- 数组与链表
- 堆栈和队列
- 搜索算法
- 排序算法
- 图形结构
- 树结构
- 递归教程
 《数据结构和算法入门教程》
《数据结构和算法入门教程》 关注我们

二分搜索

二分搜索是一种运行时间复杂度为O(log n)的快速搜索算法,这种搜索算法基于分而治之的原理,为了使该算法正常工作,数据应是有序的。
二分搜索通过比较集合中最中间的项来查找特定值,如果发生匹配,则返回值的索引。如果中间项目大于该值,则在中间项目左侧的子数组中搜索该值。否则,将在中间项目右侧的子数组中搜索该值。该进程同样在子数组上继续进行,直到子数组的大小减小到零为止。
二分搜索
为了使二分搜索有效,必须对目标数组进行排序。我们将通过一个图形为例来学习二分搜索的进程,以下是我们的排序数组,让我们假设我们需要使用二分搜索来搜索值31的位置。

首先,我们将使用此公式确定数组的一半-
mid=low + (high - low)/2
这就是0 +(9-0)/ 2=4(4.5的整数值)。因此,4是数组的中间。
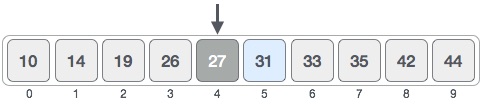
现在我们将存储在位置4的值与要搜索的值进行比较,即31。我们发现位置4的值是27,这不是匹配项。由于该值大于27,并且我们有一个排序数组,因此我们也知道目标值必须在数组的右边。

我们将低点更改为中间+1,然后再次找到新的中间值。
low=mid + 1 mid=low + (high - low)/2
现在我们的新中数是7,我们将存储在位置7的值与目标值31进行比较。
来源:LearnFk无涯教程网
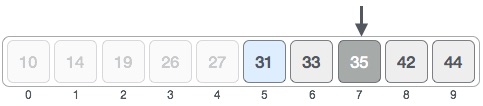
存储在位置7的值不是匹配项,而是大于我们所寻找的值。因此,该值必须位于此位置的左边。

因此,我们再次计算中点。这次是5。
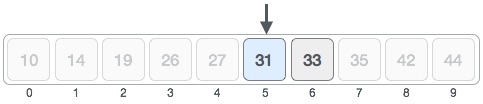
我们将存储在位置5的值与目标值进行比较,我们发现这是匹配的。

我们得出结论,目标值31存储在位置5。
二分搜索将可搜索的项目减半,从而将进行比较的次数减少到非常少的数目。
伪代码
二分搜索算法的伪代码应如下所示-
Procedure binary_search A ← sorted array n ← size of array x ← value to be searched Set lowerBound = 1 Set upperBound = n while x not found if upperBound < lowerBound EXIT: x does not exists. set midPoint = lowerBound + ( upperBound - lowerBound )/2 if A[midPoint] < x set lowerBound = midPoint + 1 if A[midPoint] > x set upperBound = midPoint - 1 if A[midPoint] = x EXIT: x found at location midPoint end while end procedure
C语言代码实现
#include<stdio.h> #define MAX 10 // array of items on which linear search will be conducted. int list[MAX] = { 10, 14, 19, 26, 27, 31, 33, 35, 42, 44 }; int find(int data) { int lo = 0; int hi = MAX - 1; int mid = -1; int comparisons = 1; int index = -1; while(lo <= hi) { printf("\nComparison %d\n" , comparisons ) ; printf("lo : %d, list[%d]=%d\n", lo, lo, list[lo]); printf("hi : %d, list[%d]=%d\n", hi, hi, list[hi]); comparisons++; // probe the mid point mid = lo + (((double)(hi - lo) / (list[hi] - list[lo])) * (data - list[lo])); printf("mid=%d\n",mid); // data found if(list[mid] == data) { index = mid; break; } else { if(list[mid] < data) { // if data is larger, data is in upper half lo = mid + 1; } else { // if data is smaller, data is in lower half hi = mid - 1; } } } printf("\nTotal comparisons made: %d", --comparisons); return index; } int main() { //find location of 33 int location = find(33); // if element was found if(location != -1) printf("\nElement found at location: %d" ,(location+1)); else printf("Element not found."); return 0; }
上面的程序生成以下输出-
Comparison 1 lo : 0, list[0]=10 hi : 9, list[9]=44 mid=6 Total comparisons made: 1 Element found at location: 7
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)
好记忆不如烂笔头。留下您的足迹吧 :)