- 入门教程
- 数据库管理
- 表与视图
- 增删查改
- 控制语句
- 子句管理
- 条件判断
- 联接操作
- 聚合函数
- 触发器
- 键管理
- 索引管理
- 用户管理
- 权限管理
- 全文搜索
- 进阶教程
 《MySQL入门教程》
《MySQL入门教程》 关注我们

MySQL - GROUP BY语句

MYSQL GROUP BY子句用于从多个记录中收集数据,并将结果按一个或多个列分组。它通常在SELECT语句中使用。
您还可以在分组列上使用一些汇总函数,例如COUNT,SUM,MIN,MAX,AVG等。
语法:
SELECT expression1, expression2, ... expression_n, aggregate_function (expression) FROM tables [WHERE conditions] GROUP BY expression1, expression2, ... expression_n;
参数
expression1,expression2,... expression_n - 它指定未封装在聚合函数中且必须包含在GROUP BY子句中的表达式。
aggregate_function - 它指定一个函数,例如SUM,COUNT,MIN,MAX或AVG等。
WHERE conditions - 这是可选的。它指定了选择记录必须满足的条件。
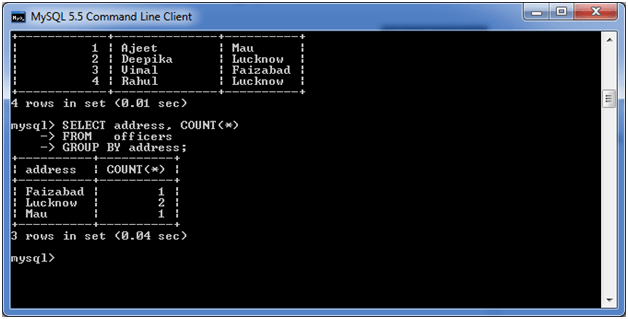
GROUP BY COUNT
考虑一个具有以下记录的名为"officers"表的表。

现在,让无涯教程在列地址中计算重复的城市数。
执行以下查询:
SELECT address, COUNT(*) FROM officers GROUP BY address;
输出:
GROUP BY SUM
无涯教程来看一个表" employees"的表,其中包含以下数据。
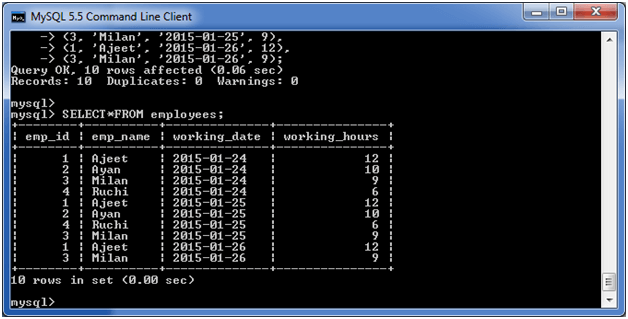
现在,以下查询将使用SUM函数对示例进行GROUP BY,并返回emp_name和每个员工的总工作时间。
执行以下查询:
SELECT emp_name, SUM(working_hours) AS "Total working hours" FROM employees GROUP BY emp_name;
输出:
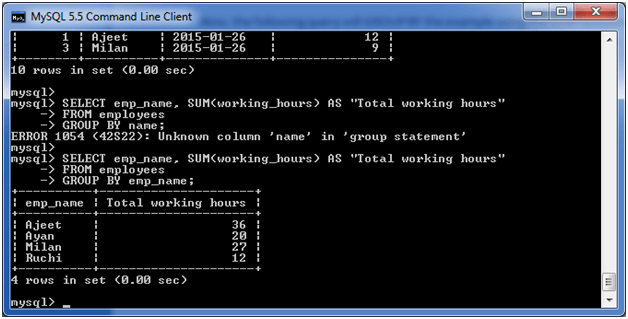
GROUP BY MIN
下面的示例从"employees"表中指定员工的最低工作时间。
执行以下查询:
SELECT emp_name, MIN(working_hours) AS "Minimum working hour" FROM employees GROUP BY emp_name;
输出:
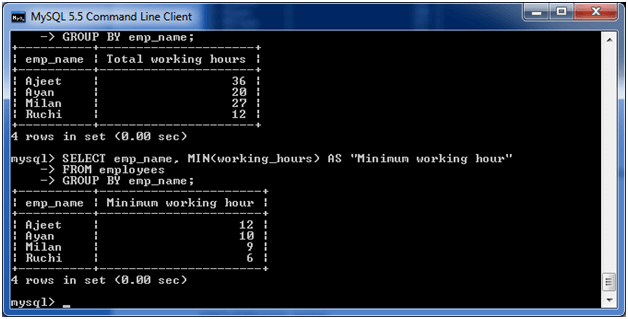
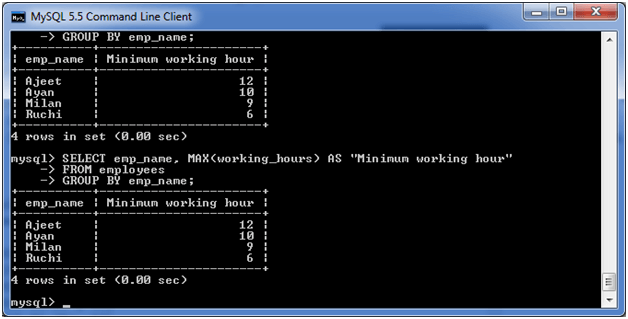
GROUP BY MAX
下面的示例从"employees"表中指定员工的最长工作时间。
执行以下查询:
SELECT emp_name, MAX (working_hours) AS "Minimum working hour" FROM employees GROUP BY emp_name;
输出:
GROUP BY AVG
下面的示例从“ employees”表中指定雇员的平均工作时间。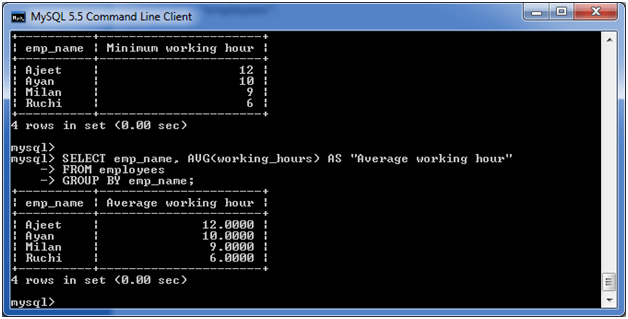
执行以下查询:
SELECT emp_name, AVG(working_hours) AS "Average working hour" FROM employees GROUP BY emp_name;
输出:

祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)
好记忆不如烂笔头。留下您的足迹吧 :)