- Web爬虫
 《Python Web Scraping入门教程》
《Python Web Scraping入门教程》 
Python爬虫 - 单元测试

本章介绍了如何在Python中使用Web爬虫执行测试。。
单元测试
所有标准的Python安装都随附了名为Unittest的Python模块,用于单元测试,无涯教程只需要导入它,剩下的就是unittest.TestCase类的任务,它将执行以下操作:
SetUp和tearDown函数由unittest.TestCase类提供,这些函数可以在每次单元测试之前和之后运行。
它还提供assert语句以允许测试通过或失败。
它将运行以test_开头的所有函数作为单元测试。
在此示例中,将结合使用网络抓取与 unittest ,将测试Wikipedia页面以搜索字符串" Python",基本上,它将进行两次测试,首先是标题页是否与搜索字符串相同(即是否为" Python"),第二次测试是确保该页具有内容div。
首先,将导入所需的Python模块。使用BeautifulSoup进行网页抓取,当然也使用unittest进行测试。
from urllib.request import urlopen from bs4 import BeautifulSoup import unittest
现在,需要定义一个扩展unittest.TestCase的类。全局对象bs将在所有测试之间共享。指定单元测试的函数setUpClass将完成此操作。在这里,将定义两个函数,一个用于测试标题页面,另一个用于测试页面内容。
class Test(unittest.TestCase): bs=None def setUpClass(): url='<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a> Test.bs=BeautifulSoup(urlopen(url), 'html.parser') def test_titleText(self): pageTitle=Test.bs.find('h1').get_text() self.assertEqual('Python', pageTitle); def test_contentExists(self): content=Test.bs.find('div',{'id':'mw-content-text'}) self.assertIsNotNone(content) if __name__ == '__main__': unittest.main()
运行上面的脚本后,将获得以下输出-
---------------------------------------------------------------------- Ran 2 tests in 2.773s OK An exception has occurred, use %tb to see the full traceback. SystemExit: False D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D. warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Selenium测试
讨论一下如何使用Python Selenium进行测试。这也称为Selenium测试。 Python unittest 和 Selenium 并没有太多共同之处。无涯教程知道Selenium会向不同的浏览器发送标准的Python命令,尽管它们的浏览器设计有所不同。回想一下,在先前的章节中已经安装并使用了Selenium。在这里,将在Selenium中创建测试脚本并将其用于自动化。
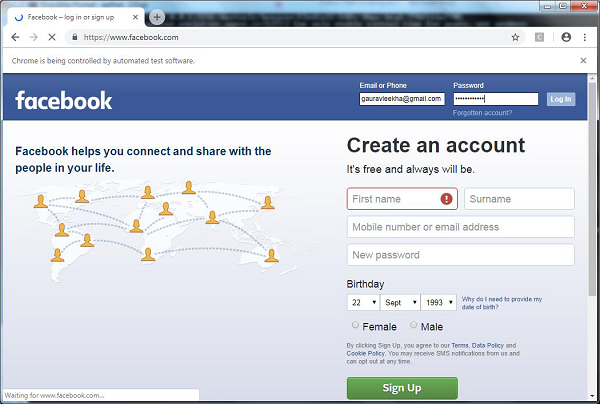
借助下一个Python脚本,正在创建用于Facebook登录页面自动化的测试脚本,您可以修改该示例以自动执行您选择的其他表单和登录但概念是相同的。
首先用于连接到Web浏览器,将从selenium模块导入webdriver-
from selenium import webdriver
现在,需要从Selenium模块导入 Keys 键。
from selenium.webdriver.common.keys import Keys
接下来,需要提供用户名和密码以登录Facebook
user="gauravleekha@gmail.com" pwd=""
接下来,提供指向Chrome浏览器的网络驱动程序的路径。
path=r'C:\\Users\\gaurav\\Desktop\\Chromedriver' driver=webdriver.Chrome(executable_path=path) driver.get("http://www.facebook.com")
现在,将使用assert关键字验证条件。
assert "Facebook" in driver.title
以下代码行中正在将值发送到电子邮件部分。在这里通过ID进行搜索,但是可以通过 driver.find_element_by_name(" email")的名称进行搜索。
element=driver.find_element_by_id("email") element.send_keys(user)
以下代码行的帮助下,无涯教程将值发送到密码部分。在这里,通过ID进行搜索,但可以通过 driver.find_element_by_name(" pass")的名称进行搜索。
element=driver.find_element_by_id("pass") element.send_keys(pwd)
在电子邮件和密码字段中插入值之后,下一行代码用于按Enter/login。
element.send_keys(Keys.RETURN)
现在,将关闭浏览器。
driver.close()
运行上述脚本后,将打开Chrome网络浏览器,您会看到正在插入电子邮件和密码,然后单击登录按钮。
来源:LearnFk无涯教程网
Selenium单元测试
但是,如果无涯教程可以将两者结合在一起,该怎么办?可以将Selenium导入Python单元测试中,并充分利用两者。Selenium可以用来获取有关网站的信息,而单元测试可以判断该信息是否符合通过测试的标准。
例如,通过结合以下两种方法来重写上述Python脚本,以实现Facebook登录的自动化-
import unittest from selenium import webdriver class InputFormsCheck(unittest.TestCase): def setUp(self): self.driver=webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver') def test_singleInputField(self): user="gauravleekha@gmail.com" pwd="" pageUrl="http://www.facebook.com" driver=self.driver driver.maximize_window() driver.get(pageUrl) assert "Facebook" in driver.title elem=driver.find_element_by_id("email") elem.send_keys(user) elem=driver.find_element_by_id("pass") elem.send_keys(pwd) elem.send_keys(Keys.RETURN) def tearDown(self): self.driver.close() if __name__ == "__main__": unittest.main()
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)