- 入门教程
- ANN教程
- CNN教程
- RNN教程
 《TensorFlow入门教程》
《TensorFlow入门教程》 
人工神经网络

神经网络或人工神经网络(ANN)的建模与人脑相同。人脑具有思考和分析特定情况下的任何任务的思想。
但是机器怎么能想一想?为此,设计了人工大脑被称为神经网络。神经网络是组成的许多<强大的>感知器。
感知器是一个单层神经网络。它是二元分类器,是监督学习的一部分。人工神经网络中生物神经元的简单模型称为感知器。
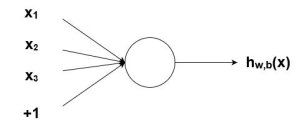
人工神经元具有输入和输出。
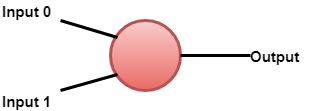
感知器模型的数学表示。
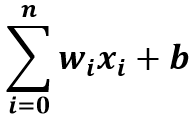
人脑具有用于传递信息的神经元,类似地,神经网络也具有执行相同任务的节点。
神经网络基于生物神经网络的结构和函数。神经网络本身根据输入和输出进行更改或学习。流经系统的信息由于其学习和改进特性而影响了人工神经网络的结构。
神经网络也定义为:
一个由几个简单的,高度互连的处理元素组成的计算系统,这些处理元素通过其对外部输入的动态状态响应来处理信息。
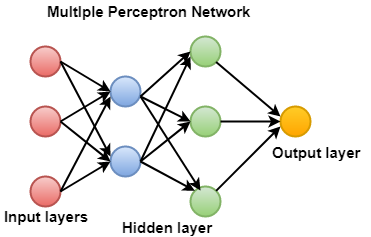
神经网络可以由多个感知器组成。如果有三层-
- 输入层:输入图层是来自数据的实际值。
- 隐藏层:隐藏图层是在输入和输出图层之间,其中三个或更多层是深网络。
- 输出层:它是输出的最终估计。
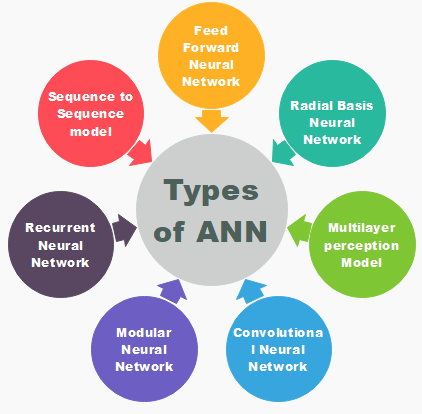
神经网络类型
神经网络的函数与人类神经系统的函数相同。有几种类型的神经网络。这些网络实现基于确定输出所需的参数集和数学运算。
来源:LearnFk无涯教程网
人工神经元
FNN 是ANN的最纯粹形式,其中输入和数据仅在一个方向上传播。数据沿唯一的正向流动;这就是为什么它被称为前馈神经网络的原因。数据通过输入节点,然后从输出节点退出。节点不是周期性连接的。它不需要具有隐藏层。在FNN中,不需要多层。它也可以具有单层。
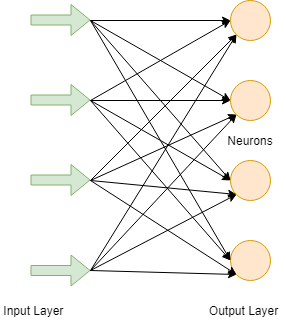
它具有通过使用分类激活函数实现的前传播波。所有其他类型的神经网络都使用反向传播,但FNN不能。在FNN中,计算产品输入和重量的总和,然后将其输入到输出中。 FNN使用了诸如人脸识别和计算机视觉之类的技术。
径向基函数神经网络
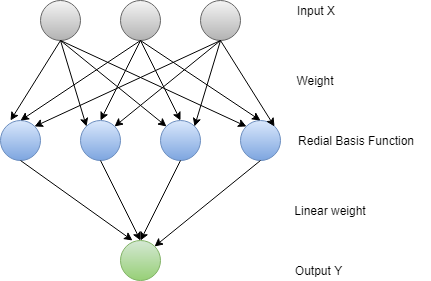
