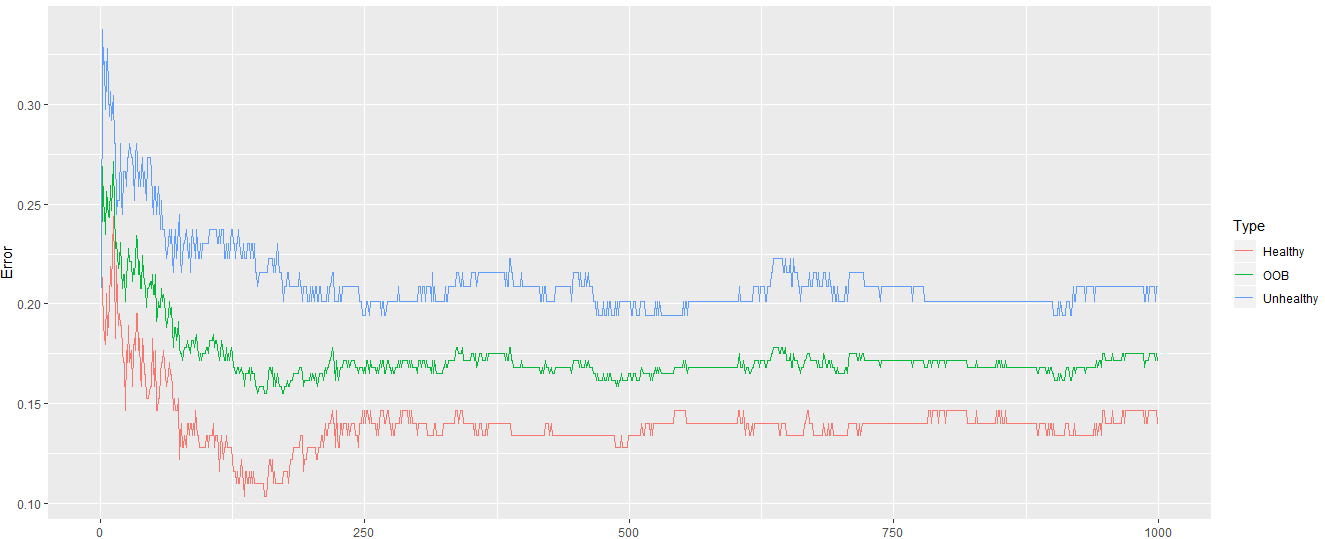
从上面的输出可以明显看出,错误率已稳定下来。
13)现在,我们需要确保我们正在考虑树中每个内部节点的最佳变量数。这将通过以下方式完成:
# 创建一个可以容纳十个值的向量。
oob_values<- vector(length=10)
# 在每一步测试不同数量的变量。
for(i in 1:10){
#构建一个随机森林,用于确定每一步要尝试的变量数量。
temp_model<- randomForest(hd~.,datadata=data.imputed,mtry=i,ntree=1000)
#存储OOB错误率。
oob_values[i] <- temp_model$err.rate[nrow(temp_model$err.rate),1]
}
oob_values 输出:

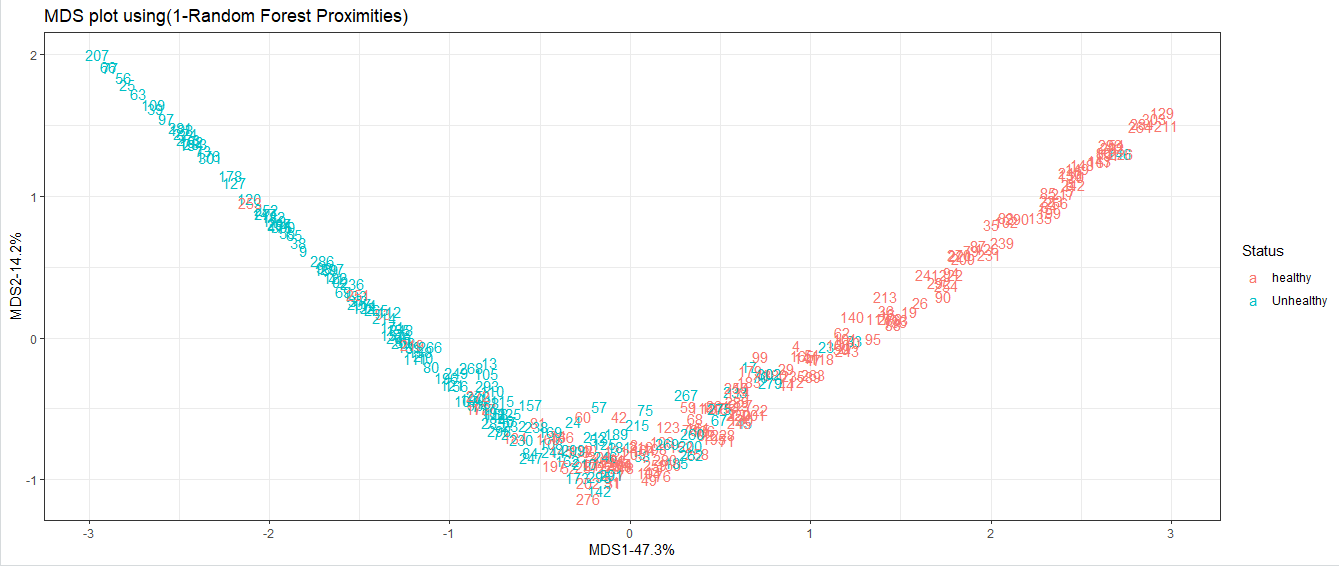
14)现在,我们使用随机森林绘制带有样本的MDS图。这将向我们展示它们之间的相互关系。这将通过以下方式完成:
# 借助 dist() 函数创建距离矩阵。
distance_matrix<- dist(1-Model$proximity)
# 在距离矩阵上运行 cmdscale()。
mds_stuff<- cmdscale(distance_matrix,eig=TRUE,x.ret=TRUE)
# 计算 X 轴和 Y 轴在距离矩阵中的变化百分比。
mds_var_per<- round(mds_stuff$eig/sum(mds_stuff$eig)*100,1)
# 为 ggplot() 函数格式化数据
mds_values<- mds_stuff$points
mds_data<- data.frame(Sample=rownames(mds_values),X=mds_values[,1],Y=mds_values[,2],Status=data.imputed$hd)
# 使用 ggplot() 函数绘制图形。
ggplot(data=mds_data,aes(x=X,y=Y,label=Sample))+geom_text(aes(color=Status))+theme_bw()+xlab(paste("MDS1-",mds_var_per[1],"%",sep=""))+ylab(paste("MDS2-",mds_var_per[2],"%",sep=""))+ggtitle("MDS plot using(1-Random Forest Proximities)") 输出:
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)