RBFNN 找到一个点到中心的距离,并认为它可以平稳地工作。 RBF神经网络有两层。在内层中,特征与径向基函数结合在一起。函数部件提供了考虑使用的输出。除了欧几里得之外,还可以使用其他措施。
径向基函数
- 定义了一个受体t。
- 在受体周围绘制了面对面的映射。
- 对于RBF,通常使用高斯函数。因此,可以定义径向距离 r = || X-t || 。
Redial Function=Φ(r) = exp (- r2/2σ2), where σ > 0
该神经网络用于电源恢复系统。在当前时代,电力系统的尺寸和复杂性已经增加。这两个因素都会增加重大停电的风险。停电后,需要尽快,可靠地恢复电源。
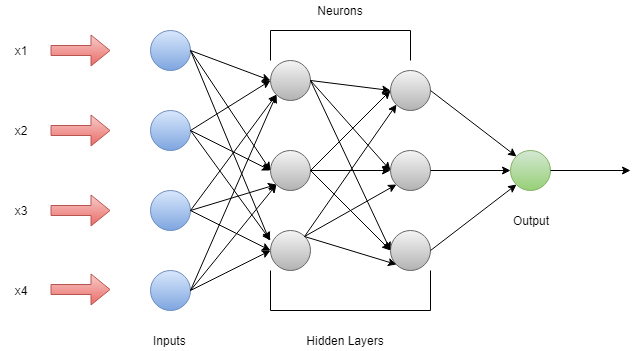
多层的感觉器
多层感知器具有三层或更多层。借助该网络可以对无法线性分离的数据进行分类。此网络是完全连接的网络,这意味着每个单个节点都与下一层中的所有其他节点连接。多层感知器中使用了非线性激活函数。它的输入和输出层节点被连接为有向图。这是一种深度学习方法,因此在训练网络时会使用反向传播。它被广泛应用于语音识别和机器翻译技术中。
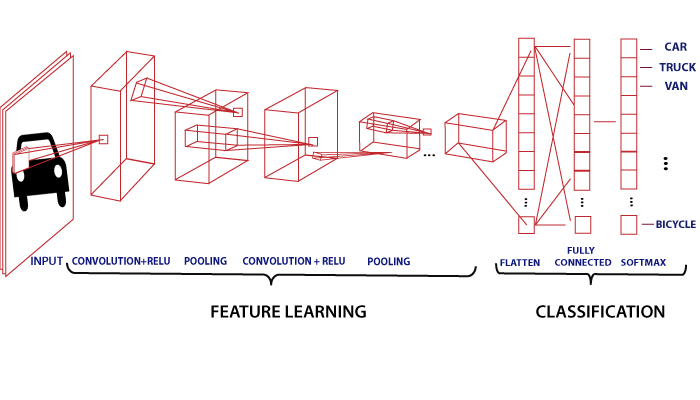
卷积神经网络
在图像分类和图像识别中,卷积神经网络起着至关重要的作用,或者无涯教程可以说它是这些的主要类别。人脸识别,物体检测等是CNN广泛使用的一些领域。它类似于FNN,神经元中有可学习的权重和偏差。
CNN将图像作为输入,并根据特定类别(例如狗,猫,狮子,老虎等)进行分类和处理。众所周知,计算机将图像视为像素,并且取决于图像的分辨率。基于图像分辨率,它将看到h * w * d,其中h =高度w =宽度,d =尺寸。例如,RGB图像是矩阵的6 * 6 * 3阵列,而灰度图像是图案的4 * 4 * 3阵列。
在CNN中,每个输入图像都会经过一系列卷积层以及池化,完全连接的层,过滤器(也称为内核)。并应用Soft-max函数对概率值为0和1的对象进行分类。
递归神经网络
递归神经网络基于预测。在该神经网络中,将保存特定层的输出并将其反馈给输入。这将有助于预测该层的结果。在递归神经网络中,以与FNN的层相同的方式形成第一层,在随后的层中,递归神经网络过程开始。
输入和输出都彼此独立,但在某些情况下,它需要预测句子的下一个单词。
然后,它将取决于句子的前一个单词。 RNN以其主要也是最重要的函数而闻名,即隐藏状态。隐藏状态会记住有关序列的信息。
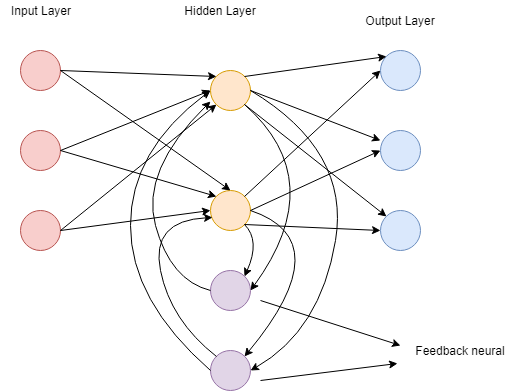
RNN具有一个内存,用于存储计算后的结果。 RNN 在每个输入上使用相同的参数,以对所有隐藏层或数据执行相同的任务以产生输出。与其他神经网络不同,RNN参数的复杂度更低。
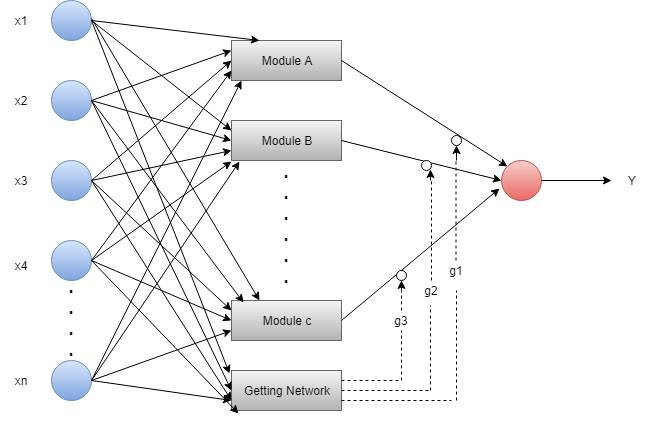
模块化神经网络
在模块化神经网络中,几个不同的网络在函数上是独立的。在MNN中,任务分为子任务,并由多个系统执行。在计算过程中,网络不会直接相互通信。所有接口都独立工作以实现输出。组合网络比固定网络和不受限制的网络更强大。中介负责每个系统的生产,对其进行处理以产生最终输出。
序列到序列网络
它由两个递归神经网络组成。在此,编码器处理输入,解码器处理输出。编码器和解码器可以使用相同或不同的参数。
序列到序列模型被应用于聊天机器人,机器翻译和问题解答系统中。
神经网络组成
神经元
神经元类似于生物学神经元。神经元不过是激活函数。人工神经元或激活函数在执行分类任务时具有“打开”特性。可以说什么时候输入高于特定值;输出应更改状态,即0到1,-1到1等。S型函数是人工神经网络中常用的激活函数。
F(Z)= 1/1 + EXP(-Z)
节点数
生物神经元在分层网络中连接,其中一些神经元的输出是对他人的输入。这些网络表示为连接的节点层。每个节点采用多个加权输入,并将其应用于这些输入的求和并生成输出。
偏差
在神经网络中,根据给定的输入(x)预测输出(y)。创建一个模型(mx + c),以帮助预测输出。当训练模型时,它会找到常数m和c本身的适当值。
常数c是偏差。偏差以最适合给定数据的方式帮助模型。可以说偏差赋予了最佳表现的自由。
算法
神经网络需要算法。生物神经元具有自理解和工作能力,但是人工神经元将如何以相同的方式工作?为此,有必要训练人工神经元网络。为此,使用了许多算法。每种算法都有不同的工作方式。
ANN训练中使用了五种算法
- 梯度下降
- 牛顿法
- 共轭梯度
- 拟牛顿法
- 马夸尔特法
梯度下降
梯度下降算法也称为最速下降算法。这是最简单的算法,需要来自梯度向量的信息。 GD算法是一阶方法。
为简单起见,无涯教程表示ƒ(w (i)) = ƒ(i) 和∇ƒ (w (i)) = g (i) 。该方法从w (0)开始,从 w (i) 移到 w (i + 1) ,沿训练方向 d (i) =- g (i) 满足停止条件。
因此,梯度下降方法按以下方式进行迭代。
w (i + 1) = w (i) - g (i) n (i) 。
牛顿法
牛顿法是一种二阶算法。它利用了Hessian矩阵。它的主要任务是通过使用损失函数的二阶导数找到更好的训练方向。
牛顿法迭代如下。
w (i + 1) = w (i) - h (i) -1 。 g (i) i = 0,1 .....
在这里,H (i)-1 .g (i)被称为牛顿法。参数的更改可能会朝着最大而不是最小的方向发展。下面是用牛顿法训练神经网络的示意图。通过获得训练方向和合适的训练速率来进行参数的改进。
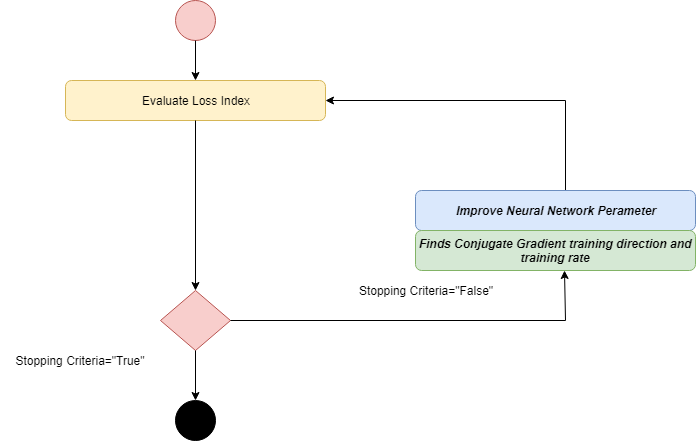
共轭梯度
共轭梯度在梯度下降和牛顿法之间起作用。共轭梯度避免了牛顿方法要求的与评估,Hessian矩阵求逆和存储相关的信息需求。
在CG算法中,搜索是在共轭方向进行的,共轭方向的收敛速度比梯度下降方向快。训练是在关于Hessian矩阵的共轭方向上完成的。通过计算共轭训练方向,然后计算该方向上的合适训练率,可以对参数进行改进。
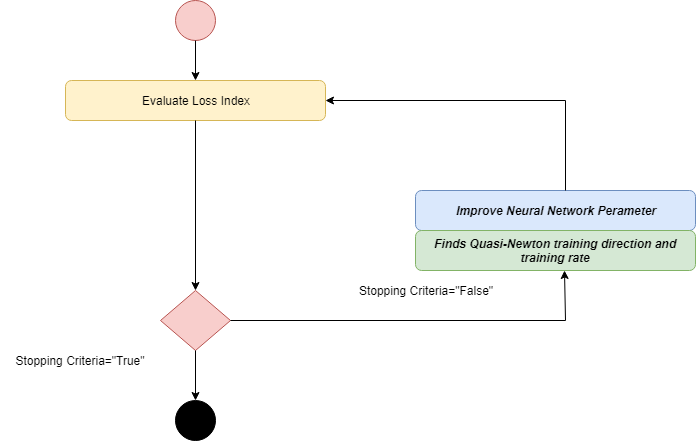
拟牛顿法
牛顿法的应用在计算方面是昂贵的。要评估Hessian矩阵,需要执行许多操作。为了解决该缺点,开发了拟牛顿法。也称为可变矩阵方法。在算法的每次迭代中,它都建立了逆粗麻布的近似值,而不是直接计算粗麻布。有关损失函数的一阶导数的信息用于计算近似值。
通过获得准牛顿训练方向来进行参数的改进,然后找到令人满意的训练率。
马夸尔特法
Levenberg Marquardt也被称为阻尼最小二乘法。该算法专门设计用于损失函数。该算法不计算Hessian矩阵。它与雅可比矩阵和梯度向量一起使用。
在Levenberg Marquardt中,第一步是找到损失,梯度和Hessian近似值,然后调整饺子参数。
祝学习愉快!(内容编辑有误?请选中要编辑内容 -> 右键 -> 修改 -> 提交!)